the flag got introduced in regress 0.5.0
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
This Pull Request fixes/closes: n/a.
It changes the following:
- add test for unicode flag
- add test for native error on failing to parse (got removed in #2651 because the previous example parsing correctly now)
Co-authored-by: Lauren N. Liberda <lauren@selfisekai.rocks>
Bumps [regress](https://github.com/ridiculousfish/regress) from 0.4.1 to 0.5.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/ridiculousfish/regress/releases">regress's releases</a>.</em></p>
<blockquote>
<h2>v0.5.0</h2>
<p>Version 0.5.0 of regress, REGex in Rust with EmcaScript Syntax.</p>
<ul>
<li>Unicode property escape matching like <code>\p{Letter}</code> is implemented</li>
<li>Regex parsing may now use any u32 iterator, not simply strings</li>
<li>The Unicode flag "u" is now recognized. Unicode is no longer the default; however non-Unicode regular expression support still has some known differences from JavaScript.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="ee710e577f"><code>ee710e5</code></a> Remove language about unicode property escapes being unimplemented</li>
<li><a href="8349a8569e"><code>8349a85</code></a> Bump version to 0.5 in preparation for release</li>
<li><a href="60d4f7b595"><code>60d4f7b</code></a> Update the unicode tables for Unicode 15</li>
<li><a href="603833d432"><code>603833d</code></a> Add test for escaping unrecognised chars</li>
<li><a href="f06b2b3ce1"><code>f06b2b3</code></a> Allow all punctuations to be escaped</li>
<li><a href="7443e66ccc"><code>7443e66</code></a> Update hashbrown requirement from 0.12.0 to 0.13.2</li>
<li><a href="ac59d90fd0"><code>ac59d90</code></a> rustfmt classicalbacktrack.rs</li>
<li><a href="cceb877af2"><code>cceb877</code></a> [non-unicode] less strict QuantifierPrefix parsing</li>
<li><a href="0ca4b596ca"><code>0ca4b59</code></a> to2021, simplfy some code.</li>
<li><a href="d076e06315"><code>d076e06</code></a> parse unbalanced right brackets as a literal bracket, if not using unicode flag</li>
<li>Additional commits viewable in <a href="https://github.com/ridiculousfish/regress/compare/v0.4.1...v0.5.0">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
Co-authored-by: raskad <32105367+raskad@users.noreply.github.com>
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
This Pull Request addresses the broken `cargo clippy` lints that is currently causing CI to fail.
This PR migrates our entire test suite to our new testing API.
It changes the following:
- Migrates tests to new test API.
- Cleans up the API to be a bit more descriptive and maintainable.
- Prettifies our test failure display to show the failed scripts.
- Splits our massive `tests.rs` file into smaller sub-suites.
Example output of a failing test:
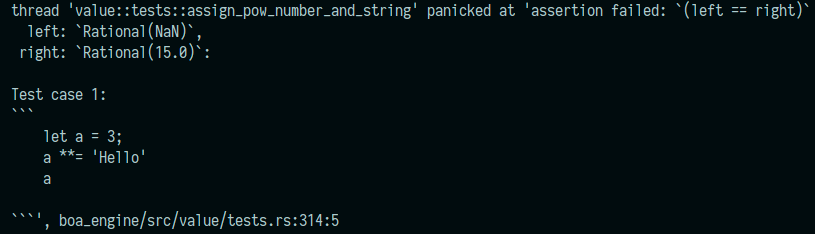
Keep Integer type after running unary increment/decrement ops if possible. The integer type will be useful to take fast paths for accessing index properties. (e.g., `let a = 1; arr[++a]`)
~~Builds off of #2529.~~ Merged.
This Pull Request allows passing any function returning `impl Future<Output = JsResult<JsValue>>` to the `NativeFunction` constructor, allowing native concurrency hooks into the engine.
It changes the following:
- Adds a `NativeFunction::from_async_fn` function.
- Adds a new `JobQueue::enqueue_future_job` method.
- Adds an example usage on `boa_examples`.
Similar to #2604, `GetPropertyByName`/`SetPropertyByName` has only string property key. So, we can skip index and utf16 conversions.
This improves QuickJS benchmark score 5.8% on average.
Richards: 37.0 -> 41.2
DeltaBlue: 38.1 -> 41.4
Crypto: 59.6 -> 59.8
RayTrace: 146 -> 159
EarleyBoyer: 138 -> 142
Splay: 104 -> 106
NavierStokes: 10.2 -> 10.3
This Pull Request closes#1907.
It changes the following:
- Implement several early errors relating to labels, `break` and `continue` in the parser.
- Implement an early error for invalid cover grammar of object literals in the parser.
- Remove all remaining syntax errors from the bytecompiler.
This Pull Request fixes#2605.
It changes the following:
- Adds a CI check to run `cargo test --doc` since `nextest` doesn't support doc tests at the moment.
- Fixes the failing doc tests.
When a rust string literal is given for a property key, boa checks if it can be parsed as an index and converts the string into a utf16 slice. This PR rewrites each hard-coded property key as a utf16 slice so that we can bypass those conversions at runtime.
This improves QuickJS benchmark score 5% on average.
Richards: 35.4 -> 37.0
DeltaBlue: 35.0 -> 38.1
Crypto: 57.6 -> 59.6
RayTrace: 137 -> 146
EarleyBoyer: 131 -> 138
Splay: 98.3 -> 104
NavierStokes: 10.2 -> 10.2
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
This Pull Request is meant to address #1900. While working on it, there was a decent amount of refactoring/restructuring. Initially, I had kept with the current approach of just keeping track of a kind and counter on the environment stack, especially because that kept the size of each stack entry to a minimum.
I did, however, make a switch to having the opcode create the `EnvStackEntry` with a start address and exit address for a bit more precision.
It changes the following:
- Consolidates `loop_env_stack` and `try_env_stack` into one `EnvStackEntry` struct.
- Changes `Continue`, `Break`, `LoopStart`, `LoopContinue`, `FinallyStart`, `FinallyEnd` and various others. Most of this primarily revolves around the creating of `EnvStackEntry` and interacting with the `env_stack`.
- Changes/updates the try-catch-finally, break and continue statement compilations as necessary
- Adds an `AbruptCompletionRecord` in place of the `finally_jump` vector.
- Adds some tests for try-catch-finally blocks with breaks.
I'm creating this draft PR, since I wanted to have some early feedback, and because I though I would have time to finish it last week, but I got caught up with other stuff. Feel free to contribute :)
The main thing here is that I have divided `eval()`, `parse()` and similar functions so that they can decide if they are parsing scripts or modules. Let me know your thoughts.
Then, I was checking the import & export parsing, and I noticed we are using `TokenKind::Identifier` for `IdentifierName`, so I changed that name. An `Identifier` is an `IdentifierName` that isn't a `ReservedWord`. This means we should probably also adapt all `IdentifierReference`, `BindingIdentifier` and so on parsing. I already created an `Identifier` parser.
Something interesting there is that `await` is not a valid `Identifier` if the goal symbol is `Module`, as you can see in the [spec](https://tc39.es/ecma262/#prod-LabelIdentifier), but currently we don't have that information in the `InputElement` enumeration, we only have `Div`, `RegExp` and `TemplateTail`. How could we approach this?
Co-authored-by: jedel1043 <jedel0124@gmail.com>
Hi,
the `vm-implied` fuzzer panics when executing this testcase:
```javascript
try {
new function() {
while (this) {}
}();
} catch {
}
```
`internal error: entered unreachable code: The NoInstructionsRemain native error cannot be converted to an opaque type`
Handling the `NoInstructionsRemain` error upfront instead of going through the VM exception handling logic seems to work.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
Adding a feature flag to the console import in `builtins`. I think this should fix the failing action on the `Upload docs and run benchmarks` step
This Pull Request changes the following:
- Implement binary `in` operation with private names.
- Adding a separate `BinaryInPrivate` expression in addition to the existing `Binary` expression seems like the best way to implement this in a typesafe manner. Other methods like adding an enum for the `Binary` lhs result in having to make assertions.
Small (ish?) step towards having proper realm records
This PR changes the following:
- Moves `Intrinsics` to `Realm`.
- Cleans up the initialization logic of our intrinsics to not depend on `Context`, unblocking things like #2314.
- Adds hooks to initialize the global object and the global this per the corresponding [`InitializeHostDefinedRealm ( )`](https://tc39.es/ecma262/#sec-initializehostdefinedrealm) hook. Though, this is currently broken because the vm uses `GlobalPropertyMap` instead of the `JsObject` API to initialize global properties.
This Pull Request changes the following:
- Move postfix/prefix increment and decrement operations from the `Unary` expression to a new `Update` expression.
- Add a special type for the `Update` expression target as it is very limited in comparision to an `Unary` target.
- This makes bytecode compilation more typesafe for these operations and removes syntax errors from the bytecompiler without introducing panics (see #1907).
Another change extracted from #2411.
This PR changes the following:
- Improves our identifier parsing with a new `Identifier` parser that unifies parsing for `IdentifierReference`, `BindingIdentifier` and `LabelIdentifier`.
- Slightly improves some error messages.
- Extracts our manual initialization of static `Sym`s with a new `static_syms` proc macro.
- Adds `set_module_mode` and `module_mode` to the cursor to prepare for modules.
Slightly related to #2411 since we need an API to pass module files, but more useful for #1760, #1313 and other error reporting issues.
It changes the following:
- Introduces a new `Source` API to store the path of a provided file or `None` if the source is a plain string.
- Improves the display of `boa_tester` to show the path of the tests being run. This also enables hyperlinks to directly jump to the tested file from the VS terminal.
- Adjusts the repo to this change.
Hopefully, this will improve our error display in the future.
Currently the compilation of assignment operators leads to a double object property access, both on the get and set access.
While this refactor adds special access handling instead of using the existing `access_set` and `access_get` functions, it fixes the double access and should also make the resulting code more efficient.
This Pull Request changes the following:
- Remove wrong early errors for static class methods with the computed property name `prototype`.
- Switch static class method definition opcodes from `__define_own_property__` to `define_property_or_throw` to correctly throw runtime errors on property redefinitions.
When compiling a statement list we need to make sure that the last expression that returns a value is compiled with the `use_expr` flag. Currently we set `use_expr` on the last statement of the statement list. This leads to incorrect returns when the last statement does not return a value. This PR fixes this by looking up the last value returning expression in a statement list and setting the `use_expr` appropriately.
This PR changes the following:
- Modifies `EphemeronBox` to be more akin to `GcBox`, with its own header, roots and markers. This also makes it more similar to [Racket's](https://docs.racket-lang.org/reference/ephemerons.html) implementation.
- Removes `EPHEMERON_QUEUE`.
- Ephemerons are now tracked on a special `weak_start` linked list, instead of `strong_start` which is where all other GC boxes live.
- Documents all unsafe blocks.
- Documents our current garbage collection algorithm. I hope this'll clarify a bit what exactly are we doing on every garbage collection.
- Renames/removes some functions.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
This Pull Request addresses #2295, and another case that I came across when I was adding `Break` to the `ByteCompiler`
I did have a question that came up during this regarding the spec. We currently don't implement the [BreakableStatement](https://tc39.es/ecma262/#prod-BreakableStatement). Any thoughts on whether we should be? Especially since `BreakableStatement` seems to be a bit of a inaccurate since `LabelledStatement` is breakable too.
It changes the following:
- Moves handling of label jump out of `compile_block` and into `compile_labelled`.
- Adds a couple more tests to keep track of `LabelledStatement` breaks.
Co-authored-by: Ness <Kevin.Ness@Staples.com>
Follows from #2528, and should complement #2411 to implement the module import hooks.
~~Similarly to the Intl/ICU4X PR (#2478), this has a lot of trivial changes caused by the new lifetimes. I thought about passing the queue and the hooks by value, but it was very painful having to wrap everything with `Rc` in order to be accessible by the host.
In contrast, `&dyn` can be easily provided by the host and has the advantage of not requiring additional allocations, with the downside of adding two more lifetimes to our `Context`, but I think it's worth.~~ I was able to unify all lifetimes into the shortest one of the three, making our API just like before!
Changes:
- Added a new `HostHooks` trait and a `&dyn HostHooks` field to `Context`. This allows hosts to implement the trait for their custom type, then pass it to the context.
- Added a new `JobQueue` trait and a `&dyn JobQueue` field to our `Context`, allowing custom event loops and other fun things.
- Added two simple implementations of `JobQueue`: `IdleJobQueue` which does nothing and `SimpleJobQueue` which runs all jobs until all successfully complete or until any of them throws an error.
- Modified `boa_cli` to run all jobs until the queue is empty, even if a job returns `Err`. This also prints all errors to the user.
The section about `Symbol` on the [specification](https://tc39.es/ecma262/#sec-ecmascript-language-types-symbol-type) says:
> The Symbol type is the set of all non-String values that may be used as the key of an Object property ([6.1.7](https://tc39.es/ecma262/#sec-object-type)).
Each possible Symbol value is unique and immutable.
Our previous implementation of `JsSymbol` used `Rc` and a thread local `Cell<usize>`. However, this meant that two different symbols in two different threads could share the same hash, making symbols not unique.
Also, the [GlobalSymbolRegistry](https://tc39.es/ecma262/#table-globalsymbolregistry-record-fields) is meant to be shared by all realms, including realms that are not in the same thread as the main one; this forces us to replace our current thread local global symbol registry with a thread-safe one that uses `DashMap` for concurrent access. However, the global symbol registry uses `JsString`s as keys and values, which forces us to either use `Vec<u16>` instead (wasteful and needs to allocate to convert to `JsString` on each access) or make `JsString` thread-safe with an atomic counter. For this reason, I implemented the second option.
This PR changes the following:
- Makes `JsSymbol` thread-safe by using Arc instead of Rc, and making `SYMBOL_HASH_COUNT` an `AtomicU64`.
- ~~Makes `JsString` thread-safe by using `AtomicUsize` instead of `Cell<usize>` for its ref count.~~ EDIT: Talked with @jasonwilliams and we decided to use `Box<[u16]>` for the global registry instead, because this won't penalize common usage of `JsString`, which is used a LOT more than `JsSymbol`.
- Makes the `GLOBAL_SYMBOL_REGISTRY` truly global, using `DashMap` as our global map that is shared by all threads.
- Replaces some thread locals with thread-safe alternatives, such as static arrays and static indices.
- Various improvements to all related code for this.
This Pull Request changes the following:
- Do not skip consecutive semicolons while parsing a `StatementList`.
- Expect semicolon in `LexicalDeclaration` and add an special case for `for` loop parsing.
- Adjust `StatementList` compilation to skip empty statements.
- Adjust/add tests to make sure consecutive semicolons are correctly parsed.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
Some small changes to the VM with the hopes of making it a bit more clear and concise.
It changes the following:
- Changes `code` to `code_block` and `code` to `bytecode` in `CallFrame` and `CodeBlock`, respectively.
- Adds some creation methods to `CallFrame`.
- Implements `Default` for `Vm`.
This Pull Request fixes various bugs related to classes.
The biggest changes are:
- Changed private names to be unique across multiple classes.
- Changed private name resolution to work via a visitor after a class is parsed. The way class early errors are defined makes it impossible to perform private name resolution while parsing.
- Added function names to class methods.
- Added class name binding to method function environments.
- Separated opcodes for `static` and non-`static` class method definitions to make the above operations possible.
There are still some bugs and further issues with classes but this is already a lot.
As part of the new modules PR, I was working on implementing the [host hooks](https://tc39.es/ecma262/#sec-host-hooks-summary) for the module import hooks and custom job queues. However, the promises module needed a bit of a refactor in order to couple with the new API. So, I thought it was a good idea to separate the promises refactor into its own PR, since the other PR is already big as it is.
- Replaced some usages of `JobCallback` with a new `NativeJob` that isn't traced by the GC, since those closures are always rooted and executed by the `Context` globally. This will also allow hosts to pass their custom jobs to the job queue, and maybe could also accept futures in the Future (pun intended 😆).
- Refactored several functions to account for the `HostPromiseRejectionTracker` hook which needs the promise `JsObject`.
- Rewrote some patterns with newer Rust idioms.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
Hi all! 😄
This Pull Request addresses #2424. There are also a few changes made to the `ByteCompiler`, the majority of which are involving `JumpControlInfo`.
It changes the following:
- Adds `Break` Opcode
- Shifts `compile_stmt` into the `statement` module.
- Moves `JumpControlInfo` to it's own module.
This PR is a complete redesign of our current native functions and closures API.
I was a bit dissatisfied with our previous design (even though I created it 😆), because it had a lot of superfluous traits, a forced usage of `Gc<GcCell<T>>` and an overly restrictive `NativeObject` bound. This redesign, on the other hand, simplifies a lot our public API, with a simple `NativeCallable` struct that has several constructors for each type of required native function.
This new design doesn't require wrapping every capture type with `Gc<GcCell<T>>`, relaxes the trait requirement to `Trace + 'static` for captures, can be reused in both `JsObject` functions and (soonish) host defined functions, and is (in my opinion) a bit cleaner than the previous iteration. It also offers an `unsafe` API as an escape hatch for users that want to pass non-Copy closures which don't capture traceable types.
Would ask for bikeshedding about the names though, because I don't know if `NativeCallable` is the most precise name for this. Same about the constructor names; I added the `from` prefix to all of them because it's the "standard" practice, but seeing the API doesn't have any other method aside from `call`, it may be better to just remove the prefix altogether.
Let me know what you think :)
This Pull Request changes the following:
- Pass a receiver value to the object `get` function in the `GetPropertyBy*` opcodes. The receiver value may be different from the object, because `ToObject` is not called on it.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
This Pull Request fixes/closes #2512 .
Removes `Literal::Undefined` so that `undefined` is treated as an identifier name. Ran the parser's idempotency fuzzer and ensured the bug doesn't reproduce.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
This Pull Request fixes/closes #2416.
Previously, prefix increment and decrement operations on `this` caused a panic. This PR makes the parser issue a syntax error when the operand UnaryExpression is not simple (as mentioned in https://tc39.es/ecma262/#sec-update-expressions-static-semantics-early-errors).
Just a general cleanup of the APIs of our `Context`.
- Reordered the `pub` and `pub(crate)/fn` methods to have a clear separation between our public and private APIs.
- Removed the call method and added it to `JsValue` instead, which semantically makes a bit more sense.
- Removed the `construct_object` method, and added an utility method `new` to `JsObject` instead.
- Rewrote some patterns I found while rewriting the calls of the removed function.
`execute_instruction` is heavily used. After decoding an opcode, `match` is used to find a proper `execute` function for the opcode. But, the `match` may not be able to be optimized into a table jump by rust compiler, so it may use multiple branches to find the function. When I tested with a toy program, only `enum -> &'static str` case was optimized to use a table while `enum -> function call` uses multiple branches. ([gotbolt](https://rust.godbolt.org/z/1rzK5vj6f))
This change makes the opcode to use a table explicitly. It improves the benchmark score of Richards by 1-2% (22.8 -> 23.2).
This Pull Request fixes/closes #1180. (I'll open a tracking issue for the progress)
It changes the following:
- Redesigns the internal API of Intl to (hopefully!) make it easier to implement a service.
- Implements the `Intl.Locale` service.
- Implements the `Intl.Collator` service.
- Implements the `Intl.ListFormat` service.
On the subject of the failing tests. Some of them are caused by missing locale data in the `icu_testdata` crate; we would need to regenerate that with the missing locales, or vendor a custom default data.
On the other hand, there are some tests that are bugs from the ICU4X crate. The repo https://github.com/jedel1043/icu4x-test262 currently tracks the found bugs when running test262. I'll sync with the ICU4X team to try to fix those.
cc @sffc
Per the [Standard Library development guide](https://std-dev-guide.rust-lang.org/code-considerations/performance/inline.html):
> You can add `#[inline]`:
>
> - To public, small, non-generic functions.
>
> You shouldn't need `#[inline]`:
> - On methods that have any generics in scope.
> - On methods on traits that don't have a default implementation.
>
> `#[inline]` can always be introduced later, so if you're in doubt they can just be removed.
This PR follows this guideline to reduce the number of `#[inline]` annotations in our code, removing the annotation in:
- Non-public functions
- Generic functions
- Medium and big functions.
Hopefully this shouldn't impact our perf at all, but let's wait to see the benchmark results.
This Pull Request is currently unfinished but will fix/close #1808 after some review and more work
It changes the following:
- Divides byte compiler logic into separate files
I would like some review on the current code I have to know if the patterns I'm using are acceptable for the codebase, if everything looks good I will try to separate more code into different small modules to finish the work here.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
Submitting this as a draft for feedback/second opinions. This draft contains some changes to the documentation.
Quick Overview:
- Potential `Boa` header for Boa's crates added to `boa_engine`.
- Changes the wording to a lot of module headers (See `builtins` module and `object/builtins` module).
- Updating built-in wrapper's code examples to use `?` operator.
- Adds the doc logo URL to a few crates that didn't have it.
The main idea of this draft is to move away from the "This module implements" wording as it feels a bit duplicative when listed under the Modules section (mainly focusing around changes in `boa_engine` to start).
While working on this, I had a question about whether we should be using JavaScript or ECMAScript in the Boa's documentation. We do seem to currently use both, and this draft uses JavaScript heavily in the wording.
This Pull Request changes the following:
- Remove false early error when a class expression was missing a binding identifier.
- Simplify/fix environment truncation on function returns.
The new failed tests where false positives before that will be fixed in another PR.
{kind=link}