This Pull Request implements [Initializers in ForIn Statement Heads](https://tc39.es/ecma262/#sec-initializers-in-forin-statement-heads) from the Annex B. This also cleans up the "annex-b" feature to be able to disable it with `--no-default-features`, since I couldn't test the error messages when the feature is disabled.
This Pull Request fixes some additional Annex B tests.
It changes the following:
- Fixes bugs related to parsing HTML closing comments (`-->`).
- Implements `RegExp::compile` behind the `annex-b` feature.
- Ignores the `legacy-regexp` feature flag, since it's still stage 3.
Small steps towards ES5 conformance.
This PR changes the following:
- Implements HTML comments parsing (`<!--`, `-->`).
- Gates the functionality behind a new `annex-b` feature for `boa_parser`.
- Renames `strict_mode` to `strict` to be consistent with `Parser::set_strict`.
Currently we have no explicit representation for parenthesized expressions which makes some behaviours impossible to detect. A bonus is that we can now turn AST that contains parenthesized expressions back to code.
This Pull Request changes the following:
- Add an AST node for parenthesized expressions.
- Adjust some conversions and checks to "ignore"/"expand" parenthesized expressions.
- Fix some tests that had parenthesized expressions.
This PR changes the following:
- Adds a new (very simple) security policy, to comply with GitHub standards
- Changes the internal links of the documentation to point to the new boajs.dev domain
- The developer documentation link now lies in the CONTRIBUTING.md file
This Pull Request changes the following:
- Implement `with` statement parsing, ast node, compilation and excution.
- Implement object environments that are used in the `with` statement excution.
The implementation of object environments can probably be optimized further by using more compile-time information about when object environments can exist. Maybe there could also be a separate environment stack for object environments to reduce the filtering and iteration that is needed with the current implementation.
This does not fix all tests in the `test/language/statements/with` suite yet. But for most failing tests that I have looked at we are missing other features / have bugs elsewhere.
As a note for the review:
The functions in the `impl Context` block in `boa_engine/src/environments/runtime.rs` are mostly copied / moved from the existing functions. The only change there should be the addition of the object environment logic. They had to be moved to `Context` because of borrow semantics.
Bumps [regress](https://github.com/ridiculousfish/regress) from 0.4.1 to 0.5.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/ridiculousfish/regress/releases">regress's releases</a>.</em></p>
<blockquote>
<h2>v0.5.0</h2>
<p>Version 0.5.0 of regress, REGex in Rust with EmcaScript Syntax.</p>
<ul>
<li>Unicode property escape matching like <code>\p{Letter}</code> is implemented</li>
<li>Regex parsing may now use any u32 iterator, not simply strings</li>
<li>The Unicode flag "u" is now recognized. Unicode is no longer the default; however non-Unicode regular expression support still has some known differences from JavaScript.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="ee710e577f"><code>ee710e5</code></a> Remove language about unicode property escapes being unimplemented</li>
<li><a href="8349a8569e"><code>8349a85</code></a> Bump version to 0.5 in preparation for release</li>
<li><a href="60d4f7b595"><code>60d4f7b</code></a> Update the unicode tables for Unicode 15</li>
<li><a href="603833d432"><code>603833d</code></a> Add test for escaping unrecognised chars</li>
<li><a href="f06b2b3ce1"><code>f06b2b3</code></a> Allow all punctuations to be escaped</li>
<li><a href="7443e66ccc"><code>7443e66</code></a> Update hashbrown requirement from 0.12.0 to 0.13.2</li>
<li><a href="ac59d90fd0"><code>ac59d90</code></a> rustfmt classicalbacktrack.rs</li>
<li><a href="cceb877af2"><code>cceb877</code></a> [non-unicode] less strict QuantifierPrefix parsing</li>
<li><a href="0ca4b596ca"><code>0ca4b59</code></a> to2021, simplfy some code.</li>
<li><a href="d076e06315"><code>d076e06</code></a> parse unbalanced right brackets as a literal bracket, if not using unicode flag</li>
<li>Additional commits viewable in <a href="https://github.com/ridiculousfish/regress/compare/v0.4.1...v0.5.0">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
Co-authored-by: raskad <32105367+raskad@users.noreply.github.com>
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
This Pull Request addresses the broken `cargo clippy` lints that is currently causing CI to fail.
This PR migrates our entire test suite to our new testing API.
It changes the following:
- Migrates tests to new test API.
- Cleans up the API to be a bit more descriptive and maintainable.
- Prettifies our test failure display to show the failed scripts.
- Splits our massive `tests.rs` file into smaller sub-suites.
Example output of a failing test:
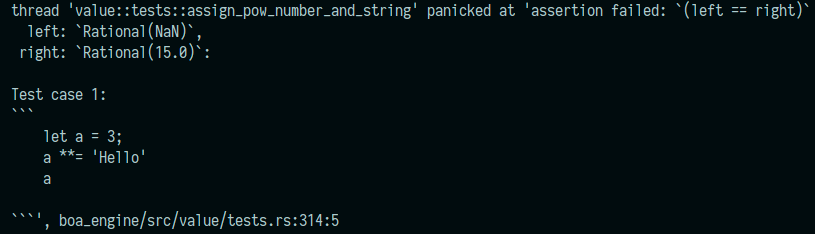
This Pull Request closes#1907.
It changes the following:
- Implement several early errors relating to labels, `break` and `continue` in the parser.
- Implement an early error for invalid cover grammar of object literals in the parser.
- Remove all remaining syntax errors from the bytecompiler.
I'm creating this draft PR, since I wanted to have some early feedback, and because I though I would have time to finish it last week, but I got caught up with other stuff. Feel free to contribute :)
The main thing here is that I have divided `eval()`, `parse()` and similar functions so that they can decide if they are parsing scripts or modules. Let me know your thoughts.
Then, I was checking the import & export parsing, and I noticed we are using `TokenKind::Identifier` for `IdentifierName`, so I changed that name. An `Identifier` is an `IdentifierName` that isn't a `ReservedWord`. This means we should probably also adapt all `IdentifierReference`, `BindingIdentifier` and so on parsing. I already created an `Identifier` parser.
Something interesting there is that `await` is not a valid `Identifier` if the goal symbol is `Module`, as you can see in the [spec](https://tc39.es/ecma262/#prod-LabelIdentifier), but currently we don't have that information in the `InputElement` enumeration, we only have `Div`, `RegExp` and `TemplateTail`. How could we approach this?
Co-authored-by: jedel1043 <jedel0124@gmail.com>
This Pull Request changes the following:
- Implement binary `in` operation with private names.
- Adding a separate `BinaryInPrivate` expression in addition to the existing `Binary` expression seems like the best way to implement this in a typesafe manner. Other methods like adding an enum for the `Binary` lhs result in having to make assertions.
This Pull Request changes the following:
- Move postfix/prefix increment and decrement operations from the `Unary` expression to a new `Update` expression.
- Add a special type for the `Update` expression target as it is very limited in comparision to an `Unary` target.
- This makes bytecode compilation more typesafe for these operations and removes syntax errors from the bytecompiler without introducing panics (see #1907).
Another change extracted from #2411.
This PR changes the following:
- Improves our identifier parsing with a new `Identifier` parser that unifies parsing for `IdentifierReference`, `BindingIdentifier` and `LabelIdentifier`.
- Slightly improves some error messages.
- Extracts our manual initialization of static `Sym`s with a new `static_syms` proc macro.
- Adds `set_module_mode` and `module_mode` to the cursor to prepare for modules.
Slightly related to #2411 since we need an API to pass module files, but more useful for #1760, #1313 and other error reporting issues.
It changes the following:
- Introduces a new `Source` API to store the path of a provided file or `None` if the source is a plain string.
- Improves the display of `boa_tester` to show the path of the tests being run. This also enables hyperlinks to directly jump to the tested file from the VS terminal.
- Adjusts the repo to this change.
Hopefully, this will improve our error display in the future.
Extracted from #2411 to reduce its size a bit.
This PR:
- Renames `Identifier` to `IdentifierName`, which is the name stated in the spec.
- Renames the utility function `check_parser` to `check_script_parser` to prepare for modules.
- Adds some missing `#[inline]` and rewrites some patterns.
This Pull Request changes the following:
- Add early errors for escaped characters in object and class setters and getters.
- Add early errors for escaped characters in class `static`.
- Add early errors for escaped characters in `new.target`.
- Add early errors for legacy octal/decial escapes that are used in string literals before a `"use strict"` directive.
This Pull Request changes the following:
- Remove wrong early errors for static class methods with the computed property name `prototype`.
- Switch static class method definition opcodes from `__define_own_property__` to `define_property_or_throw` to correctly throw runtime errors on property redefinitions.
This Pull Request hanges the following:
- Add early errors for invalid `yield` and `await` usage in function parameters.
- Add missing function types to hoistable ordering.
- Do not attempt to parse `async` with a following line terminator as an async function.
This Pull Request changes the following:
- Do not skip consecutive semicolons while parsing a `StatementList`.
- Expect semicolon in `LexicalDeclaration` and add an special case for `for` loop parsing.
- Adjust `StatementList` compilation to skip empty statements.
- Adjust/add tests to make sure consecutive semicolons are correctly parsed.
This Pull Request fixes various bugs related to classes.
The biggest changes are:
- Changed private names to be unique across multiple classes.
- Changed private name resolution to work via a visitor after a class is parsed. The way class early errors are defined makes it impossible to perform private name resolution while parsing.
- Added function names to class methods.
- Added class name binding to method function environments.
- Separated opcodes for `static` and non-`static` class method definitions to make the above operations possible.
There are still some bugs and further issues with classes but this is already a lot.
This Pull Request changes the following:
- Add early errors for functions to make sure that 'eval' or 'arguments' cannot be used as binding identifiers in function parameters. When the function body contains a strict directive, this also has to be accounted for.
- Fix early errors for function identifiers to make sure they cannot be 'eval' or 'arguments' when a function body contains a strict directive.
Postfix increment / decrement operators require that there is no line terminator between the LHS expression and the operator. This was previously ignored.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
This Pull Request fixes/closes #2416.
Previously, prefix increment and decrement operations on `this` caused a panic. This PR makes the parser issue a syntax error when the operand UnaryExpression is not simple (as mentioned in https://tc39.es/ecma262/#sec-update-expressions-static-semantics-early-errors).
This Pull Request fixes/closes #1180. (I'll open a tracking issue for the progress)
It changes the following:
- Redesigns the internal API of Intl to (hopefully!) make it easier to implement a service.
- Implements the `Intl.Locale` service.
- Implements the `Intl.Collator` service.
- Implements the `Intl.ListFormat` service.
On the subject of the failing tests. Some of them are caused by missing locale data in the `icu_testdata` crate; we would need to regenerate that with the missing locales, or vendor a custom default data.
On the other hand, there are some tests that are bugs from the ICU4X crate. The repo https://github.com/jedel1043/icu4x-test262 currently tracks the found bugs when running test262. I'll sync with the ICU4X team to try to fix those.
cc @sffc
Per the [Standard Library development guide](https://std-dev-guide.rust-lang.org/code-considerations/performance/inline.html):
> You can add `#[inline]`:
>
> - To public, small, non-generic functions.
>
> You shouldn't need `#[inline]`:
> - On methods that have any generics in scope.
> - On methods on traits that don't have a default implementation.
>
> `#[inline]` can always be introduced later, so if you're in doubt they can just be removed.
This PR follows this guideline to reduce the number of `#[inline]` annotations in our code, removing the annotation in:
- Non-public functions
- Generic functions
- Medium and big functions.
Hopefully this shouldn't impact our perf at all, but let's wait to see the benchmark results.
<!---
Thank you for contributing to Boa! Please fill out the template below, and remove or add any
information as you feel necessary.
--->
Submitting this as a draft for feedback/second opinions. This draft contains some changes to the documentation.
Quick Overview:
- Potential `Boa` header for Boa's crates added to `boa_engine`.
- Changes the wording to a lot of module headers (See `builtins` module and `object/builtins` module).
- Updating built-in wrapper's code examples to use `?` operator.
- Adds the doc logo URL to a few crates that didn't have it.
The main idea of this draft is to move away from the "This module implements" wording as it feels a bit duplicative when listed under the Modules section (mainly focusing around changes in `boa_engine` to start).
While working on this, I had a question about whether we should be using JavaScript or ECMAScript in the Boa's documentation. We do seem to currently use both, and this draft uses JavaScript heavily in the wording.
This Pull Request changes the following:
- Remove false early error when a class expression was missing a binding identifier.
- Simplify/fix environment truncation on function returns.
The new failed tests where false positives before that will be fixed in another PR.
This Pull Request restructures the lint deny/warn/allow lists in almost all crates. `boa_engine` will be done in a follow up PR as the changes there are pretty extensive.
{kind=link}