mirror of https://github.com/alibaba/easyexcel
2 changed files with 3 additions and 100 deletions
@ -1,53 +0,0 @@ |
|||||||
# easyexcel要去解决的问题 |
|
||||||
|
|
||||||
## Excel读写时候内存溢出 |
|
||||||
|
|
||||||
虽然POI是目前使用最多的用来做excel解析的框架,但这个框架并不那么完美。大部分使用POI都是使用他的userModel模式。userModel的好处是上手容易使用简单,随便拷贝个代码跑一下,剩下就是写业务转换了,虽然转换也要写上百行代码,相对比较好理解。然而userModel模式最大的问题是在于非常大的内存消耗,一个几兆的文件解析要用掉上百兆的内存。现在很多应用采用这种模式,之所以还正常在跑一定是并发不大,并发上来后一定会OOM或者频繁的full gc。 |
|
||||||
|
|
||||||
## 其他开源框架使用复杂 |
|
||||||
|
|
||||||
对POI有过深入了解的估计才知道原来POI还有SAX模式。但SAX模式相对比较复杂,excel有03和07两种版本,两个版本数据存储方式截然不同,sax解析方式也各不一样。想要了解清楚这两种解析方式,才去写代码测试,估计两天时间是需要的。再加上即使解析完,要转换到自己业务模型还要很多繁琐的代码。总体下来感觉至少需要三天,由于代码复杂,后续维护成本巨大。 |
|
||||||
|
|
||||||
## 其他开源框架存在一些BUG修复不及时 |
|
||||||
|
|
||||||
由于我们的系统大多数都是大并发的情况下运行的,在大并发情况下,我们会发现poi存在一些bug,如果让POI团队修复估计遥遥无期了。所以我们在easyexcel对这些bug做了规避。 |
|
||||||
如下一段报错就是在大并发情况下poi抛的一个异常。 |
|
||||||
``` |
|
||||||
Caused by: java.io.IOException: Could not create temporary directory '/home/admin/dio2o/.default/temp/poifiles' |
|
||||||
at org.apache.poi.util.DefaultTempFileCreationStrategy.createTempDirectory(DefaultTempFileCreationStrategy.java:93) ~[poi-3.15.jar:3.15] |
|
||||||
at org.apache.poi.util.DefaultTempFileCreationStrategy.createPOIFilesDirectory(DefaultTempFileCreationStrategy.java:82) ~[poi-3.15.jar:3.15] |
|
||||||
``` |
|
||||||
报错地方poi源码如下 |
|
||||||
``` |
|
||||||
private void createTempDirectory(File directory) throws IOException { |
|
||||||
if (!(directory.exists() || directory.mkdirs()) || !directory.isDirectory()) { |
|
||||||
throw new IOException("Could not create temporary directory '" + directory + "'"); |
|
||||||
} |
|
||||||
} |
|
||||||
``` |
|
||||||
仔细看代码容易明白如果在并发情况下,如果2个线程同时判断directory.exists()都 为false,但执行directory.mkdirs()如果一些线程优先执行完,另外一个线程就会返回false。最终 throw new IOException("Could not create temporary directory '" + directory + "'")。针对这个问题easyexcel在写文件时候首先创建了该临时目录,避免poi在并发创建时候引起不该有的报错。 |
|
||||||
|
|
||||||
## Excel格式分析格式分析 |
|
||||||
|
|
||||||
- xls是Microsoft Excel2007前excel的文件存储格式,实现原理是基于微软的ole db是微软com组件的一种实现,本质上也是一个微型数据库,由于微软的东西很多不开源,另外也已经被淘汰,了解它的细节意义不大,底层的编程都是基于微软的com组件去开发的。 |
|
||||||
- xlsx是Microsoft Excel2007后excel的文件存储格式,实现是基于openXml和zip技术。这种存储简单,安全传输方便,同时处理数据也变的简单。 |
|
||||||
- csv 我们可以理解为纯文本文件,可以被excel打开。他的格式非常简单,解析起来和解析文本文件一样。 |
|
||||||
|
|
||||||
## 核心原理 |
|
||||||
|
|
||||||
写有大量数据的xlsx文件时,POI为我们提供了SXSSFWorkBook类来处理,这个类的处理机制是当内存中的数据条数达到一个极限数量的时候就flush这部分数据,再依次处理余下的数据,这个在大多数场景能够满足需求。 |
|
||||||
读有大量数据的文件时,使用WorkBook处理就不行了,因为POI对文件是先将文件中的cell读入内存,生成一个树的结构(针对Excel中的每个sheet,使用TreeMap存储sheet中的行)。如果数据量比较大,则同样会产生java.lang.OutOfMemoryError: Java heap space错误。POI官方推荐使用“XSSF and SAX(event API)”方式来解决。 |
|
||||||
分析清楚POI后要解决OOM有3个关键。 |
|
||||||
|
|
||||||
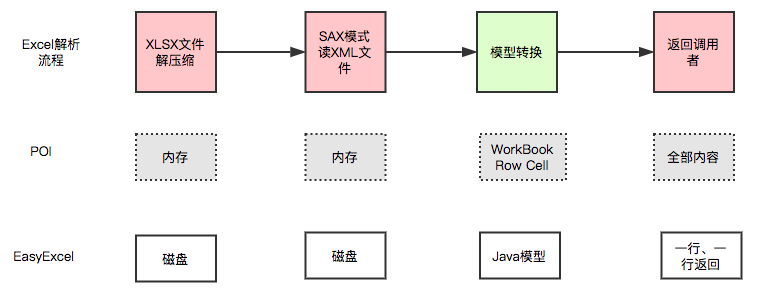
### 1、文件解压文件读取通过文件形式 |
|
||||||
|
|
||||||
 |
|
||||||
|
|
||||||
### 2、避免将全部全部数据一次加载到内存 |
|
||||||
|
|
||||||
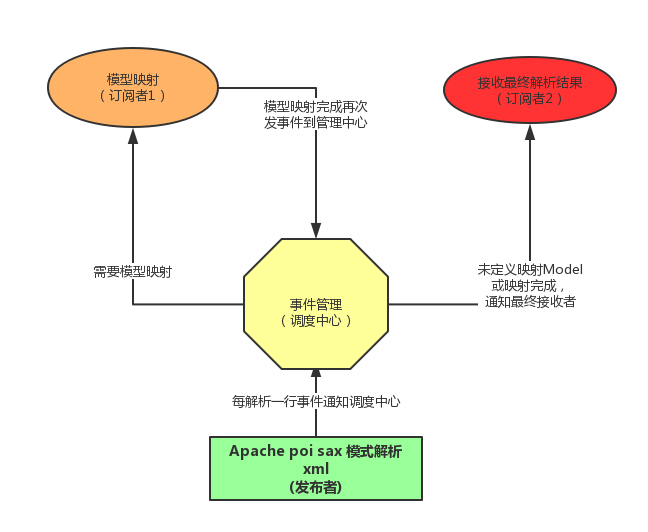
采用sax模式一行一行解析,并将一行的解析结果以观察者的模式通知处理。 |
|
||||||
 |
|
||||||
|
|
||||||
### 3、抛弃不重要的数据 |
|
||||||
|
|
||||||
Excel解析时候会包含样式,字体,宽度等数据,但这些数据是我们不关心的,如果将这部分数据抛弃可以大大降低内存使用。Excel中数据如下Style占了相当大的空间。 |
|
||||||
Loading…
Reference in new issue