## Q: EasyScheduler service introduction and recommended running memory
A: EasyScheduler consists of 5 services, MasterServer, WorkerServer, ApiServer, AlertServer, LoggerServer and UI.
| Service | Description |
| ------------------------- | ------------------------------------------------------------ |
| MasterServer | Mainly responsible for DAG segmentation and task status monitoring |
| WorkerServer/LoggerServer | Mainly responsible for the submission, execution and update of task status. LoggerServer is used for Rest Api to view logs through RPC |
| ApiServer | Provides the Rest Api service for the UI to call |
| AlertServer | Provide alarm service |
| UI | Front page display |
Note:**Due to the large number of services, it is recommended that the single-machine deployment is preferably 4 cores and 16G or more.**
---
## Q: Why can't an administrator create a project?
A: The administrator is currently "**pure management**". There is no tenant, that is, there is no corresponding user on linux, so there is no execution permission, **so there is no project, resource and data source,** so there is no permission to create. **But there are all viewing permissions**. If you need to create a business operation such as a project, **use the administrator to create a tenant and a normal user, and then use the normal user login to operate**. We will release the administrator's creation and execution permissions in version 1.1.0, and the administrator will have all permissions.
---
## Q: Which mailboxes does the system support?
A: Support most mailboxes, qq, 163, 126, 139, outlook, aliyun, etc. are supported. Support TLS and SSL protocols, optionally configured in alert.properties
---
## Q: What are the common system variable time parameters and how do I use them?
A: Please refer to https://analysys.github.io/easyscheduler_docs_cn/%E7%B3%BB%E7%BB%9F%E4%BD%BF%E7%94%A8%E6%89%8B%E5%86%8C.html#%E7%B3%BB%E7%BB%9F%E5%8F%82%E6%95%B0
---
## Q: pip install kazoo This installation gives an error. Is it necessary to install?
A: This is the python connection zookeeper needs to use, must be installed
---
## Q: How to specify the machine running task
A: Use **the administrator** to create a Worker group, **specify the Worker group** when the **process definition starts**, or **specify the Worker group on the task node**. If not specified, use Default, **Default is to select one of all the workers in the cluster to use for task submission and execution.**
---
## Q: Priority of the task
A: We also support t**he priority of processes and tasks**. Priority We have five levels of **HIGHEST, HIGH, MEDIUM, LOW and LOWEST**. **You can set the priority between different process instances, or you can set the priority of different task instances in the same process instance.** For details, please refer to the task priority design https://analysys.github.io/easyscheduler_docs_cn/%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1.html#%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1
----
## Q: Escheduler-grpc gives an error
A: Execute in the root directory: mvn -U clean package assembly:assembly -Dmaven.test.skip=true , then refresh the entire project
----
## Q: Does EasyScheduler support running on windows?
A: In theory, **only the Worker needs to run on Linux**. Other services can run normally on Windows. But it is still recommended to deploy on Linux.
-----
## Q: UI compiles node-sass prompt in linux: Error: EACCESS: permission denied, mkdir xxxx
A: Install **npm install node-sass --unsafe-perm** separately, then **npm install**
---
## Q: UI cannot log in normally.
A: 1, if it is node startup, check whether the .env API_BASE configuration under escheduler-ui is the Api Server service address.
2, If it is nginx booted and installed via **install-escheduler-ui.sh**, check if the proxy_pass configuration in **/etc/nginx/conf.d/escheduler.conf** is the Api Server service. address
3, if the above configuration is correct, then please check if the Api Server service is normal, curl http://192.168.xx.xx:12345/escheduler/users/get-user-info, check the Api Server log, if Prompt cn.escheduler.api.interceptor.LoginHandlerInterceptor:[76] - session info is null, which proves that the Api Server service is normal.
4, if there is no problem above, you need to check if **server.context-path and server.port configuration** in **application.properties** is correct
---
## Q: After the process definition is manually started or scheduled, no process instance is generated.
A: 1, first **check whether the MasterServer service exists through jps**, or directly check whether there is a master service in zk from the service monitoring.
2,If there is a master service, check **the command status statistics** or whether new records are added in **t_escheduler_error_command**. If it is added, **please check the message field.**
---
## Q : The task status is always in the successful submission status.
A: 1, **first check whether the WorkerServer service exists through jps**, or directly check whether there is a worker service in zk from the service monitoring.
2,If the **WorkerServer** service is normal, you need to **check whether the MasterServer puts the task task in the zk queue. You need to check whether the task is blocked in the MasterServer log and the zk queue.**
3, if there is no problem above, you need to locate whether the Worker group is specified, but **the machine grouped by the worker is not online**.**
---
## Q: Is there a Docker image and a Dockerfile?
A: Provide Docker image and Dockerfile.
Docker image address: https://hub.docker.com/r/escheduler/escheduler_images
Dockerfile address: https://github.com/qiaozhanwei/escheduler_dockerfile/tree/master/docker_escheduler
------
## Q : Need to pay attention to the problem in install.sh
A: 1, if the replacement variable contains special characters, **use the \ transfer character to transfer**
2, installPath="/data1_1T/escheduler", **this directory can not be the same as the install.sh directory currently installed with one click.**
3, deployUser = "escheduler", **the deployment user must have sudo privileges**, because the worker is executed by sudo -u tenant sh xxx.command
4, monitorServerState = "false", whether the service monitoring script is started, the default is not to start the service monitoring script. **If the service monitoring script is started, the master and worker services are monitored every 5 minutes, and if the machine is down, it will automatically restart.**
5, hdfsStartupSate="false", whether to enable HDFS resource upload function. The default is not enabled. **If it is not enabled, the resource center cannot be used.** If enabled, you need to configure the configuration of fs.defaultFS and yarn in conf/common/hadoop/hadoop.properties. If you use namenode HA, you need to copy core-site.xml and hdfs-site.xml to the conf root directory.
Note: **The 1.0.x version does not automatically create the hdfs root directory, you need to create it yourself, and you need to deploy the user with hdfs operation permission.**
---
## Q : Process definition and process instance offline exception
A : For **versions prior to 1.0.4**, modify the code under the escheduler-api cn.escheduler.api.quartz package.
```
public boolean deleteJob(String jobName, String jobGroupName) {
lock.writeLock().lock();
try {
JobKey jobKey = new JobKey(jobName,jobGroupName);
if(scheduler.checkExists(jobKey)){
logger.info("try to delete job, job name: {}, job group name: {},", jobName, jobGroupName);
return scheduler.deleteJob(jobKey);
}else {
return true;
}
} catch (SchedulerException e) {
logger.error(String.format("delete job : %s failed",jobName), e);
} finally {
lock.writeLock().unlock();
}
return false;
}
```
---
## Q: Can the tenant created before the HDFS startup use the resource center normally?
A: No. Because the tenant created by HDFS is not started, the tenant directory will not be registered in HDFS. So the last resource will report an error.
## Q: In the multi-master and multi-worker state, the service is lost, how to be fault-tolerant
A: **Note:** **Master monitors Master and Worker services.**
1,If the Master service is lost, other Masters will take over the process of the hanged Master and continue to monitor the Worker task status.
2,If the Worker service is lost, the Master will monitor that the Worker service is gone. If there is a Yarn task, the Kill Yarn task will be retried.
Please see the fault-tolerant design for details:https://analysys.github.io/easyscheduler_docs_cn/%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1.html#%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1
---
## Q : Fault tolerance for a machine distributed by Master and Worker
A: The 1.0.3 version only implements the fault tolerance of the Master startup process, and does not take the Worker Fault Tolerance. That is to say, if the Worker hangs, no Master exists. There will be problems with this process. We will add Master and Worker startup fault tolerance in version **1.1.0** to fix this problem. If you want to manually modify this problem, you need to **modify the running task for the running worker task that is running the process across the restart and has been dropped. The running process is set to the failed state across the restart**. Then resume the process from the failed node.
---
## Q : Timing is easy to set to execute every second
A : Note when setting the timing. If the first digit (* * * * * ? *) is set to *, it means execution every second. **We will add a list of recently scheduled times in version 1.1.0.** You can see the last 5 running times online at http://cron.qqe2.com/
## Q: Is there a valid time range for timing?
A: Yes, **if the timing start and end time is the same time, then this timing will be invalid timing. If the end time of the start and end time is smaller than the current time, it is very likely that the timing will be automatically deleted.**
## Q : There are several implementations of task dependencies
A: 1, the task dependency between **DAG**, is **from the zero degree** of the DAG segmentation
2, there are **task dependent nodes**, you can achieve cross-process tasks or process dependencies, please refer to the (DEPENDENT) node:https://analysys.github.io/easyscheduler_docs_cn/%E7%B3%BB%E7%BB%9F%E4%BD%BF%E7%94%A8%E6%89%8B%E5%86%8C.html#%E4%BB%BB%E5%8A%A1%E8%8A%82%E7%82%B9%E7%B1%BB%E5%9E%8B%E5%92%8C%E5%8F%82%E6%95%B0%E8%AE%BE%E7%BD%AE
Note: **Cross-project processes or task dependencies are not supported**
## Q: There are several ways to start the process definition.
A: 1, in **the process definition list**, click the **Start** button.
2, **the process definition list adds a timer**, scheduling start process definition.
3, process definition **view or edit** the DAG page, any **task node right click** Start process definition.
4, you can define DAG editing for the process, set the running flag of some tasks to **prohibit running**, when the process definition is started, the connection of the node will be removed from the DAG.
## Q : Python task setting Python version
A: 1,**for the version after 1.0.3** only need to modify PYTHON_HOME in conf/env/.escheduler_env.sh
```
export PYTHON_HOME=/bin/python
```
Note: This is **PYTHON_HOME** , which is the absolute path of the python command, not the simple PYTHON_HOME. Also note that when exporting the PATH, you need to directly
```
export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH
```
2,For versions prior to 1.0.3, the Python task only supports the Python version of the system. It does not support specifying the Python version.
## Q:Worker Task will generate a child process through sudo -u tenant sh xxx.command, will kill when kill
A: We will add the kill task in 1.0.4 and kill all the various child processes generated by the task.
## Q : How to use the queue in EasyScheduler, what does the user queue and tenant queue mean?
A : The queue in the EasyScheduler can be configured on the user or the tenant. **The priority of the queue specified by the user is higher than the priority of the tenant queue.** For example, to specify a queue for an MR task, the queue is specified by mapreduce.job.queuename.
Note: When using the above method to specify the queue, the MR uses the following methods:
```
Configuration conf = new Configuration();
GenericOptionsParser optionParser = new GenericOptionsParser(conf, args);
String[] remainingArgs = optionParser.getRemainingArgs();
```
If it is a Spark task --queue mode specifies the queue
## Q : Master or Worker reports the following alarm

A : Change the value of master.properties **master.reserved.memory** under conf to a smaller value, say 0.1 or the value of worker.properties **worker.reserved.memory** is a smaller value, say 0.1
## Q: The hive version is 1.1.0+cdh5.15.0, and the SQL hive task connection is reported incorrectly.
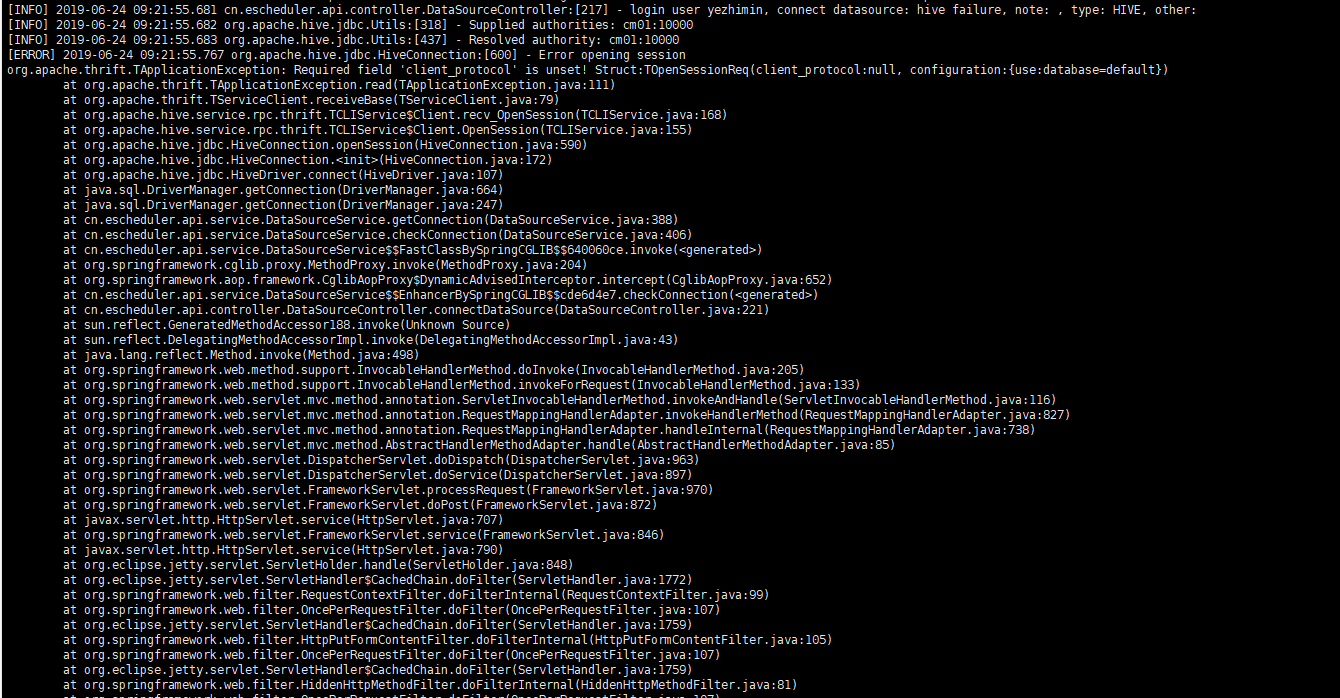
A : Will hive pom
```
org.apache.hive
hive-jdbc
2.1.0
```
change into
```
org.apache.hive
hive-jdbc
1.1.0
```