|
|
5 years ago | |
|---|---|---|
| dockerfile | 5 years ago | |
| docs/zh_CN | 5 years ago | |
| escheduler-alert | 5 years ago | |
| escheduler-api | 5 years ago | |
| escheduler-common | 5 years ago | |
| escheduler-dao | 5 years ago | |
| escheduler-rpc | 5 years ago | |
| escheduler-server | 5 years ago | |
| escheduler-ui | 5 years ago | |
| script | 6 years ago | |
| sql | 5 years ago | |
| .gitattributes | 6 years ago | |
| .gitignore | 6 years ago | |
| CONTRIBUTING.md | 6 years ago | |
| LICENSE | 6 years ago | |
| NOTICE | 6 years ago | |
| README.md | 5 years ago | |
| README_zh_CN.md | 5 years ago | |
| install.sh | 5 years ago | |
| package.xml | 5 years ago | |
| pom.xml | 5 years ago | |
README.md
Easy Scheduler
![]()
Easy Scheduler for Big Data
Design features:
A distributed and easy-to-expand visual DAG workflow scheduling system. Dedicated to solving the complex dependencies in data processing, making the scheduling system out of the box for data processing.
Its main objectives are as follows:
- Associate the Tasks according to the dependencies of the tasks in a DAG graph, which can visualize the running state of task in real time.
- Support for many task types: Shell, MR, Spark, SQL (mysql, postgresql, hive, sparksql), Python, Sub_Process, Procedure, etc.
- Support process scheduling, dependency scheduling, manual scheduling, manual pause/stop/recovery, support for failed retry/alarm, recovery from specified nodes, Kill task, etc.
- Support process priority, task priority and task failover and task timeout alarm/failure
- Support process global parameters and node custom parameter settings
- Support online upload/download of resource files, management, etc. Support online file creation and editing
- Support task log online viewing and scrolling, online download log, etc.
- Implement cluster HA, decentralize Master cluster and Worker cluster through Zookeeper
- Support online viewing of
Master/Workercpu load, memory, cpu - Support process running history tree/gantt chart display, support task status statistics, process status statistics
- Support for complement
- Support for multi-tenant
- Support internationalization
- There are more waiting partners to explore
Comparison with similar scheduler systems
| EasyScheduler | Azkaban | Airflow | |
|---|---|---|---|
| Stability | |||
| Single point of failure | Decentralized multi-master and multi-worker | Yes Single Web and Scheduler Combination Node |
Yes Single Scheduler |
| Additional HA requirements | Not required (HA is supported by itself) | DB | Celery / Dask / Mesos + Load Balancer + DB |
| Overload processing | Task queue mechanism, the number of schedulable tasks on a single machine can be flexibly configured, when too many tasks will be cached in the task queue, will not cause machine jam. | Jammed the server when there are too many tasks | Jammed the server when there are too many tasks |
| Easy to use | |||
| DAG Monitoring Interface | Visualization process defines key information such as task status, task type, retry times, task running machine, visual variables and so on at a glance. | Only task status can be seen | Can't visually distinguish task types |
| Visual process definition | Yes All process definition operations are visualized, dragging tasks to draw DAGs, configuring data sources and resources. At the same time, for third-party systems, the api mode operation is provided. |
No DAG and custom upload via custom DSL |
No DAG is drawn through Python code, which is inconvenient to use, especially for business people who can't write code. |
| Quick deployment | One-click deployment | Complex clustering deployment | Complex clustering deployment |
| Features | |||
| Suspend and resume | Support pause, recover operation | No Can only kill the workflow first and then re-run |
No Can only kill the workflow first and then re-run |
| Whether to support multiple tenants | Users on easyscheduler can achieve many-to-one or one-to-one mapping relationship through tenants and Hadoop users, which is very important for scheduling large data jobs. " Supports traditional shell tasks, while supporting large data platform task scheduling: MR, Spark, SQL (mysql, postgresql, hive, sparksql), Python, Procedure, Sub_Process | No | No |
| Task type | Supports traditional shell tasks, and also support big data platform task scheduling: MR, Spark, SQL (mysql, postgresql, hive, sparksql), Python, Procedure, Sub_Process | shell、gobblin、hadoopJava、java、hive、pig、spark、hdfsToTeradata、teradataToHdfs | BashOperator、DummyOperator、MySqlOperator、HiveOperator、EmailOperator、HTTPOperator、SqlOperator |
| Compatibility | Support the scheduling of big data jobs like spark, hive, Mr. At the same time, it is more compatible with big data business because it supports multiple tenants. | Because it does not support multi-tenant, it is not flexible enough to use business in big data platform. | Because it does not support multi-tenant, it is not flexible enough to use business in big data platform. |
| Scalability | |||
| Whether to support custom task types | Yes | Yes | Yes |
| Is Cluster Extension Supported? | Yes The scheduler uses distributed scheduling, and the overall scheduling capability will increase linearly with the scale of the cluster. Master and Worker support dynamic online and offline. |
Yes but complicated Executor horizontal extend |
Yes but complicated Executor horizontal extend |
System partial screenshot

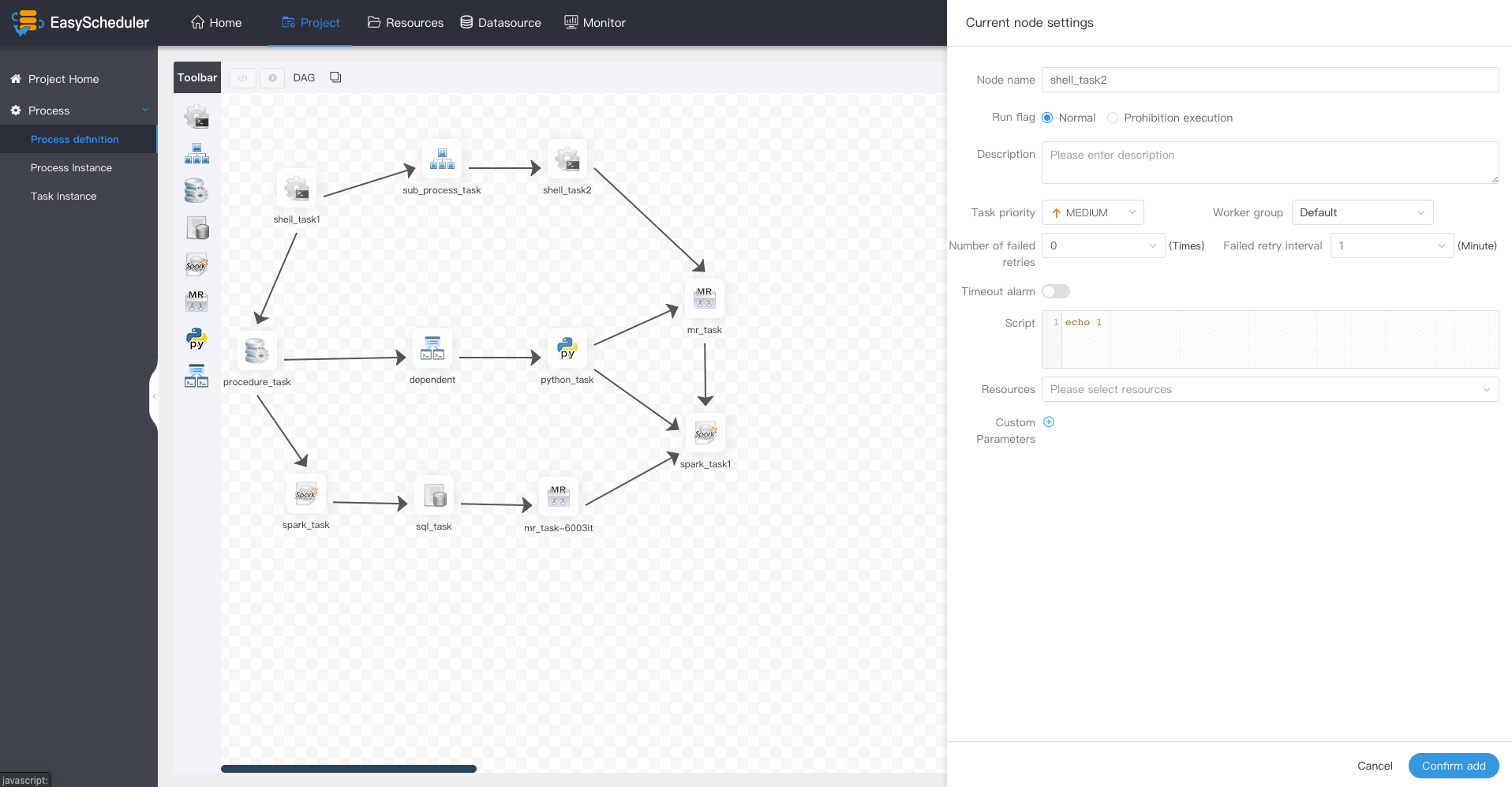
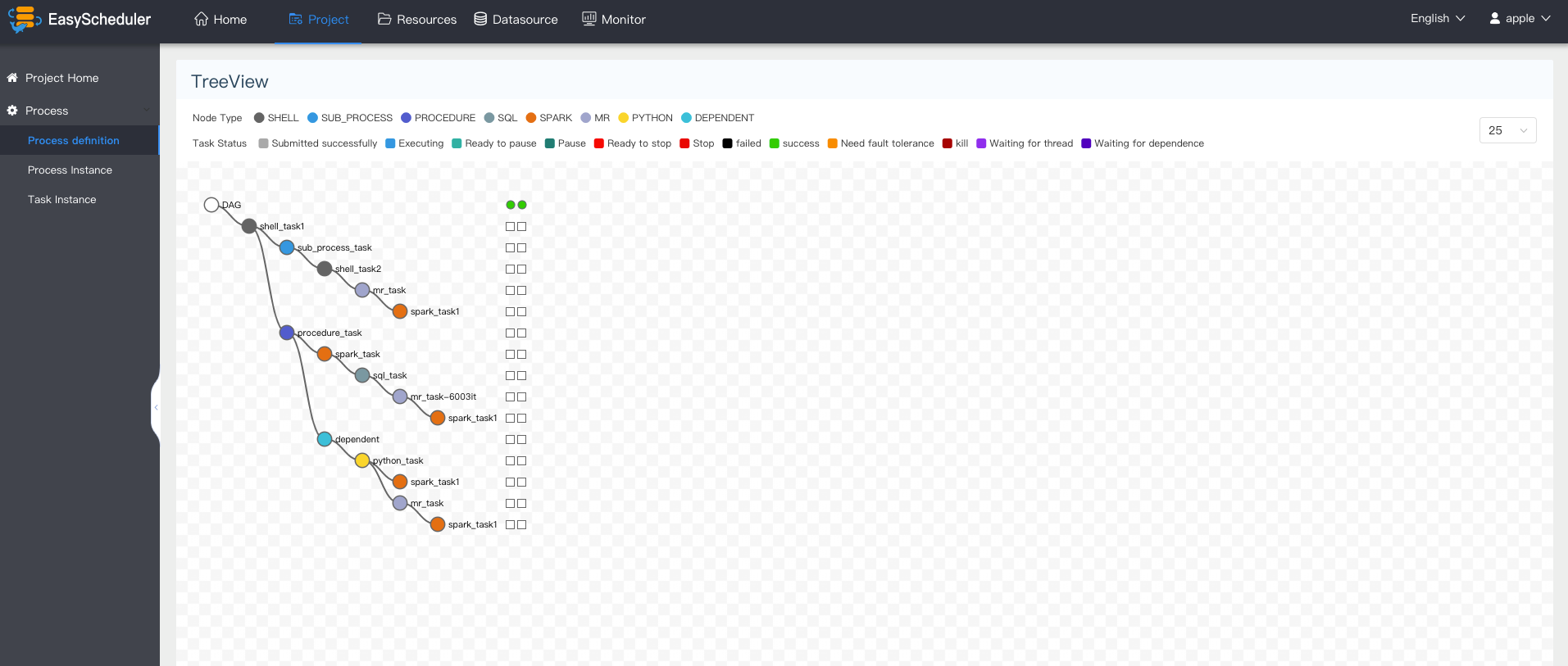
Document
More documentation please refer to [EasyScheduler online documentation]
Recent R&D plan
Work plan of Easy Scheduler: R&D plan, where In Develop card is the features of 1.1.0 version , TODO card is to be done (including feature ideas)
How to contribute code
Welcome to participate in contributing code, please refer to the process of submitting the code: https://github.com/analysys/EasyScheduler/blob/master/CONTRIBUTING.md
Thanks
Easy Scheduler uses a lot of excellent open source projects, such as google guava, guice, grpc, netty, ali bonecp, quartz, and many open source projects of apache, etc. It is because of the shoulders of these open source projects that the birth of the Easy Scheduler is possible. We are very grateful for all the open source software used! We also hope that we will not only be the beneficiaries of open source, but also be open source contributors, so we decided to contribute to easy scheduling and promised long-term updates. We also hope that partners who have the same passion and conviction for open source will join in and contribute to open source!
Get Help
The fastest way to get response from our developers is to submit issues, or add our wechat : 510570367
License
Please refer to LICENSE file.