This PR migrates our entire test suite to our new testing API.
It changes the following:
- Migrates tests to new test API.
- Cleans up the API to be a bit more descriptive and maintainable.
- Prettifies our test failure display to show the failed scripts.
- Splits our massive `tests.rs` file into smaller sub-suites.
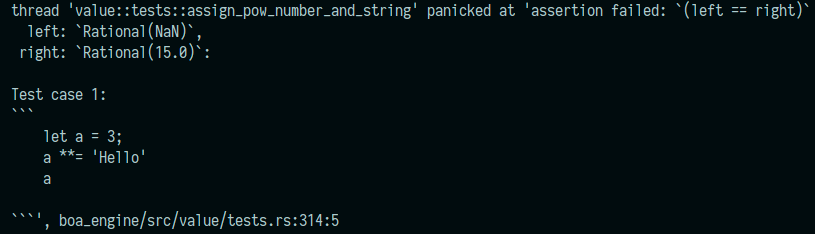
Example output of a failing test:
Similar to #2604, `GetPropertyByName`/`SetPropertyByName` has only string property key. So, we can skip index and utf16 conversions.
This improves QuickJS benchmark score 5.8% on average.
Richards: 37.0 -> 41.2
DeltaBlue: 38.1 -> 41.4
Crypto: 59.6 -> 59.8
RayTrace: 146 -> 159
EarleyBoyer: 138 -> 142
Splay: 104 -> 106
NavierStokes: 10.2 -> 10.3
When a rust string literal is given for a property key, boa checks if it can be parsed as an index and converts the string into a utf16 slice. This PR rewrites each hard-coded property key as a utf16 slice so that we can bypass those conversions at runtime.
This improves QuickJS benchmark score 5% on average.
Richards: 35.4 -> 37.0
DeltaBlue: 35.0 -> 38.1
Crypto: 57.6 -> 59.6
RayTrace: 137 -> 146
EarleyBoyer: 131 -> 138
Splay: 98.3 -> 104
NavierStokes: 10.2 -> 10.2
I'm creating this draft PR, since I wanted to have some early feedback, and because I though I would have time to finish it last week, but I got caught up with other stuff. Feel free to contribute :)
The main thing here is that I have divided `eval()`, `parse()` and similar functions so that they can decide if they are parsing scripts or modules. Let me know your thoughts.
Then, I was checking the import & export parsing, and I noticed we are using `TokenKind::Identifier` for `IdentifierName`, so I changed that name. An `Identifier` is an `IdentifierName` that isn't a `ReservedWord`. This means we should probably also adapt all `IdentifierReference`, `BindingIdentifier` and so on parsing. I already created an `Identifier` parser.
Something interesting there is that `await` is not a valid `Identifier` if the goal symbol is `Module`, as you can see in the [spec](https://tc39.es/ecma262/#prod-LabelIdentifier), but currently we don't have that information in the `InputElement` enumeration, we only have `Div`, `RegExp` and `TemplateTail`. How could we approach this?
Co-authored-by: jedel1043 <jedel0124@gmail.com>
Small (ish?) step towards having proper realm records
This PR changes the following:
- Moves `Intrinsics` to `Realm`.
- Cleans up the initialization logic of our intrinsics to not depend on `Context`, unblocking things like #2314.
- Adds hooks to initialize the global object and the global this per the corresponding [`InitializeHostDefinedRealm ( )`](https://tc39.es/ecma262/#sec-initializehostdefinedrealm) hook. Though, this is currently broken because the vm uses `GlobalPropertyMap` instead of the `JsObject` API to initialize global properties.
Slightly related to #2411 since we need an API to pass module files, but more useful for #1760, #1313 and other error reporting issues.
It changes the following:
- Introduces a new `Source` API to store the path of a provided file or `None` if the source is a plain string.
- Improves the display of `boa_tester` to show the path of the tests being run. This also enables hyperlinks to directly jump to the tested file from the VS terminal.
- Adjusts the repo to this change.
Hopefully, this will improve our error display in the future.
The section about `Symbol` on the [specification](https://tc39.es/ecma262/#sec-ecmascript-language-types-symbol-type) says:
> The Symbol type is the set of all non-String values that may be used as the key of an Object property ([6.1.7](https://tc39.es/ecma262/#sec-object-type)).
Each possible Symbol value is unique and immutable.
Our previous implementation of `JsSymbol` used `Rc` and a thread local `Cell<usize>`. However, this meant that two different symbols in two different threads could share the same hash, making symbols not unique.
Also, the [GlobalSymbolRegistry](https://tc39.es/ecma262/#table-globalsymbolregistry-record-fields) is meant to be shared by all realms, including realms that are not in the same thread as the main one; this forces us to replace our current thread local global symbol registry with a thread-safe one that uses `DashMap` for concurrent access. However, the global symbol registry uses `JsString`s as keys and values, which forces us to either use `Vec<u16>` instead (wasteful and needs to allocate to convert to `JsString` on each access) or make `JsString` thread-safe with an atomic counter. For this reason, I implemented the second option.
This PR changes the following:
- Makes `JsSymbol` thread-safe by using Arc instead of Rc, and making `SYMBOL_HASH_COUNT` an `AtomicU64`.
- ~~Makes `JsString` thread-safe by using `AtomicUsize` instead of `Cell<usize>` for its ref count.~~ EDIT: Talked with @jasonwilliams and we decided to use `Box<[u16]>` for the global registry instead, because this won't penalize common usage of `JsString`, which is used a LOT more than `JsSymbol`.
- Makes the `GLOBAL_SYMBOL_REGISTRY` truly global, using `DashMap` as our global map that is shared by all threads.
- Replaces some thread locals with thread-safe alternatives, such as static arrays and static indices.
- Various improvements to all related code for this.
Just a general cleanup of the APIs of our `Context`.
- Reordered the `pub` and `pub(crate)/fn` methods to have a clear separation between our public and private APIs.
- Removed the call method and added it to `JsValue` instead, which semantically makes a bit more sense.
- Removed the `construct_object` method, and added an utility method `new` to `JsObject` instead.
- Rewrote some patterns I found while rewriting the calls of the removed function.
Per the [Standard Library development guide](https://std-dev-guide.rust-lang.org/code-considerations/performance/inline.html):
> You can add `#[inline]`:
>
> - To public, small, non-generic functions.
>
> You shouldn't need `#[inline]`:
> - On methods that have any generics in scope.
> - On methods on traits that don't have a default implementation.
>
> `#[inline]` can always be introduced later, so if you're in doubt they can just be removed.
This PR follows this guideline to reduce the number of `#[inline]` annotations in our code, removing the annotation in:
- Non-public functions
- Generic functions
- Medium and big functions.
Hopefully this shouldn't impact our perf at all, but let's wait to see the benchmark results.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
Submitting this as a draft for feedback/second opinions. This draft contains some changes to the documentation.
Quick Overview:
- Potential `Boa` header for Boa's crates added to `boa_engine`.
- Changes the wording to a lot of module headers (See `builtins` module and `object/builtins` module).
- Updating built-in wrapper's code examples to use `?` operator.
- Adds the doc logo URL to a few crates that didn't have it.
The main idea of this draft is to move away from the "This module implements" wording as it feels a bit duplicative when listed under the Modules section (mainly focusing around changes in `boa_engine` to start).
While working on this, I had a question about whether we should be using JavaScript or ECMAScript in the Boa's documentation. We do seem to currently use both, and this draft uses JavaScript heavily in the wording.
This Pull Request restructures the lint deny/warn/allow lists in `boa_engine`. It adds a lot of documentation to pup functions. There are still a few clippy lints that are not fixed, mainly regarding casting of number types. Fixing those lints effectiveley would in some cases probably require bigger refactors.
This should probably wait for #2449 to be merged, because that PR already fixes that lints regarding the `Date` built-in.
Just a general cleanup of the `Date` builtin to use slightly better patterns and to fix our warnings about deprecated functions.
About the regressed tests. It seems to be a `chrono` bug, so I opened up an issue (https://github.com/chronotope/chrono/issues/884) for it and they've already opened a PR fixing it (https://github.com/chronotope/chrono/pull/885).
However, while checking out the remaining failing tests, I realized there's a more fundamental limitation with the library. Currently, [`chrono`](https://github.com/chronotope/chrono) specifies:
> Date types are limited in about +/- 262,000 years from the common epoch.
While the [ECMAScript spec](https://tc39.es/ecma262/#sec-time-values-and-time-range) says:
> The smaller range supported by a time value as specified in this section is approximately -273,790 to 273,790 years relative to 1970.
The range allowed by the spec is barely outside of the range supported by `chrono`! This is why the remaining `Date` tests fail.
Seeing that, I would like to ping @djc and @esheppa (the maintainers of `chrono`) to ask if it would be feasible to add a feature, akin to the `large-dates` feature from the `time` crate, that expands the supported range of `chrono`.
EDIT: Filed https://github.com/chronotope/chrono/issues/886
Right now our promises print `{ }` on display. This PR improves a bit the display and ergonomics of promises in general. Now, promises will print...
- When pending: `Promise { <pending> }`
- When fulfilled: `Promise { "hi" }`
- When rejected: `Promise { <rejected> ReferenceError: x is not initialized }`
This Pull Request replaces `contains`, `contains_arguments`, `has_direct_super` and `function_contains_super` with visitors. (~1000 removed lines!)
Also, the new visitor implementation caught a bug where we weren't setting the home object of async functions, generators and async generators for methods of classes, which caused a stack overflow on `super` calls, and I think that's pretty cool!
Next is `var_declared_names`, `lexically_declared_names` and friends, which will be on another PR.
This Pull Request closes no specific issue, but allows for analysis and post-processing passes by both internal and external developers.
It changes the following:
- Adds a Visitor trait, to be implemented by visitors of a particular node type.
- Adds `Type`Visitor traits which offer access to private members of a node.
- Adds an example which demonstrates the use of Visitor traits by walking over an AST and printing its contents.
At this time, the PR is more of a demonstration of intent rather than a full PR. Once it's in a satisfactory state, I'll mark it as not a draft.
Co-authored-by: Addison Crump <addison.crump@cispa.de>
This is an experiment that tries to migrate the codebase from eager `Error` objects to lazy ones.
In short words, this redefines `JsResult = Result<JsValue, JsError>`, where `JsError` is a brand new type that stores only the essential part of an error type, and only transforms those errors to `JsObject`s on demand (when having to pass them as arguments to functions or store them inside async/generators).
This change is pretty big, because it unblocks a LOT of code from having to take a `&mut Context` on each call. It also paves the road for possibly making `JsError` a proper variant of `JsValue`, which can be a pretty big optimization for try/catch.
A downside of this is that it exposes some brand new error types to our public API. However, we can now implement `Error` on `JsError`, making our `JsResult` type a bit more inline with Rust's best practices.
~Will mark this as draft, since it's missing some documentation and a lot of examples, but~ it's pretty much feature complete. As always, any comments about the design are very much appreciated!
Note: Since there are a lot of changes which are essentially just rewriting `context.throw` to `JsNativeError::%type%`, I'll leave an "index" of the most important changes here:
- [boa_engine/src/error.rs](https://github.com/boa-dev/boa/pull/2283/files#diff-f15f2715655440626eefda5c46193d29856f4949ad37380c129a8debc6b82f26)
- [boa_engine/src/builtins/error/mod.rs](https://github.com/boa-dev/boa/pull/2283/files#diff-3eb1e4b4b5c7210eb98192a5277f5a239148423c6b970c4ae05d1b267f8f1084)
- [boa_tester/src/exec/mod.rs](https://github.com/boa-dev/boa/pull/2283/files#diff-fc3d7ad7b5e64574258c9febbe56171f3309b74e0c8da35238a76002f3ee34d9)
I think it's time to address the elephant in the room.
This Pull Request will (hopefully!) solve part of #736.
This is a complete rewrite of `JsString`, but instead of storing `u8` bytes it stores `u16` words. The `encode!` macro (renamed to `utf16!` for simplicity) from the `const-utf16` crate allows us to create UTF-16 encoded arrays at compilation time. `JsString` implements `Deref<Target=[u16]>` to unlock the slice methods and possibly make some manipulations easier. However, we would need to create our own library of utilities for `JsString`.
Skip `to_string` for integer type primitives in `to_property_key`. It's unnecessary to convert the integer value to string and convert back to `Index(u32)` type.
In this example code, it improves around 10% of runtime.
```js
let arr = [1,2,3,4,5];
for (let i = 0; i < 10000000; i++) {
arr[0] = 123;
}
```
Before: 6.24s
After: 5.38s
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel neccesary.
--->
This Pull Request fixes#1615.
It changes the following:
- Removes the `Trace` implementation from types that don't need it (except for `JsSymbol` and `JsString`, which are needed elsewere).
- Uses `#[unsafe_ignore_trace]` in places where we need to implement `Trace` for part of a structure.
- Implements a custom `Trace` in enums where deriving it is not possible, since `#[unsafe_ignore_trace]` doesn't work for enums.
Co-authored-by: raskad <32105367+raskad@users.noreply.github.com>
This PR fixes the length/index types from `usize` to `u64`, because in JavaScript the length can be from `0` to `2^53 - 1` it cannot be represented in a `usize`. On `64-bit` architectures this is fine because it is already a unsigned 64bit number and these changes essentially do nothing. But on 32bit architectures this was causing the length to be truncated giving an unexpected result.
fixes/closes #2182
It changes the following:
- Make length a `u64` to be able to represent all possible length values
- Change `JsValue::to_length()` t return `u64`
- Change `JsValue::to_index()` t return `u64`
This PR adds a safe wrapper around JavaScript `JsSet` from `builtins::set`, and is being tracked at #2098.
Implements following methods
- [x] `Set.prototype.size`
- [x] `Set.prototype.add(value)`
- [x] `Set.prototype.clear()`
- [x] `Set.prototype.delete(value)`
- [x] `Set.prototype.has(value)`
- [x] `Set.prototype.forEach(callbackFn[, thisArg])`
Implement wrapper for `builtins::set_iterator`, to be used by following.
- [x] `Set.prototype.values()`
- [x] `Set.prototype.keys()`
- [x] `Set.prototype.entries()`
*Note: Are there any other functions that should be added?
Also adds `set_create()` and made `get_size()` public in `builtins::set`.
This PR implements an optimization done by V8 and spidermonkey. Which stores indexed properties in two class storage methods dense and sparse. The dense method stores the property in a contiguous array ( `Vec<T>` ) where the index is the property key. This storage method is the default. While on the other hand we have sparse storage method which stores them in a hash map with key `u32` (like we currently do). This storage method is a backup and is slower to access because we have to do a hash map lookup, instead of an array access.
In the dense array we can store only data descriptors that have a value field and are `writable`, `configurable` and `enumerable` (which by default array elements are). Since all the fields of the property descriptor are the same except value field, we can omit them an just store the `JsValue`s in `Vec<JsValue>` this decreases the memory consumption and because it is smaller we are less likely to have cache misses.
There are cases where we have to convert from dense to sparse (the slow case):
- If we insert index elements in a non-incremental way, like `array[1000] = 1000` (inserting an element to an index that is already occupied only replaces it does not make it sparse)
- If we delete from the middle of the array (making a hole), like `delete array[10]` (only converts if there is actualy an element there, so calling delete on a non-existent index property will do nothing)
Once it becomes sparse is *stays* sparse there is no way to convert it again. (the computation needed to check whether it can be converted outweighs the benefits of this optimization)
I did some local benchmarks and on array creation/pop and push there is ~45% speed up and the impact _should_ be bigger the more elements we have. For example the code below on `main` takes `~21.5s` while with this optimization is `~3.5s` (both on release build).
```js
let array = [];
for (let i = 0; i < 50000; ++i) {
array[i] = i;
}
```
In addition I also made `Array::create_array_from_list` do a direct setting of the properties (small deviation from spec but it should have the same behaviour), with this #2058 should be fixed, conversion from `Vec` to `JsArray`, not `JsTypedArray` for that I will work on next :)
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel neccesary.
--->
This Pull Request fixes/closes #1989.
It changes the following:
- Implements From<f32> for JsValue
This Pull Request fixes/closes #1962.
It changes the following:
- When executing arithmetic operations on `JsValue`s, try to use integer operations and fallback to `f64` operations on error.
- Adds tests for serde_json conversions from integer operations.
Fixes `BigInt` and `Number` comparison, and vice versa. Before we were removing the decimal point of the floating-point number which was causing cases like `0.000001 > 0n` (or `0n < 0.000001`) to fail.
Building up to #186, this PR extracts an `Intrinsics` struct from `Context`, facilitating a lot the extraction of a `Realm` struct.
Also, it adapts the `BuiltIn` trait to be useful for builtins that don't expose a global property on initialization (`Generator`, `TypedArray`, etc.)
It changes the following:
- Creates an `Intrinsics` struct and refactors `Context` to transfer its intrinsic related fields to `Intrinsics`.
- Renames some methods and parameters to better describe their functionality.
- Makes `BuiltIn::init` return `Option<JsValue>` to skip global property initialization if the builtin initialization returns `None`
This PR is also related to #577
Changes:
- Implements `IteratorValue` (`IteratorResult::value()`)
- Implements `IteratorComplete` (`IteratorResult::complete()`)
- Implements `IteratorStep` (`IteratorRecord::step()`)
- Makes `IteratorNext` (`IteratorRecord::next()`) spec compliant
- Deprecates/removes `JsValue::get_field()`.
The ECMAScript 2022 specification removes the `toInteger` method, and replaces it with `toIntegerOrInfinity`, which is arguably better for us since the `JsValue::toInteger` returns an `f64`, which is pretty confusing at times.
This pull request removes the `JsValue::to_integer` method, replaces all its calls by `JsValue::to_integer_or_infinity` or others per the spec and documents several methods from the `string` builtin.
This PR adds support for arrays with empty elements e.g. `["", false, , , ]`. Before we were filling the empty places with `undefined`, but this is wrong according to [spec](https://tc39.es/ecma262/#sec-runtime-semantics-arrayaccumulation) there shouldn't be undefined with a index at that place, instead only `length` is incremented. So `[,,,].length == 3` and operations like `[,,,,].indexOf(undefined) == -1`, `[,,,,].lastIndexOf(undefined) == -1` etc.
This PR fixes equality between object and `null` or `undefined` (like `[] == null`), which was failing the test262 harness test [`compare-array-symbol.js`](18ce639a4c/test/harness/compare-array-symbol.js).
This Pull Request is related to #577 .
It changes the following:
- Remove `JsValue::set_field`
- Remove `JsValue::set_property`
- Remove almost all uses of `JsValue::get_field`
- Use `.get_v()` instead of `get_field` according to spec in `serialize_json_property`
- Remove `Array::new_array()`
- Remove `Array::add_to_array_object()`
This Pull Request fixes new lint errors and warnings introduced in rust 1.59
Each commit describes its changse.
Co-authored-by: raskad <32105367+raskad@users.noreply.github.com>
This Pull Request closes#1693.
It changes the following:
- It adds a fallible conversion from `serde_json::Value` to `JsValue`, which requires a context.
- It adds a fallible conversion from `JsValue` to `serde_json::Value`, which requires a context.
- Added examples to the documentation of both methods.
- Removed some duplicate and non-needed code that I found while doing this.
Co-authored-by: RageKnify <RageKnify@gmail.com>
{kind=link}