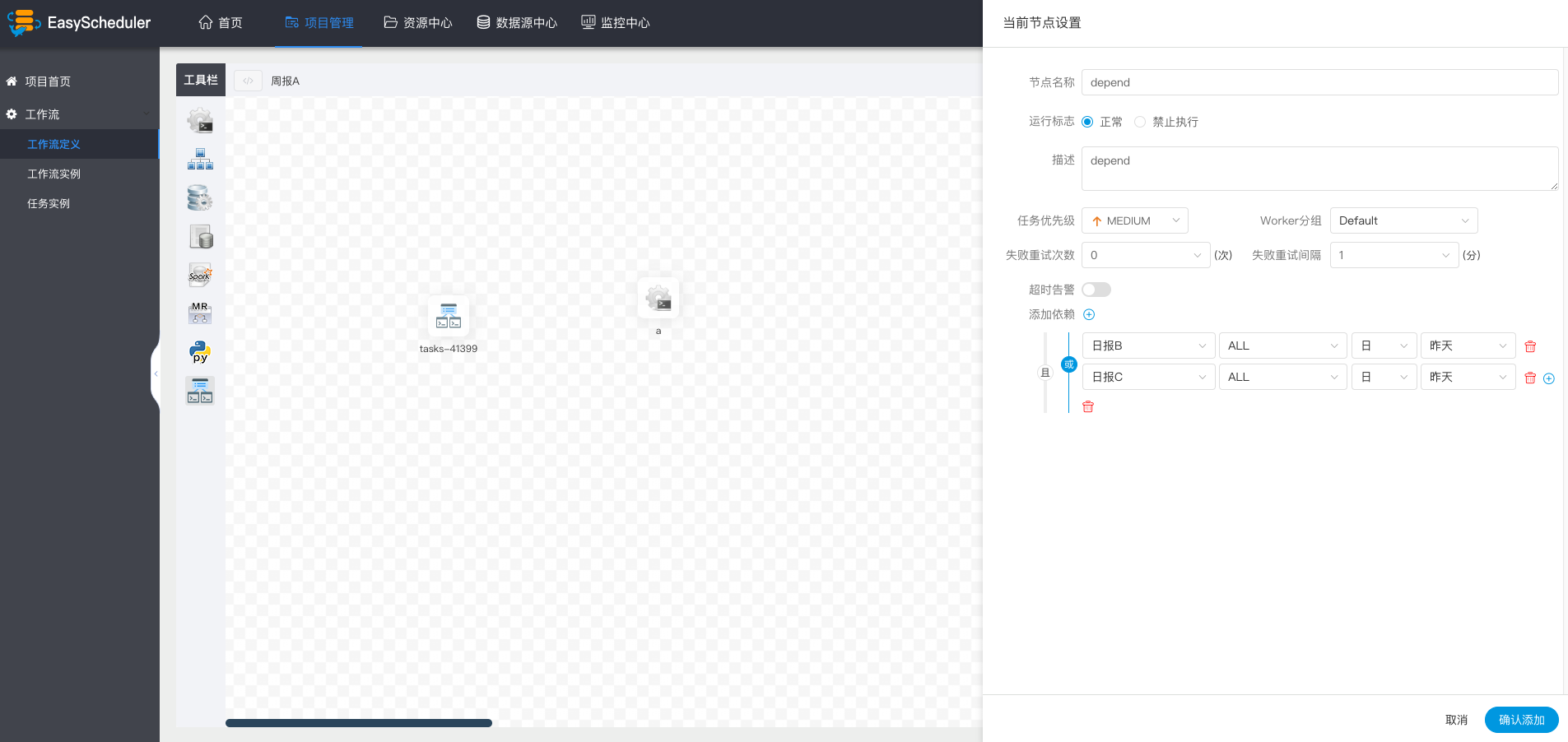
| variable | meaning |
|---|
| ${system.biz.date} |
The timing time of routine dispatching instance is one day before, in yyyyyMMdd format. When data is supplemented, the date + 1 |
| ${system.biz.curdate} |
Daily scheduling example timing time, format is yyyyyMMdd, when supplementing data, the date + 1 |
| ${system.datetime} |
Daily scheduling example timing time, format is yyyyyMMddHmmss, when supplementing data, the date + 1 |
### Time Customization Parameters
> Support code to customize the variable name, declaration: ${variable name}. It can refer to "system parameters" or specify "constants".
> When we define this benchmark variable as $[...], [yyyyMMddHHmmss] can be decomposed and combined arbitrarily, such as:$[yyyyMMdd], $[HHmmss], $[yyyy-MM-dd] ,etc.
> Can also do this:
>
>
- Later N years: $[add_months (yyyyyyMMdd, 12*N)]
- The previous N years: $[add_months (yyyyyyMMdd, -12*N)]
- Later N months: $[add_months (yyyyyMMdd, N)]
- The first N months: $[add_months (yyyyyyMMdd, -N)]
- Later N weeks: $[yyyyyyMMdd + 7*N]
- The first N weeks: $[yyyyyMMdd-7*N]
- The day after that: $[yyyyyyMMdd + N]
- The day before yesterday: $[yyyyyMMdd-N]
- Later N hours: $[HHmmss + N/24]
- First N hours: $[HHmmss-N/24]
- After N minutes: $[HHmmss + N/24/60]
- First N minutes: $[HHmmss-N/24/60]
### User-defined parameters
> User-defined parameters are divided into global parameters and local parameters. Global parameters are the global parameters passed when the process definition and process instance are saved. Global parameters can be referenced by local parameters of any task node in the whole process.
> For example:























 >
>