This Pull Request fixes test [`assert-throws-same-realm.js`](eb44f67274/test/harness/assert-throws-same-realm.js).
It changes the following:
- Handles global variables through the global object, instead of the `context`.
- Adds an `active_function` field to the vm, which is used as the `NewTarget` when certain builtins aren't called with `new`.
- Adds a `realm_intrinsics` field to `Function`.
This PR resolves the failing CI in #2777
It changes the following:
- Adds `json-parse-with-source` feature to `boa_tester`
- Bumps `test262` module to `be0abd9`
This PR implements an optimizer, It currently implements the [constant folding optimization][cfo]. this optimization is responsible for "folding"/evaluating constant expressions.
For example:
```js
let x = ((1 + 2 + -4) * 8) << 4
```
Generates the following instruction(s) (`cargo run -- -t`):
```
000000 0000 PushOne
000001 0001 PushInt8 2
000003 0002 Add
000004 0003 PushInt8 4
000006 0004 Neg
000007 0005 Add
000008 0006 PushInt8 8
000010 0007 Mul
000011 0008 PushInt8 4
000013 0009 ShiftLeft
000014 0010 DefInitLet 0000: 'x'
```
With constant folding it generates the following instruction(s) (`cargo run -- -t -O`):
```
000000 0000 PushInt8 -128
000002 0001 DefInitLet 0000: 'x'
```
It changes the following:
- Implement ~~WIP~~ constant folding optimization, ~~only works with integers for now~~
- Add `--optimize, -O` flag to boa_cli
- Add `--optimizer-statistics` flag to boa_cli for optimizer statistics
- Add `--optimize, -O` flag to boa_tester
After I finish with this, will try to implement other optimizations :)
[cfo]: https://en.wikipedia.org/wiki/Constant_folding
`boa_tester` wasn't deserializing `SpecEdition` correcly. This was because the attribute `serde(untagged)` just removes the u8 tag instead of trying to deserialize as a number. This PR fixes this using the `serde_repr` crate.
This needs #2763 to be merged for it to pass CI.
This Pull Request improves our test results display per edition and cleanups our edition detector logic.
It changes the following:
- Adds a new `edition` flag to limit the maximum edition that will be tested.
- Adds a new `versioned` flag to display all tested editions in a table.
- Adds utility methods to `SpecEdition` to detect the edition of a test and get all the available editions.
- Cleanups logic.
Output with this PR ~(We only collect ES5, ES6 and ES13 stats, so all other editions are a WIP)~:
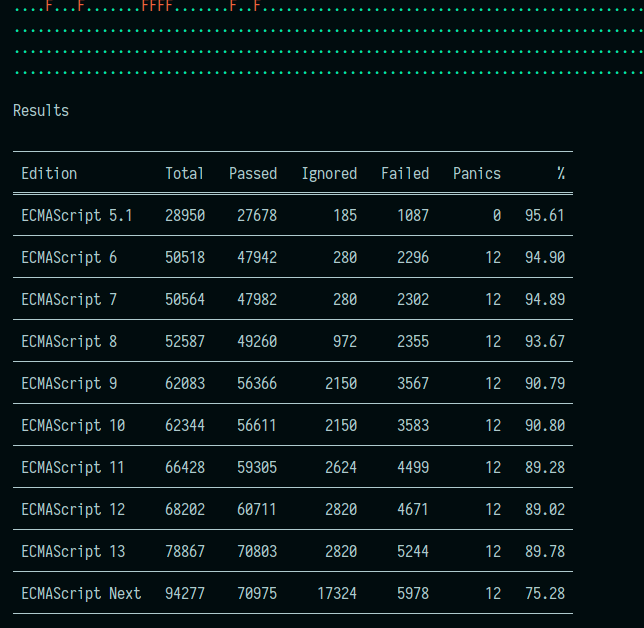
~Marking as a draft since I need to determine the version of the remaining features, but feel free to review everything else.~ Finished!
This is calculated based the tests `es5id` or `es6id`.
Judging by [this](https://github.com/tc39/test262/issues/1557) it's probably not the best method of doing it, but the alternative would require a lot of rework on the boa_tester so that it can pull an older version of the test262 spec which has it's own problems since there's not really an "ES5" only version.
I would think that if we're 100% passing on es5id's then it's safe to assume boa supports es5 (assuming test262's es5id is covering all the es5 cases)
This Pull Request fixes/closes #2629.
It changes the following:
- Store `spec_version` in TestResult based on the tests `es[6/5]id`
- Count all es5, es6 and their test outcome during `TestSuite::run()`
- Print the conformance.
I'm serializing the `spec_version` outcomes so that it can be displayed in test262 github page. I'd like to work on that too if possible. Let me know if there's anything more I should cover in this PR, I'll gladly do it :)
Co-authored-by: jedel1043 <jedel0124@gmail.com>
So, while working on #2658 I apparently broke 1280 tests... except I didn't! Turns out we were considering async tests that didn't call the `print` function as passed tests, but the `async` section of https://github.com/tc39/test262/blob/main/INTERPRETING.md#flags says:
> The test must not be considered complete until the implementation-defined print function has been invoked or some length of time has passed without any such invocation.
I'm creating this draft PR, since I wanted to have some early feedback, and because I though I would have time to finish it last week, but I got caught up with other stuff. Feel free to contribute :)
The main thing here is that I have divided `eval()`, `parse()` and similar functions so that they can decide if they are parsing scripts or modules. Let me know your thoughts.
Then, I was checking the import & export parsing, and I noticed we are using `TokenKind::Identifier` for `IdentifierName`, so I changed that name. An `Identifier` is an `IdentifierName` that isn't a `ReservedWord`. This means we should probably also adapt all `IdentifierReference`, `BindingIdentifier` and so on parsing. I already created an `Identifier` parser.
Something interesting there is that `await` is not a valid `Identifier` if the goal symbol is `Module`, as you can see in the [spec](https://tc39.es/ecma262/#prod-LabelIdentifier), but currently we don't have that information in the `InputElement` enumeration, we only have `Div`, `RegExp` and `TemplateTail`. How could we approach this?
Co-authored-by: jedel1043 <jedel0124@gmail.com>
Small (ish?) step towards having proper realm records
This PR changes the following:
- Moves `Intrinsics` to `Realm`.
- Cleans up the initialization logic of our intrinsics to not depend on `Context`, unblocking things like #2314.
- Adds hooks to initialize the global object and the global this per the corresponding [`InitializeHostDefinedRealm ( )`](https://tc39.es/ecma262/#sec-initializehostdefinedrealm) hook. Though, this is currently broken because the vm uses `GlobalPropertyMap` instead of the `JsObject` API to initialize global properties.
Slightly related to #2411 since we need an API to pass module files, but more useful for #1760, #1313 and other error reporting issues.
It changes the following:
- Introduces a new `Source` API to store the path of a provided file or `None` if the source is a plain string.
- Improves the display of `boa_tester` to show the path of the tests being run. This also enables hyperlinks to directly jump to the tested file from the VS terminal.
- Adjusts the repo to this change.
Hopefully, this will improve our error display in the future.
Follows from #2528, and should complement #2411 to implement the module import hooks.
~~Similarly to the Intl/ICU4X PR (#2478), this has a lot of trivial changes caused by the new lifetimes. I thought about passing the queue and the hooks by value, but it was very painful having to wrap everything with `Rc` in order to be accessible by the host.
In contrast, `&dyn` can be easily provided by the host and has the advantage of not requiring additional allocations, with the downside of adding two more lifetimes to our `Context`, but I think it's worth.~~ I was able to unify all lifetimes into the shortest one of the three, making our API just like before!
Changes:
- Added a new `HostHooks` trait and a `&dyn HostHooks` field to `Context`. This allows hosts to implement the trait for their custom type, then pass it to the context.
- Added a new `JobQueue` trait and a `&dyn JobQueue` field to our `Context`, allowing custom event loops and other fun things.
- Added two simple implementations of `JobQueue`: `IdleJobQueue` which does nothing and `SimpleJobQueue` which runs all jobs until all successfully complete or until any of them throws an error.
- Modified `boa_cli` to run all jobs until the queue is empty, even if a job returns `Err`. This also prints all errors to the user.
This PR is a complete redesign of our current native functions and closures API.
I was a bit dissatisfied with our previous design (even though I created it 😆), because it had a lot of superfluous traits, a forced usage of `Gc<GcCell<T>>` and an overly restrictive `NativeObject` bound. This redesign, on the other hand, simplifies a lot our public API, with a simple `NativeCallable` struct that has several constructors for each type of required native function.
This new design doesn't require wrapping every capture type with `Gc<GcCell<T>>`, relaxes the trait requirement to `Trace + 'static` for captures, can be reused in both `JsObject` functions and (soonish) host defined functions, and is (in my opinion) a bit cleaner than the previous iteration. It also offers an `unsafe` API as an escape hatch for users that want to pass non-Copy closures which don't capture traceable types.
Would ask for bikeshedding about the names though, because I don't know if `NativeCallable` is the most precise name for this. Same about the constructor names; I added the `from` prefix to all of them because it's the "standard" practice, but seeing the API doesn't have any other method aside from `call`, it may be better to just remove the prefix altogether.
Let me know what you think :)
This Pull Request fixes/closes #1180. (I'll open a tracking issue for the progress)
It changes the following:
- Redesigns the internal API of Intl to (hopefully!) make it easier to implement a service.
- Implements the `Intl.Locale` service.
- Implements the `Intl.Collator` service.
- Implements the `Intl.ListFormat` service.
On the subject of the failing tests. Some of them are caused by missing locale data in the `icu_testdata` crate; we would need to regenerate that with the missing locales, or vendor a custom default data.
On the other hand, there are some tests that are bugs from the ICU4X crate. The repo https://github.com/jedel1043/icu4x-test262 currently tracks the found bugs when running test262. I'll sync with the ICU4X team to try to fix those.
cc @sffc
Per the [Standard Library development guide](https://std-dev-guide.rust-lang.org/code-considerations/performance/inline.html):
> You can add `#[inline]`:
>
> - To public, small, non-generic functions.
>
> You shouldn't need `#[inline]`:
> - On methods that have any generics in scope.
> - On methods on traits that don't have a default implementation.
>
> `#[inline]` can always be introduced later, so if you're in doubt they can just be removed.
This PR follows this guideline to reduce the number of `#[inline]` annotations in our code, removing the annotation in:
- Non-public functions
- Generic functions
- Medium and big functions.
Hopefully this shouldn't impact our perf at all, but let's wait to see the benchmark results.
This Pull Request restructures the lint deny/warn/allow lists in almost all crates. `boa_engine` will be done in a follow up PR as the changes there are pretty extensive.
Just some quality changes to improve the maintainability of the tester:
- Replaces `anyhow` with `color_eyre` to have a better output on errors/panics.
- Changes the ignore file to a TOML file and replaces all parsing logic with the `toml` crate.
- Adds a `ignored` field on all `Test`s to simplify run logic.
- Replaces the global `IGNORED` with an `ignored` argument on the CLI.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
Not sure if anyone else may be working on something more substantial/in-depth, but I thought I'd post this. 😄
The basic rundown is that this is more of an untested (and in some ways naïve) draft than anything else. It builds rather heavily on `rust-gc`, and tries to keep plenty of the core aspects so as to not break anything too much, and also to minimize overarching changes were it to actually be merged at some point.
This implementation does add ~~a generational divide (although a little unoptimized) to the heap,~~ a GcAlloc/Collector struct with methods, and an ephemeron implementation that allows for the WeakPair and WeakGc pointers.
So, there were some tests that weren't reporting the result of async evaluations correctly. This PR fixes this. It also ignores tests with the `IsHTMLDDA` feature, since we haven't implemented it.
On another note, this also changes the symbols of the test suite to 'F' (failed) and '-' (ignored), which is clearer for colorless terminals.
This Pull Request updates the codebase to the newest version of rustc (1.65.0).
It changes the following:
- Bumps `rust-version` to 1.65.0.
- Rewrites some snippets to use the new let else, ok_or_else and some other utils.
- Removes the `rustdoc::missing_doc_code_examples` allow lint from our codebase. (Context: https://github.com/rust-lang/rust/pull/101732)
This Pull Request replaces `contains`, `contains_arguments`, `has_direct_super` and `function_contains_super` with visitors. (~1000 removed lines!)
Also, the new visitor implementation caught a bug where we weren't setting the home object of async functions, generators and async generators for methods of classes, which caused a stack overflow on `super` calls, and I think that's pretty cool!
Next is `var_declared_names`, `lexically_declared_names` and friends, which will be on another PR.
We were always getting a "VM Implementation" headline in Test262 results for PRs. This was a leftover from the time when we had 2 distinct implementations for the execution. This is no longer the case, so we can remove it to reduce clutter.
This is an experiment that tries to migrate the codebase from eager `Error` objects to lazy ones.
In short words, this redefines `JsResult = Result<JsValue, JsError>`, where `JsError` is a brand new type that stores only the essential part of an error type, and only transforms those errors to `JsObject`s on demand (when having to pass them as arguments to functions or store them inside async/generators).
This change is pretty big, because it unblocks a LOT of code from having to take a `&mut Context` on each call. It also paves the road for possibly making `JsError` a proper variant of `JsValue`, which can be a pretty big optimization for try/catch.
A downside of this is that it exposes some brand new error types to our public API. However, we can now implement `Error` on `JsError`, making our `JsResult` type a bit more inline with Rust's best practices.
~Will mark this as draft, since it's missing some documentation and a lot of examples, but~ it's pretty much feature complete. As always, any comments about the design are very much appreciated!
Note: Since there are a lot of changes which are essentially just rewriting `context.throw` to `JsNativeError::%type%`, I'll leave an "index" of the most important changes here:
- [boa_engine/src/error.rs](https://github.com/boa-dev/boa/pull/2283/files#diff-f15f2715655440626eefda5c46193d29856f4949ad37380c129a8debc6b82f26)
- [boa_engine/src/builtins/error/mod.rs](https://github.com/boa-dev/boa/pull/2283/files#diff-3eb1e4b4b5c7210eb98192a5277f5a239148423c6b970c4ae05d1b267f8f1084)
- [boa_tester/src/exec/mod.rs](https://github.com/boa-dev/boa/pull/2283/files#diff-fc3d7ad7b5e64574258c9febbe56171f3309b74e0c8da35238a76002f3ee34d9)
This Pull Request fixes/closes #2330.
It changes the following:
- Upgrades from clap 3 to clap 4 (note that criterion still uses clap 3, tracked here: https://github.com/bheisler/criterion.rs/issues/596)
- Updates the derive syntax with the new 4.0 syntax
- Adds hints for fish & zsh
Co-authored-by: José Julián Espina <jedel0124@gmail.com>
I think it's time to address the elephant in the room.
This Pull Request will (hopefully!) solve part of #736.
This is a complete rewrite of `JsString`, but instead of storing `u8` bytes it stores `u16` words. The `encode!` macro (renamed to `utf16!` for simplicity) from the `const-utf16` crate allows us to create UTF-16 encoded arrays at compilation time. `JsString` implements `Deref<Target=[u16]>` to unlock the slice methods and possibly make some manipulations easier. However, we would need to create our own library of utilities for `JsString`.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel neccesary.
--->
This Pull Request removes two dependencies that were not really needed, and fixes#2244 by no longer having the package in the dependency tree.
It changes the following:
- The `structopt` dependency in `boa_tester` has been replaced by `clap` v3, the same way as we did in `boa_cli`. This means that we have one less dependency (at least), and that `clap` v2 is only used as a dev-dependency by `criterion` (which will probably be removed in 0.4, as per https://github.com/bheisler/criterion.rs/issues/596).
- The no-longer-updated `num-format` dependency has been removed from `boa_tester`. We were only using it to add comma thousands separator on results, so I added a simple function to do it (not very performant, but it will only be used a few times when showing results).
Looking at this, I noticed a couple of things:
- The `csv` dependency, used by `criterion` has not been updated in more than a year, and it's using a very old `itoa` dependency. They updated the dependency in the repository in March, but unfortunately, the release is taking some more time than expected, and a tracking issue can be found here: https://github.com/BurntSushi/rust-csv/issues/271
- `cargo update` fails, because the latest update to `tinystr` in the ICU4x breaks ICU4x 0.6. I have reported this here: https://github.com/unicode-org/icu4x/issues/2428 and their recommendation is for us to use a beta version of the library, but I don't think we should go for that, since this is a semver breakage.
The `Context` currently contains a `strict` flag that indicates is global strict mode is active. This is redundant to the strict flag that is set on every function and causes some non spec compliant situations. This pull request removes the strict flag from `Context` and fixes some resulting errors.
Detailed changes:
- Remove strict flag from `Context`
- Make 262 tester compliant with the strict section in [test262/INTERPRETING.md](2e7cdfbe18/INTERPRETING.md (strict-mode))
- Make 262 tester compliant with the `raw` flag in [test262/INTERPRETING.md](2e7cdfbe18/INTERPRETING.md (flags))
- Allow function declarations in strict mode
- Fix parser flag propagation for classes
- Move some early errors from the lexer to the parser
- Add / fix some early errors for 'arguments' and 'eval' identifier usage in strict mode
- Refactor `ArrayLiteral` parser for readability and correct early errors
This Pull Request changes the following:
- Implement redeclaration errors in the parser
- Remove redeclaration errors from the compiler (this is a big step towards #1907)
- Fix some failing tests on the way
This requires a slight change in our public api. The Parser new requires a full `Context` instead of just the `Interner` for parsing new code. This is required, because if multiple scripts are parsed (e.g. every input in the REPL) global variables must be checked for redeclarations.
This removes the only use of the `git2` and `hex` dependencies by reading the test262 submodule commit id directly from the `.git` directory.
Because `git2` depends on a lot of other crates, this removes a bunch of dependencies.
Trying to fix the issue in #1982, I noticed that we didn't have a proper error handling for the boa tester.
This adds the `anyhow` dependency to the tester, which makes it much easier to handle errors and bubble them up with attached context. Thanks to this I was able to easily find out the issue, and I think it could be useful to have it. It gives errors such as this one:
```
Error: could not read the suite test
caused by: error reading sub-suite ./test262/test/built-ins
caused by: error reading sub-suite ./test262/test/built-ins/ShadowRealm
caused by: error reading sub-suite ./test262/test/built-ins/ShadowRealm/WrappedFunction
caused by: error reading test ./test262/test/built-ins/ShadowRealm/WrappedFunction/throws-typeerror-on-revoked-proxy.js
caused by: while scanning a block scalar, found a tab character where an indentation space is expected at line 4 column 3
caused by: while scanning a block scalar, found a tab character where an indentation space is expected at line 4 column 3
```
This Pull Request fixes/closes #1645.
It changes the following:
- Add `features` field to `SuiteResult` structure
- Fetch features from `TestSuite` and propagate them via `SuiteResult`
- Add `FeaturesInfo` structure and serialize it to `features.json`
This fixes an issue with 262 negative tests, that should produce a syntax errors. Currently we only parse the test code is such cases. If the parsing does not return an error, we do not compile the code further. This caused some panics. Most of them are fixed by now, the last ones will be fixed with #1860.
This is an attempt to refactor the environments to be more performant at runtime. The idea is, to shift the dynamic hashmap environment lookups from runtime to compile time.
Currently the environments hold hashmaps that contain binding identifiers, values and additional information that is needed to identify some errors. Because bindings in outer environments are accessible from inner environments, this can lead to a traversal through all environments (in the worst case to the global environment).
This change to the environment structure pushes most of the work that is needed to access bindings to the compile time. At compile time, environments and bindings in the environments are being assigned indices. These indices are then stored instead of the `Sym` that is currently used to access bindings. At runtime, the indices are used to access bindings in a fixed size `Vec` per environment. This brings multiple benefits:
- No hashmap access needed at runtime
- The number of bindings per environment is known at compile time. Environments only need a single allocation, as their size is constant.
- Potential for optimizations with `unsafe` https://doc.rust-lang.org/std/vec/struct.Vec.html#method.get_unchecked
Additionally, this changes the global object to have it's bindings directly stored on the `Realm`. This should reduce some overhead from access trough gc objects and makes some optimizations for the global object possible.
The benchmarks look not that great on the first sight. But if you look closer, I think it is apparent, that this is a positive change. The difference is most apparent on Mini and Clean as they are longer (still not near any real life js but less specific that most other benchmarks):
| Test | Base | PR | % |
|------|--------------|------------------|---|
| Clean js (Compiler) | **1929.1±5.37ns** | 4.1±0.02µs | **+112.53%** |
| Clean js (Execution) | 1487.4±7.50µs | **987.3±3.78µs** | **-33.62%** |
The compile time is up in all benchmarks, as expected. The percentage is huge, but if we look at the real numbers, we can see that this is an issue of orders of magnitude. While compile is up `112.53%`, the real change is `~+2µs`. Execution is only down `33.62%`, but the real time changed by `~-500µs`.
Co-authored-by: Iban Eguia <razican@protonmail.ch>
This removes all the calls to `unwrap()` in the codebase, which made me found a couple of places where it wasn't needed, and could be improved. I also noticed we don't have dependabot updates for the test262 submodule and the interner dependencies, so I added those.
I added lints so that no new unwraps are added.
This PR adds some Clippy lints. Mainly, it adds the list of pedantic lints excluding some lints that were causing too many warnings. I also denied some useful restriction and pedantic lints, to make sure we use `Self` all the possible times (for better maintainability), and that we pass elements by reference where possible, for example, or that the documentation is properly written.
This might even have some small performance gains.
I also added a perfect hash function for the CLI keywords, which should be more efficient than a `HashSet`. This is something we could use elsewhere too.
This builds on top of #1758 to try to bring #1763 to life.
Something that should probably be done here would be to convert `JsString` to a `Sym` internally. Then, further optimizations could be done adding common strings to a custom interner type (those that we know statically).
This is definitely work in progress, but I would like to have feedback on the API, and feel free to contribute.
Co-authored-by: raskad <32105367+raskad@users.noreply.github.com>
{kind=link}