diff --git a/README.md b/README.md
index aaa7bf9529..18e2df8da3 100644
--- a/README.md
+++ b/README.md
@@ -37,7 +37,7 @@ Its main objectives are as follows:
Stability | Easy to use | Features | Scalability |
-- | -- | -- | --
Decentralized multi-master and multi-worker | Visualization process defines key information such as task status, task type, retry times, task running machine, visual variables and so on at a glance. | Support pause, recover operation | support custom task types
-HA is supported by itself | All process definition operations are visualized, dragging tasks to draw DAGs, configuring data sources and resources. At the same time, for third-party systems, the api mode operation is provided. | Users on easyscheduler can achieve many-to-one or one-to-one mapping relationship through tenants and Hadoop users, which is very important for scheduling large data jobs. " Supports traditional shell tasks, while supporting large data platform task scheduling: MR, Spark, SQL (mysql, postgresql, hive, sparksql), Python, Procedure, Sub_Process | The scheduler uses distributed scheduling, and the overall scheduling capability will increase linearly with the scale of the cluster. Master and Worker support dynamic online and offline.
+HA is supported by itself | All process definition operations are visualized, dragging tasks to draw DAGs, configuring data sources and resources. At the same time, for third-party systems, the api mode operation is provided. | Users on easyscheduler can achieve many-to-one or one-to-one mapping relationship through tenants and Hadoop users, which is very important for scheduling large data jobs. " | The scheduler uses distributed scheduling, and the overall scheduling capability will increase linearly with the scale of the cluster. Master and Worker support dynamic online and offline.
Overload processing: Task queue mechanism, the number of schedulable tasks on a single machine can be flexibly configured, when too many tasks will be cached in the task queue, will not cause machine jam. | One-click deployment | Supports traditional shell tasks, and also support big data platform task scheduling: MR, Spark, SQL (mysql, postgresql, hive, sparksql), Python, Procedure, Sub_Process | |
@@ -62,7 +62,7 @@ Overload processing: Task queue mechanism, the number of schedulable tasks on a
- [**Upgrade document**](https://analysys.github.io/easyscheduler_docs_cn/升级文档.html?_blank "Upgrade document")
-- Online Demo
+- Online Demo
More documentation please refer to [EasyScheduler online documentation]
diff --git a/README_zh_CN.md b/README_zh_CN.md
index 9835b616c2..91cdd04669 100644
--- a/README_zh_CN.md
+++ b/README_zh_CN.md
@@ -52,7 +52,7 @@ Easy Scheduler
- [**升级文档**](https://analysys.github.io/easyscheduler_docs_cn/升级文档.html?_blank "升级文档")
-- 我要体验
+- 我要体验
更多文档请参考 easyscheduler中文在线文档
diff --git a/docs/en_US/1.0.1-release.md b/docs/en_US/1.0.1-release.md
index 9bebfcca9b..8613d9352e 100644
--- a/docs/en_US/1.0.1-release.md
+++ b/docs/en_US/1.0.1-release.md
@@ -1,6 +1,6 @@
Easy Scheduler Release 1.0.1
===
-Easy Scheduler 1.0.2 is the second version in the 1.x series. The update is as follows:
+Easy Scheduler 1.0.1 is the second version in the 1.x series. The update is as follows:
- 1,outlook TSL email support
- 2,servlet and protobuf jar conflict resolution
diff --git a/docs/en_US/1.0.4-release.md b/docs/en_US/1.0.4-release.md
new file mode 100644
index 0000000000..f7b1089cc9
--- /dev/null
+++ b/docs/en_US/1.0.4-release.md
@@ -0,0 +1,2 @@
+# 1.0.4 release
+
diff --git a/docs/en_US/1.0.5-release.md b/docs/en_US/1.0.5-release.md
new file mode 100644
index 0000000000..ce945e28b1
--- /dev/null
+++ b/docs/en_US/1.0.5-release.md
@@ -0,0 +1,2 @@
+# 1.0.5 release
+
diff --git a/docs/en_US/EasyScheduler-FAQ.md b/docs/en_US/EasyScheduler-FAQ.md
index bbff613e26..b55b0e2413 100644
--- a/docs/en_US/EasyScheduler-FAQ.md
+++ b/docs/en_US/EasyScheduler-FAQ.md
@@ -28,7 +28,7 @@ A: Support most mailboxes, qq, 163, 126, 139, outlook, aliyun, etc. are supporte
## Q: What are the common system variable time parameters and how do I use them?
-A: Please refer to https://analysys.github.io/easyscheduler_docs_cn/%E7%B3%BB%E7%BB%9F%E4%BD%BF%E7%94%A8%E6%89%8B%E5%86%8C.html#%E7%B3%BB%E7%BB%9F%E5%8F%82%E6%95%B0
+A: Please refer to 'System parameter' in the system-manual
---
@@ -46,7 +46,7 @@ A: Use **the administrator** to create a Worker group, **specify the Worker grou
## Q: Priority of the task
-A: We also support t**he priority of processes and tasks**. Priority We have five levels of **HIGHEST, HIGH, MEDIUM, LOW and LOWEST**. **You can set the priority between different process instances, or you can set the priority of different task instances in the same process instance.** For details, please refer to the task priority design https://analysys.github.io/easyscheduler_docs_cn/%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1.html#%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1
+A: We also support **the priority of processes and tasks**. Priority We have five levels of **HIGHEST, HIGH, MEDIUM, LOW and LOWEST**. **You can set the priority between different process instances, or you can set the priority of different task instances in the same process instance.** For details, please refer to the task priority design in the architecture-design.
----
@@ -163,7 +163,7 @@ A: **Note:** **Master monitors Master and Worker services.**
2,If the Worker service is lost, the Master will monitor that the Worker service is gone. If there is a Yarn task, the Kill Yarn task will be retried.
-Please see the fault-tolerant design for details:https://analysys.github.io/easyscheduler_docs_cn/%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1.html#%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1
+Please see the fault-tolerant design in the architecture for details.
---
@@ -189,7 +189,7 @@ A: Yes, **if the timing start and end time is the same time, then this timing wi
A: 1, the task dependency between **DAG**, is **from the zero degree** of the DAG segmentation
- 2, there are **task dependent nodes**, you can achieve cross-process tasks or process dependencies, please refer to the (DEPENDENT) node:https://analysys.github.io/easyscheduler_docs_cn/%E7%B3%BB%E7%BB%9F%E4%BD%BF%E7%94%A8%E6%89%8B%E5%86%8C.html#%E4%BB%BB%E5%8A%A1%E8%8A%82%E7%82%B9%E7%B1%BB%E5%9E%8B%E5%92%8C%E5%8F%82%E6%95%B0%E8%AE%BE%E7%BD%AE
+ 2, there are **task dependent nodes**, you can achieve cross-process tasks or process dependencies, please refer to the (DEPENDENT) node design in the system-manual.
Note: **Cross-project processes or task dependencies are not supported**
@@ -248,7 +248,7 @@ If it is a Spark task --queue mode specifies the queue
## Q : Master or Worker reports the following alarm
-  +
+ 
@@ -258,11 +258,10 @@ A : Change the value of master.properties **master.reserved.memory** under con
## Q: The hive version is 1.1.0+cdh5.15.0, and the SQL hive task connection is reported incorrectly.
- 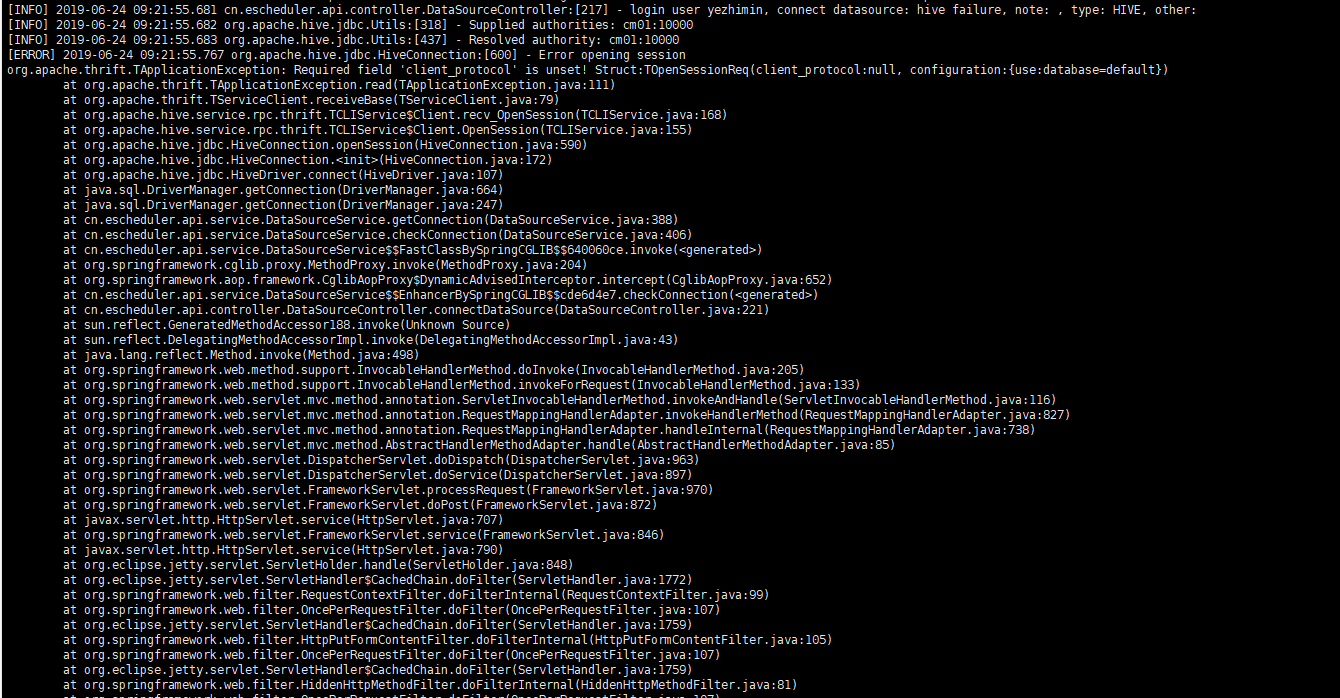 +
+ 
-
A : Will hive pom
```
diff --git a/docs/en_US/README.md b/docs/en_US/README.md
index 785b5e3cfa..05380d0212 100644
--- a/docs/en_US/README.md
+++ b/docs/en_US/README.md
@@ -38,7 +38,7 @@ Its main objectives are as follows:
Stability | Easy to use | Features | Scalability |
-- | -- | -- | --
Decentralized multi-master and multi-worker | Visualization process defines key information such as task status, task type, retry times, task running machine, visual variables and so on at a glance. | Support pause, recover operation | support custom task types
-HA is supported by itself | All process definition operations are visualized, dragging tasks to draw DAGs, configuring data sources and resources. At the same time, for third-party systems, the api mode operation is provided. | Users on easyscheduler can achieve many-to-one or one-to-one mapping relationship through tenants and Hadoop users, which is very important for scheduling large data jobs. " Supports traditional shell tasks, while supporting large data platform task scheduling: MR, Spark, SQL (mysql, postgresql, hive, sparksql), Python, Procedure, Sub_Process | The scheduler uses distributed scheduling, and the overall scheduling capability will increase linearly with the scale of the cluster. Master and Worker support dynamic online and offline.
+HA is supported by itself | All process definition operations are visualized, dragging tasks to draw DAGs, configuring data sources and resources. At the same time, for third-party systems, the api mode operation is provided. | Users on easyscheduler can achieve many-to-one or one-to-one mapping relationship through tenants and Hadoop users, which is very important for scheduling large data jobs. | The scheduler uses distributed scheduling, and the overall scheduling capability will increase linearly with the scale of the cluster. Master and Worker support dynamic online and offline.
Overload processing: Task queue mechanism, the number of schedulable tasks on a single machine can be flexibly configured, when too many tasks will be cached in the task queue, will not cause machine jam. | One-click deployment | Supports traditional shell tasks, and also support big data platform task scheduling: MR, Spark, SQL (mysql, postgresql, hive, sparksql), Python, Procedure, Sub_Process | |
@@ -55,17 +55,17 @@ Overload processing: Task queue mechanism, the number of schedulable tasks on a
### Document
-- Backend deployment documentation
+- Backend deployment documentation
-- Front-end deployment documentation
+- Front-end deployment documentation
-- [**User manual**](https://analysys.github.io/easyscheduler_docs_cn/系统使用手册.html?_blank "User manual")
+- [**User manual**](https://analysys.github.io/easyscheduler_docs/system-manual.html?_blank "User manual")
-- [**Upgrade document**](https://analysys.github.io/easyscheduler_docs_cn/升级文档.html?_blank "Upgrade document")
+- [**Upgrade document**](https://analysys.github.io/easyscheduler_docs/upgrade.html?_blank "Upgrade document")
- Online Demo
-More documentation please refer to [EasyScheduler online documentation]
+More documentation please refer to [EasyScheduler online documentation]
### Recent R&D plan
Work plan of Easy Scheduler: [R&D plan](https://github.com/analysys/EasyScheduler/projects/1), where `In Develop` card is the features of 1.1.0 version , TODO card is to be done (including feature ideas)
diff --git a/docs/en_US/SUMMARY.md b/docs/en_US/SUMMARY.md
new file mode 100644
index 0000000000..397a4a110c
--- /dev/null
+++ b/docs/en_US/SUMMARY.md
@@ -0,0 +1,50 @@
+# Summary
+
+* [Instruction](README.md)
+
+* Frontend Deployment
+ * [Preparations](frontend-deployment.md#Preparations)
+ * [Deployment](frontend-deployment.md#Deployment)
+ * [FAQ](frontend-deployment.md#FAQ)
+
+* Backend Deployment
+ * [Preparations](backend-deployment.md#Preparations)
+ * [Deployment](backend-deployment.md#Deployment)
+
+* [Quick Start](quick-start.md#Quick Start)
+
+* System Use Manual
+ * [Operational Guidelines](system-manual.md#Operational Guidelines)
+ * [Security](system-manual.md#Security)
+ * [Monitor center](system-manual.md#Monitor center)
+ * [Task Node Type and Parameter Setting](system-manual.md#Task Node Type and Parameter Setting)
+ * [System parameter](system-manual.md#System parameter)
+
+* [Architecture Design](architecture-design.md)
+
+* Front-end development
+ * [Development environment](frontend-development.md#Development environment)
+ * [Project directory structure](frontend-development.md#Project directory structure)
+ * [System function module](frontend-development.md#System function module)
+ * [Routing and state management](frontend-development.md#Routing and state management)
+ * [specification](frontend-development.md#specification)
+ * [interface](frontend-development.md#interface)
+ * [Extended development](frontend-development.md#Extended development)
+
+* Backend development documentation
+ * [Environmental requirements](backend-development.md#Environmental requirements)
+ * [Project compilation](backend-development.md#Project compilation)
+* [Interface documentation](http://52.82.13.76:8888/escheduler/doc.html?language=en_US&lang=en)
+* FAQ
+ * [FAQ](EasyScheduler-FAQ.md)
+* EasyScheduler upgrade documentation
+ * [upgrade documentation](upgrade.md)
+* History release notes
+ * [1.1.0 release](1.1.0-release.md)
+ * [1.0.5 release](1.0.5-release.md)
+ * [1.0.4 release](1.0.4-release.md)
+ * [1.0.3 release](1.0.3-release.md)
+ * [1.0.2 release](1.0.2-release.md)
+ * [1.0.1 release](1.0.1-release.md)
+ * [1.0.0 release]
+
diff --git a/docs/en_US/Backend Deployment Document.md b/docs/en_US/backend-deployment.md
similarity index 89%
rename from docs/en_US/Backend Deployment Document.md
rename to docs/en_US/backend-deployment.md
index e353447fe8..f35c8d7a62 100644
--- a/docs/en_US/Backend Deployment Document.md
+++ b/docs/en_US/backend-deployment.md
@@ -2,12 +2,12 @@
There are two deployment modes for the backend:
-- 1. automatic deployment
-- 2. source code compile and then deployment
+- automatic deployment
+- source code compile and then deployment
-## 1、Preparations
+## Preparations
-Download the latest version of the installation package, download address: [gitee download](https://gitee.com/easyscheduler/EasyScheduler/attach_files/) , download escheduler-backend-x.x.x.tar.gz(back-end referred to as escheduler-backend),escheduler-ui-x.x.x.tar.gz(front-end referred to as escheduler-ui)
+Download the latest version of the installation package, download address: [gitee download](https://gitee.com/easyscheduler/EasyScheduler/attach_files/) or [github download](https://github.com/analysys/EasyScheduler/releases), download escheduler-backend-x.x.x.tar.gz(back-end referred to as escheduler-backend),escheduler-ui-x.x.x.tar.gz(front-end referred to as escheduler-ui)
@@ -27,9 +27,9 @@ Download the latest version of the installation package, download address: [gi
#### Preparations 2: Create deployment users
-- Deployment users are created on all machines that require deployment scheduling, because the worker service executes jobs in sudo-u {linux-user}, so deployment users need sudo privileges and are confidential.
+- Deployment users are created on all machines that require deployment scheduling, because the worker service executes jobs in `sudo-u {linux-user}`, so deployment users need sudo privileges and are confidential.
-```Deployment account
+```
vi /etc/sudoers
# For example, the deployment user is an escheduler account
@@ -50,7 +50,7 @@ Configure SSH secret-free login on deployment machines and other installation ma
Execute the following command to create database and account
- ```sql
+ ```
CREATE DATABASE escheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL PRIVILEGES ON escheduler.* TO '{user}'@'%' IDENTIFIED BY '{password}';
GRANT ALL PRIVILEGES ON escheduler.* TO '{user}'@'localhost' IDENTIFIED BY '{password}';
@@ -65,7 +65,9 @@ Configure SSH secret-free login on deployment machines and other installation ma
spring.datasource.username
spring.datasource.password
```
+
Execute scripts for creating tables and importing basic data
+
```
sh ./script/create_escheduler.sh
```
@@ -100,10 +102,10 @@ install.sh : One-click deployment script
- If you use hdfs-related functions, you need to copy**hdfs-site.xml** and **core-site.xml** to the conf directory
-## 2、Deployment
+## Deployment
Automated deployment is recommended, and experienced partners can use source deployment as well.
-### 2.1 Automated Deployment
+### Automated Deployment
- Install zookeeper tools
@@ -128,7 +130,7 @@ If all services are normal, the automatic deployment is successful
After successful deployment, the log can be viewed and stored in a specified folder.
-```log path
+```logPath
logs/
├── escheduler-alert-server.log
├── escheduler-master-server.log
@@ -137,7 +139,7 @@ After successful deployment, the log can be viewed and stored in a specified fol
|—— escheduler-logger-server.log
```
-### 2.2 Compile source code to deploy
+### Compile source code to deploy
After downloading the release version of the source package, unzip it into the root directory
@@ -152,7 +154,7 @@ After downloading the release version of the source package, unzip it into the r
After normal compilation, ./target/escheduler-{version}/ is generated in the current directory
-### 2.3 Start-and-stop services commonly used in systems (for service purposes, please refer to System Architecture Design for details)
+### Start-and-stop services commonly used in systems (for service purposes, please refer to System Architecture Design for details)
* stop all services in the cluster
@@ -164,38 +166,38 @@ After normal compilation, ./target/escheduler-{version}/ is generated in the cur
* start and stop one master server
-```start master
+```master
sh ./bin/escheduler-daemon.sh start master-server
sh ./bin/escheduler-daemon.sh stop master-server
```
* start and stop one worker server
-```start worker
+```worker
sh ./bin/escheduler-daemon.sh start worker-server
sh ./bin/escheduler-daemon.sh stop worker-server
```
* start and stop api server
-```start Api
+```Api
sh ./bin/escheduler-daemon.sh start api-server
sh ./bin/escheduler-daemon.sh stop api-server
```
* start and stop logger server
-```start Logger
+```Logger
sh ./bin/escheduler-daemon.sh start logger-server
sh ./bin/escheduler-daemon.sh stop logger-server
```
* start and stop alert server
-```start Alert
+```Alert
sh ./bin/escheduler-daemon.sh start alert-server
sh ./bin/escheduler-daemon.sh stop alert-server
```
-## 3、Database Upgrade
+## Database Upgrade
Database upgrade is a function added in version 1.0.2. The database can be upgraded automatically by executing the following command:
```upgrade
diff --git a/docs/en_US/Backend development documentation.md b/docs/en_US/backend-development.md
similarity index 100%
rename from docs/en_US/Backend development documentation.md
rename to docs/en_US/backend-development.md
diff --git a/docs/en_US/book.json b/docs/en_US/book.json
new file mode 100644
index 0000000000..c05811289d
--- /dev/null
+++ b/docs/en_US/book.json
@@ -0,0 +1,23 @@
+{
+ "title": "EasyScheduler",
+ "author": "",
+ "description": "Scheduler",
+ "language": "en-US",
+ "gitbook": "3.2.3",
+ "styles": {
+ "website": "./styles/website.css"
+ },
+ "structure": {
+ "readme": "README.md"
+ },
+ "plugins":[
+ "expandable-chapters",
+ "insert-logo-link"
+ ],
+ "pluginsConfig": {
+ "insert-logo-link": {
+ "src": "http://geek.analysys.cn/static/upload/236/2019-03-29/379450b4-7919-4707-877c-4d33300377d4.png",
+ "url": "https://github.com/analysys/EasyScheduler"
+ }
+ }
+}
\ No newline at end of file
diff --git a/docs/en_US/Frontend Deployment Document.md b/docs/en_US/frontend-deployment.md
similarity index 93%
rename from docs/en_US/Frontend Deployment Document.md
rename to docs/en_US/frontend-deployment.md
index d4060170a6..46372c2d88 100644
--- a/docs/en_US/Frontend Deployment Document.md
+++ b/docs/en_US/frontend-deployment.md
@@ -1,10 +1,11 @@
-# Front End Deployment Document
+# frontend-deployment
The front-end has three deployment modes: automated deployment, manual deployment and compiled source deployment.
-## 1、Preparations
+## Preparations
+
#### Download the installation package
Please download the latest version of the installation package, download address: [gitee](https://gitee.com/easyscheduler/EasyScheduler/attach_files/)
@@ -14,10 +15,11 @@ After downloading escheduler-ui-x.x.x.tar.gz,decompress`tar -zxvf escheduler-u
-## 2、Deployment
+## Deployment
+
Automated deployment is recommended for either of the following two ways
-### 2.1 Automated Deployment
+### Automated Deployment
Edit the installation file`vi install-escheduler-ui.sh` in the` escheduler-ui` directory
@@ -36,7 +38,7 @@ esc_proxy_port="http://192.168.xx.xx:12345"
under this directory, execute`./install-escheduler-ui.sh`
-### 2.2 Manual Deployment
+### Manual Deployment
Install epel source `yum install epel-release -y`
@@ -44,10 +46,13 @@ Install Nginx `yum install nginx -y`
> #### Nginx configuration file address
+
```
/etc/nginx/conf.d/default.conf
```
+
> #### Configuration information (self-modifying)
+
```
server {
listen 8888;# access port
@@ -81,7 +86,9 @@ server {
}
}
```
+
> #### Restart the Nginx service
+
```
systemctl restart nginx
```
@@ -95,9 +102,11 @@ systemctl restart nginx
- status `systemctl status nginx`
-## Front-end Frequently Asked Questions
-#### 1.Upload file size limit
+## FAQ
+#### Upload file size limit
+
Edit the configuration file `vi /etc/nginx/nginx.conf`
+
```
# change upload size
client_max_body_size 1024m
diff --git a/docs/en_US/Frontend development documentation.md b/docs/en_US/frontend-development.md
similarity index 100%
rename from docs/en_US/Frontend development documentation.md
rename to docs/en_US/frontend-development.md
diff --git a/docs/en_US/images/auth-project.png b/docs/en_US/images/auth-project.png
new file mode 100644
index 0000000000..40c6fecb0e
Binary files /dev/null and b/docs/en_US/images/auth-project.png differ
diff --git a/docs/en_US/images/complement.png b/docs/en_US/images/complement.png
new file mode 100644
index 0000000000..f5d87ab57a
Binary files /dev/null and b/docs/en_US/images/complement.png differ
diff --git a/docs/en_US/images/depend-b-and-c.png b/docs/en_US/images/depend-b-and-c.png
new file mode 100644
index 0000000000..693725d30f
Binary files /dev/null and b/docs/en_US/images/depend-b-and-c.png differ
diff --git a/docs/en_US/images/depend-last-tuesday.png b/docs/en_US/images/depend-last-tuesday.png
new file mode 100644
index 0000000000..53fc99f5fb
Binary files /dev/null and b/docs/en_US/images/depend-last-tuesday.png differ
diff --git a/docs/en_US/images/depend-week.png b/docs/en_US/images/depend-week.png
new file mode 100644
index 0000000000..567648168c
Binary files /dev/null and b/docs/en_US/images/depend-week.png differ
diff --git a/docs/en_US/images/save-definition.png b/docs/en_US/images/save-definition.png
new file mode 100644
index 0000000000..ffde6b4742
Binary files /dev/null and b/docs/en_US/images/save-definition.png differ
diff --git a/docs/en_US/images/save-global-parameters.png b/docs/en_US/images/save-global-parameters.png
new file mode 100644
index 0000000000..33454b6b64
Binary files /dev/null and b/docs/en_US/images/save-global-parameters.png differ
diff --git a/docs/en_US/images/start-process.png b/docs/en_US/images/start-process.png
new file mode 100644
index 0000000000..3d535f3937
Binary files /dev/null and b/docs/en_US/images/start-process.png differ
diff --git a/docs/en_US/images/timing.png b/docs/en_US/images/timing.png
new file mode 100644
index 0000000000..a1642b73d1
Binary files /dev/null and b/docs/en_US/images/timing.png differ
diff --git a/docs/en_US/Quick Start.md b/docs/en_US/quick-start.md
similarity index 99%
rename from docs/en_US/Quick Start.md
rename to docs/en_US/quick-start.md
index 1c864bc0ff..a1dc255345 100644
--- a/docs/en_US/Quick Start.md
+++ b/docs/en_US/quick-start.md
@@ -1,6 +1,7 @@
# Quick Start
* Administrator user login
+
> Address:192.168.xx.xx:8888 Username and password:admin/escheduler123
diff --git a/docs/en_US/System manual.md b/docs/en_US/system-manual.md
similarity index 93%
rename from docs/en_US/System manual.md
rename to docs/en_US/system-manual.md
index 89a2a854db..d5a63af80d 100644
--- a/docs/en_US/System manual.md
+++ b/docs/en_US/system-manual.md
@@ -1,10 +1,5 @@
# System Use Manual
-
-## Quick Start
-
- > Refer to[ Quick Start ]( Quick-Start.md)
-
## Operational Guidelines
### Create a project
@@ -47,7 +42,7 @@
- Click "Save", enter the name of the process definition, the description of the process definition, and set the global parameters.
-  +
+ 
- For other types of nodes, refer to [task node types and parameter settings](#task node types and parameter settings)
@@ -66,13 +61,15 @@
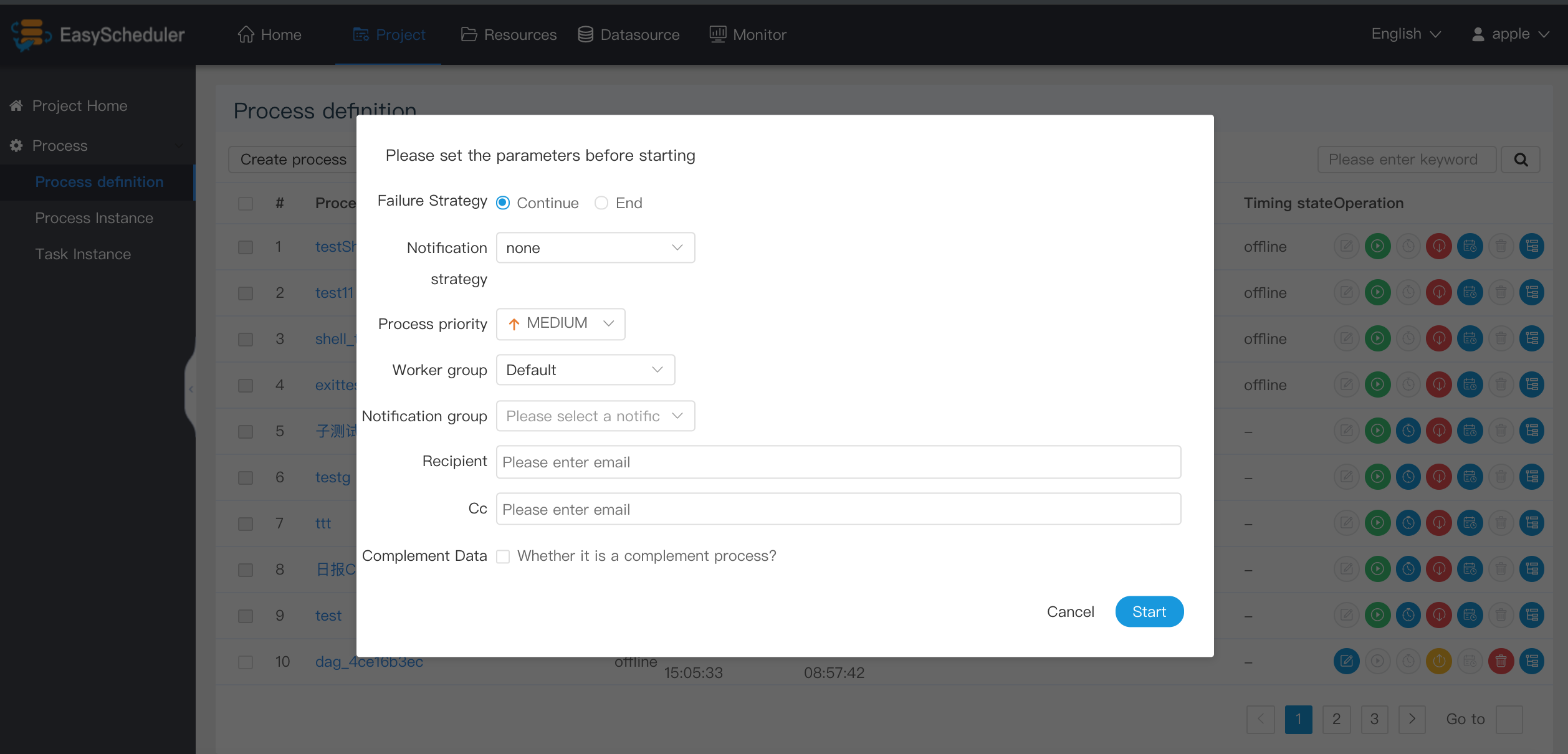
* Notification group: When the process ends or fault tolerance occurs, process information is sent to all members of the notification group by mail.
* Recipient: Enter the mailbox and press Enter key to save. When the process ends and fault tolerance occurs, an alert message is sent to the recipient list.
* Cc: Enter the mailbox and press Enter key to save. When the process is over and fault-tolerant occurs, alarm messages are copied to the copier list.
-
-  +
+
+
+
+ 
* Complement: To implement the workflow definition of a specified date, you can select the time range of the complement (currently only support for continuous days), such as the data from May 1 to May 10, as shown in the figure:
+
-  +
+ 
> Complement execution mode includes serial execution and parallel execution. In serial mode, the complement will be executed sequentially from May 1 to May 10. In parallel mode, the tasks from May 1 to May 10 will be executed simultaneously.
@@ -80,8 +77,9 @@
### Timing Process Definition
- Create Timing: "Process Definition - > Timing"
- Choose start-stop time, in the start-stop time range, regular normal work, beyond the scope, will not continue to produce timed workflow instances.
+
-  +
+ 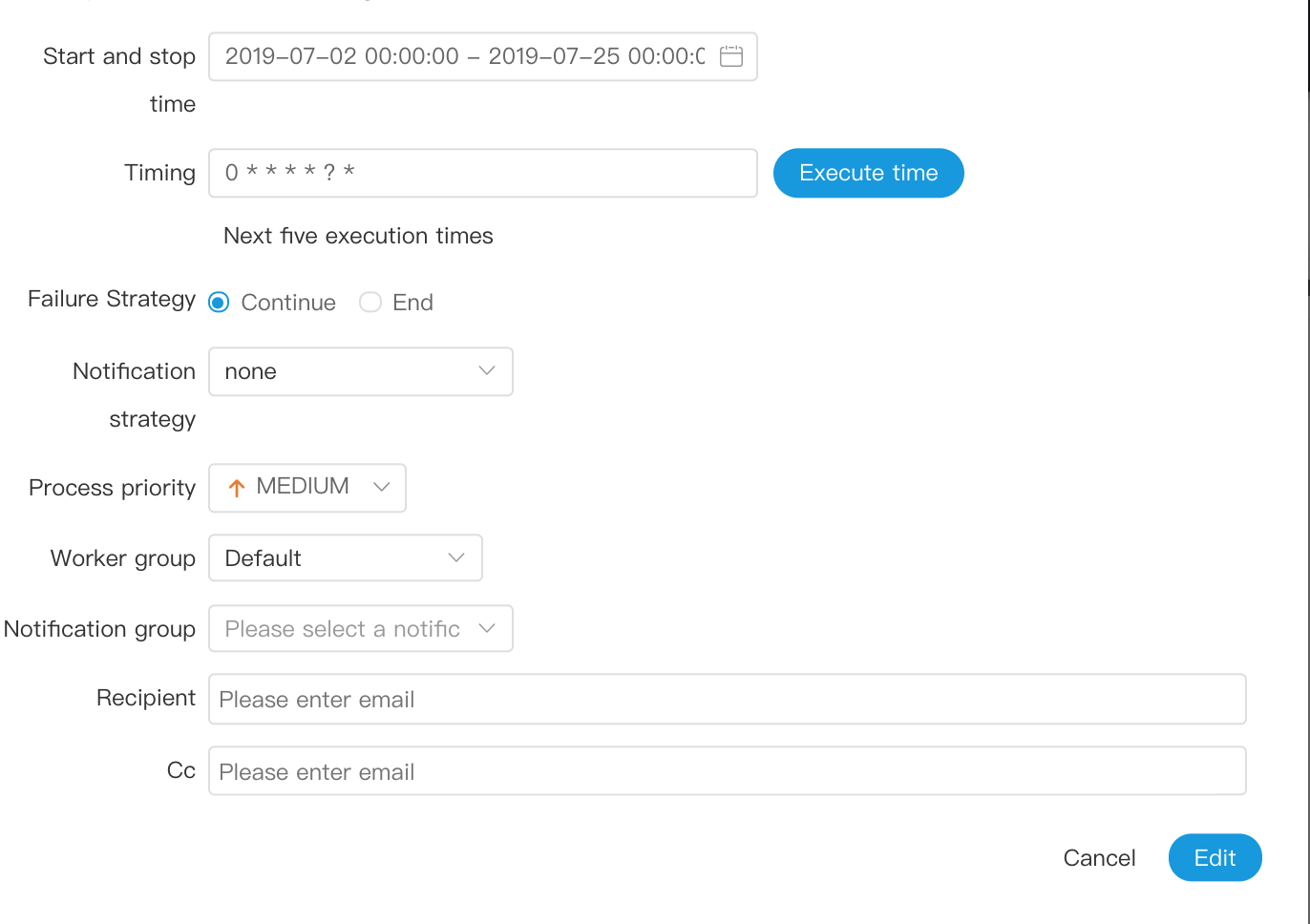
- Add a timer to be executed once a day at 5:00 a.m. as shown below:
@@ -211,7 +209,7 @@
-Note: If **kerberos** is turned on, you need to fill in **Principal **
+Note: If **kerberos** is turned on, you need to fill in **Principal**

@@ -330,7 +328,7 @@ conf/common/hadoop.properties
 -## Security (Privilege System)
+## Security
- The security has the functions of queue management, tenant management, user management, warning group management, worker group manager, token manage and other functions. It can also authorize resources, data sources, projects, etc.
- Administrator login, default username password: admin/escheduler 123
@@ -433,11 +431,8 @@ conf/common/hadoop.properties
- 2.Select the project button to authorize the project
-## Security (Privilege System)
+## Security
- The security has the functions of queue management, tenant management, user management, warning group management, worker group manager, token manage and other functions. It can also authorize resources, data sources, projects, etc.
- Administrator login, default username password: admin/escheduler 123
@@ -433,11 +431,8 @@ conf/common/hadoop.properties
- 2.Select the project button to authorize the project
-  -
-
-
-
-
-
-
-
+ 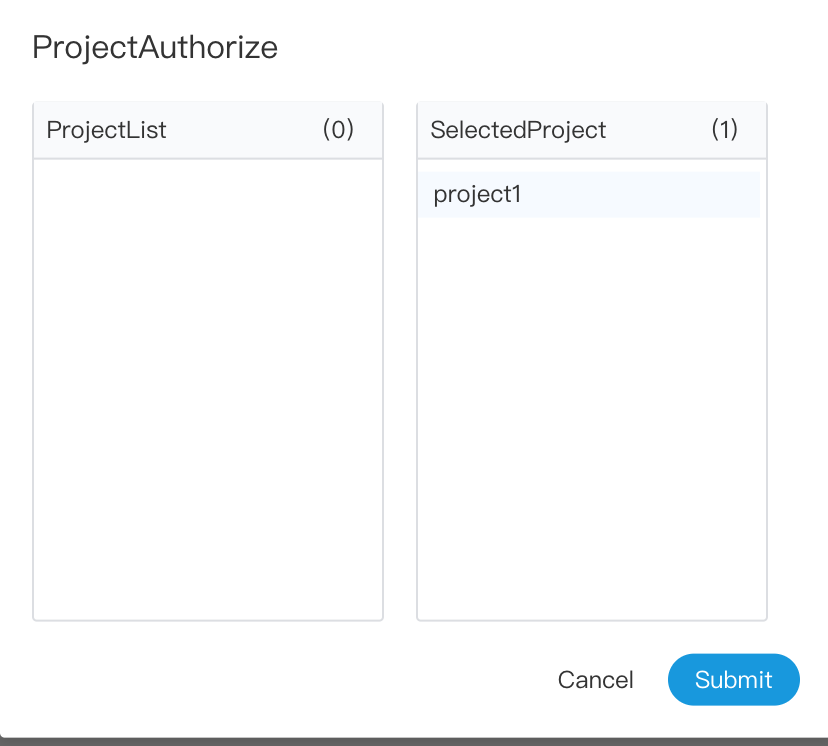 +
### Monitor center
- Service management is mainly to monitor and display the health status and basic information of each service in the system.
@@ -474,7 +469,7 @@ conf/common/hadoop.properties
### Shell
- The shell node, when the worker executes, generates a temporary shell script, which is executed by a Linux user with the same name as the tenant.
-> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
+
### Monitor center
- Service management is mainly to monitor and display the health status and basic information of each service in the system.
@@ -474,7 +469,7 @@ conf/common/hadoop.properties
### Shell
- The shell node, when the worker executes, generates a temporary shell script, which is executed by a Linux user with the same name as the tenant.
-> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
 @@ -506,7 +501,7 @@ conf/common/hadoop.properties
- Dependent nodes are **dependent checking nodes**. For example, process A depends on the successful execution of process B yesterday, and the dependent node checks whether process B has a successful execution instance yesterday.
-> Drag the  ask node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  ask node in the toolbar onto the palette and double-click the task node as follows:
@@ -506,7 +501,7 @@ conf/common/hadoop.properties
- Dependent nodes are **dependent checking nodes**. For example, process A depends on the successful execution of process B yesterday, and the dependent node checks whether process B has a successful execution instance yesterday.
-> Drag the  ask node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  ask node in the toolbar onto the palette and double-click the task node as follows:
 @@ -515,26 +510,24 @@ conf/common/hadoop.properties
> Dependent nodes provide logical judgment functions, such as checking whether yesterday's B process was successful or whether the C process was successfully executed.
@@ -515,26 +510,24 @@ conf/common/hadoop.properties
> Dependent nodes provide logical judgment functions, such as checking whether yesterday's B process was successful or whether the C process was successfully executed.
- 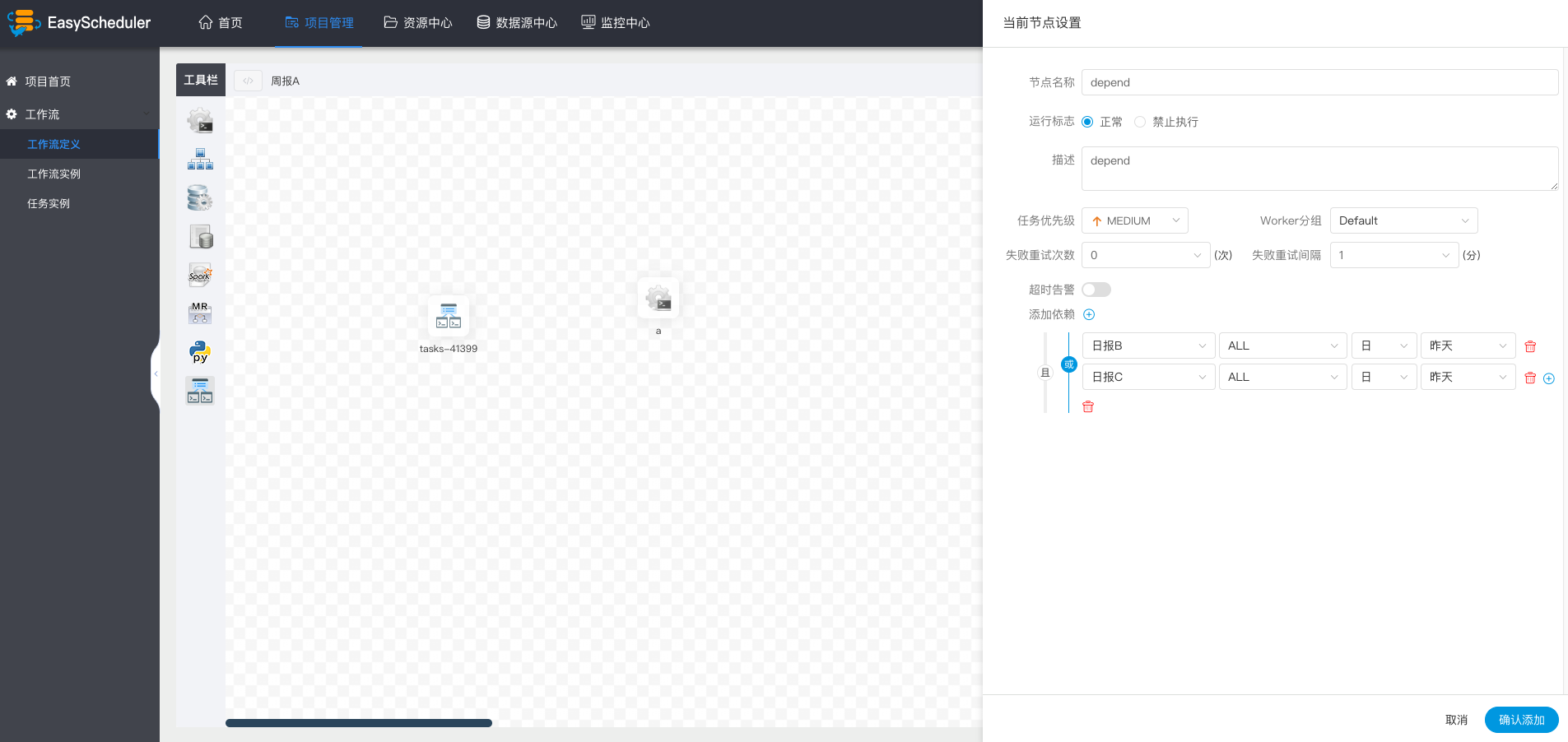 +
+ 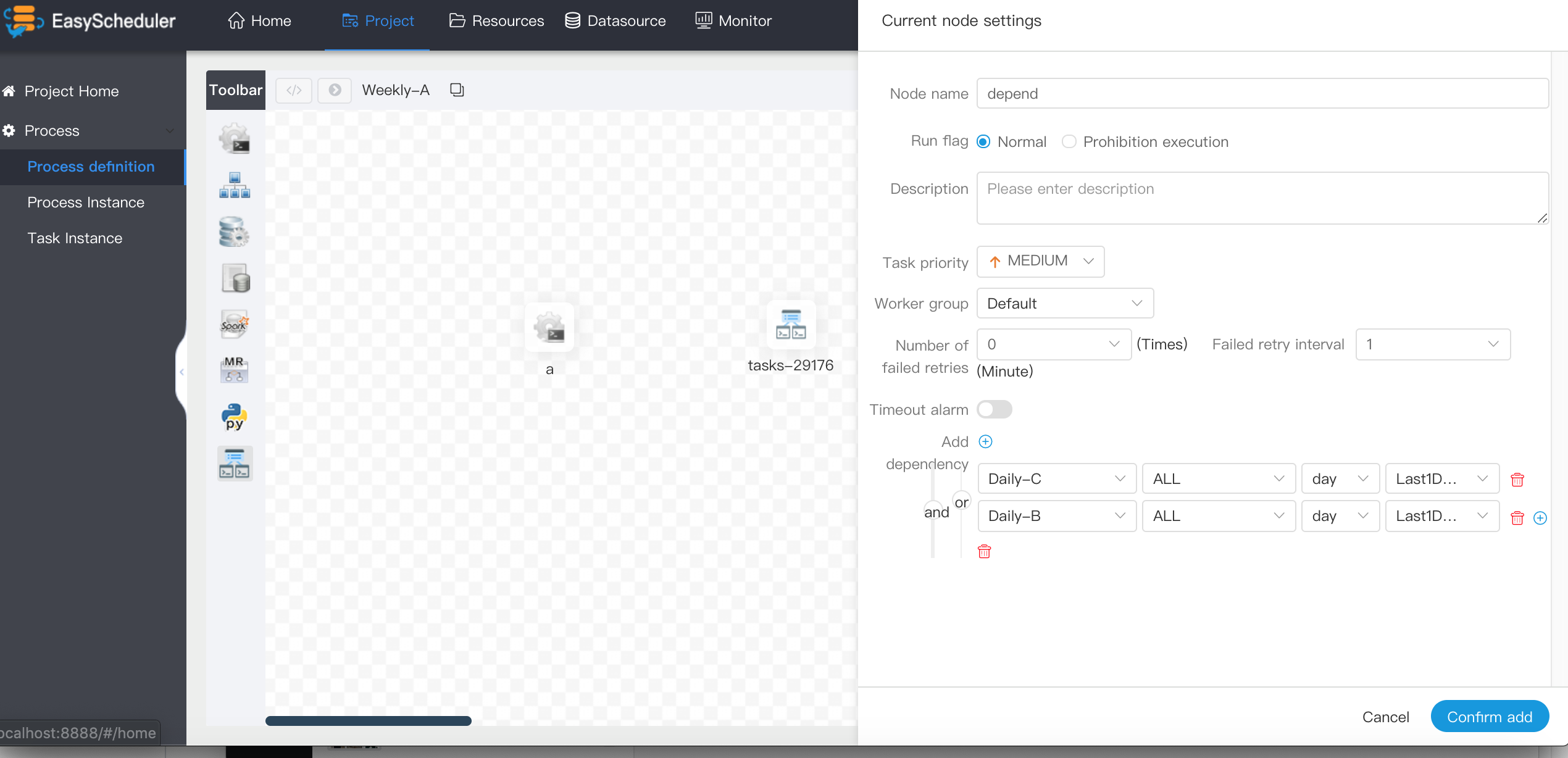
- > For example, process A is a weekly task and process B and C are daily tasks. Task A requires that task B and C be successfully executed every day of the week, as shown in the figure:
+ > For example, process A is a weekly task and process B and C are daily tasks. Task A requires that task B and C be successfully executed every day of the last week, as shown in the figure:
- 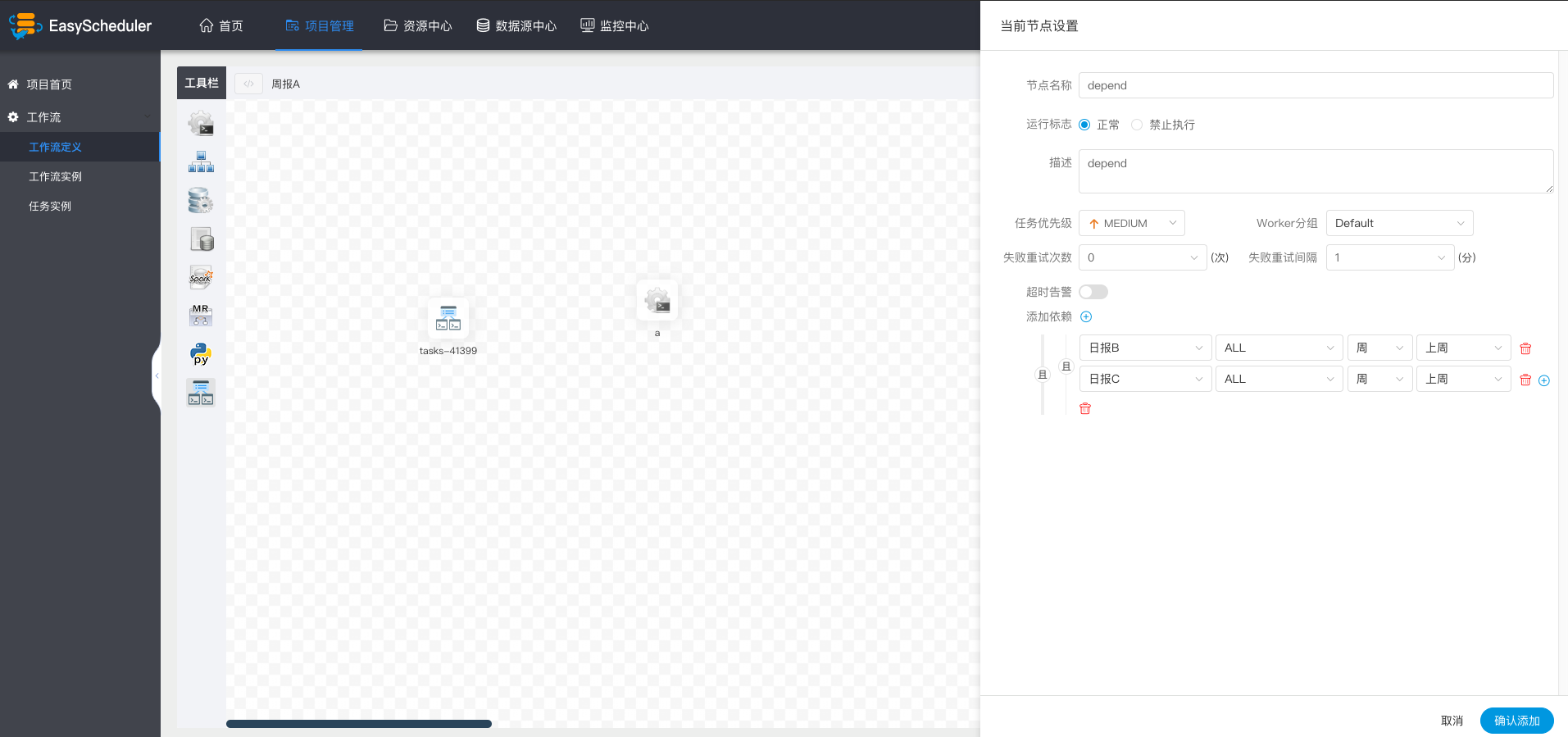 +
+ 
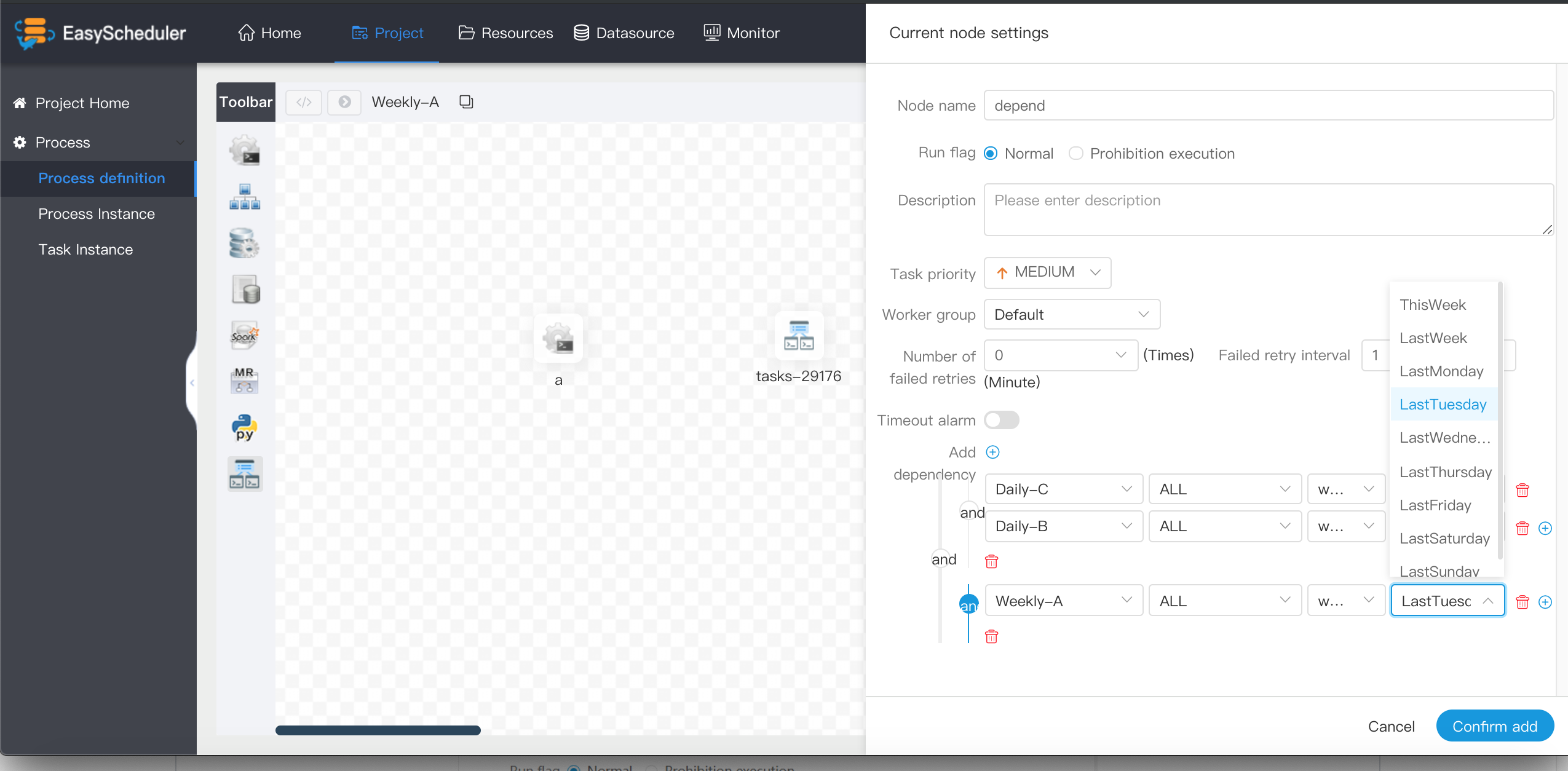
> If weekly A also needs to be implemented successfully on Tuesday:
- >
- >
- 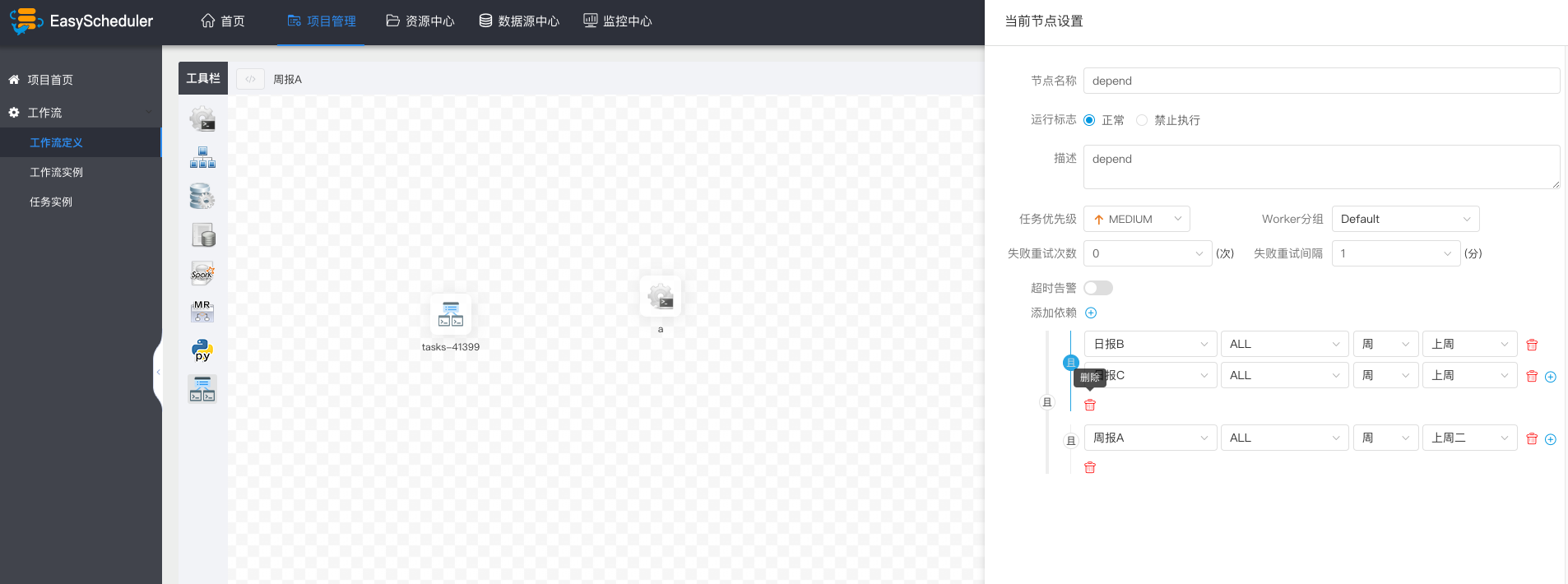 +
+ 
### PROCEDURE
- The procedure is executed according to the selected data source.
-> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
 @@ -551,7 +544,7 @@ conf/common/hadoop.properties
@@ -551,7 +544,7 @@ conf/common/hadoop.properties
- Executing the query SQL function, you can choose to send mail in the form of tables and attachments to the designated recipients.
-> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
 @@ -570,7 +563,7 @@ conf/common/hadoop.properties
- Through SPARK node, SPARK program can be directly executed. For spark node, worker will use `spark-submit` mode to submit tasks.
-> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
>
>
@@ -595,7 +588,7 @@ Note: JAVA and Scala are just used for identification, no difference. If it's a
- Using MR nodes, MR programs can be executed directly. For Mr nodes, worker submits tasks using `hadoop jar`
-> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
1. JAVA program
@@ -631,7 +624,7 @@ Note: JAVA and Scala are just used for identification, no difference. If it's a
-> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
@@ -570,7 +563,7 @@ conf/common/hadoop.properties
- Through SPARK node, SPARK program can be directly executed. For spark node, worker will use `spark-submit` mode to submit tasks.
-> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
>
>
@@ -595,7 +588,7 @@ Note: JAVA and Scala are just used for identification, no difference. If it's a
- Using MR nodes, MR programs can be executed directly. For Mr nodes, worker submits tasks using `hadoop jar`
-> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
1. JAVA program
@@ -631,7 +624,7 @@ Note: JAVA and Scala are just used for identification, no difference. If it's a
-> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
+> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
 @@ -690,9 +683,8 @@ Note: JAVA and Scala are just used for identification, no difference. If it's a
> User-defined parameters are divided into global parameters and local parameters. Global parameters are the global parameters passed when the process definition and process instance are saved. Global parameters can be referenced by local parameters of any task node in the whole process.
> For example:
-
@@ -690,9 +683,8 @@ Note: JAVA and Scala are just used for identification, no difference. If it's a
> User-defined parameters are divided into global parameters and local parameters. Global parameters are the global parameters passed when the process definition and process instance are saved. Global parameters can be referenced by local parameters of any task node in the whole process.
> For example:
-
-  +
+ 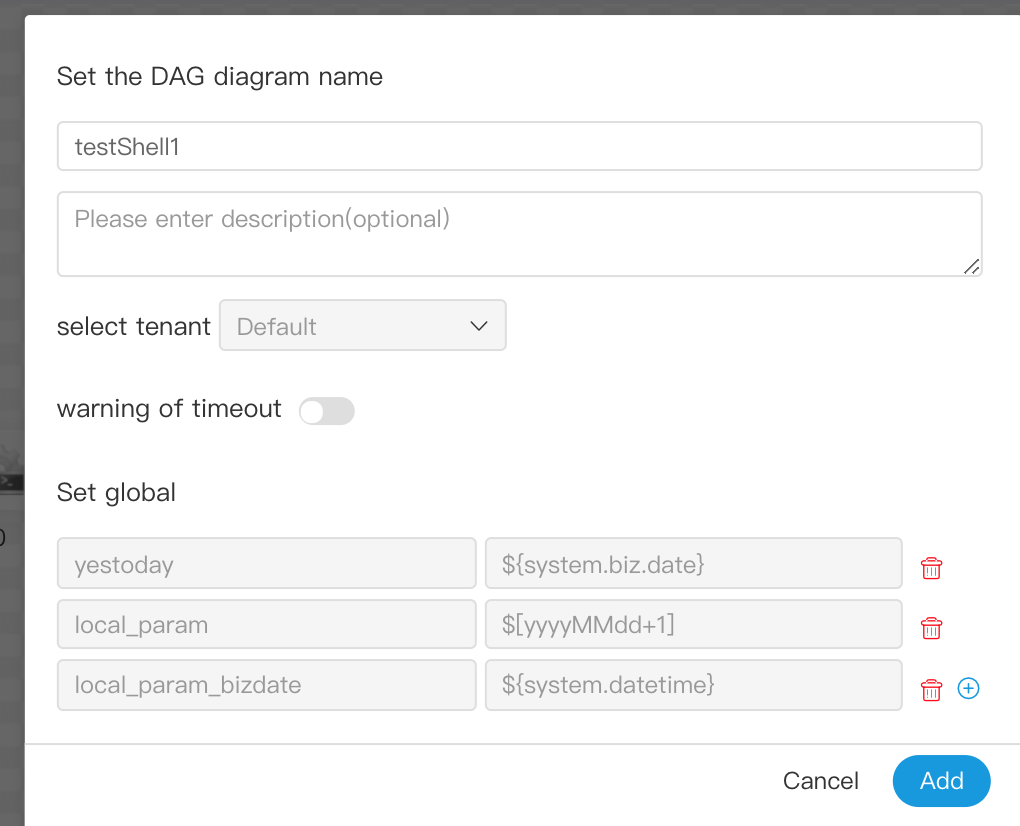
> global_bizdate is a global parameter, referring to system parameters.
diff --git a/docs/en_US/Upgrade documentation.md b/docs/en_US/upgrade.md
similarity index 100%
rename from docs/en_US/Upgrade documentation.md
rename to docs/en_US/upgrade.md
diff --git a/docs/zh_CN/前端部署文档.md b/docs/zh_CN/前端部署文档.md
index 460134b858..dc9cf61216 100644
--- a/docs/zh_CN/前端部署文档.md
+++ b/docs/zh_CN/前端部署文档.md
@@ -5,7 +5,7 @@
## 1、准备工作
#### 下载安装包
-请下载最新版本的安装包,下载地址: [码云下载](https://gitee.com/easyscheduler/EasyScheduler/attach_files/)
+请下载最新版本的安装包,下载地址: [码云下载](https://gitee.com/easyscheduler/EasyScheduler/attach_files/) 或者 [github下载](https://github.com/analysys/EasyScheduler/releases)
下载 escheduler-ui-x.x.x.tar.gz 后,解压`tar -zxvf escheduler-ui-x.x.x.tar.gz ./`后,进入`escheduler-ui`目录
diff --git a/docs/zh_CN/后端部署文档.md b/docs/zh_CN/后端部署文档.md
index 5588f1026e..8ab315a355 100644
--- a/docs/zh_CN/后端部署文档.md
+++ b/docs/zh_CN/后端部署文档.md
@@ -4,7 +4,7 @@
## 1、准备工作
-请下载最新版本的安装包,下载地址: [码云下载](https://gitee.com/easyscheduler/EasyScheduler/attach_files/) ,下载escheduler-backend-x.x.x.tar.gz(后端简称escheduler-backend),escheduler-ui-x.x.x.tar.gz(前端简称escheduler-ui)
+请下载最新版本的安装包,下载地址: [码云下载](https://gitee.com/easyscheduler/EasyScheduler/attach_files/)或者[github下载](https://github.com/analysys/EasyScheduler/releases) ,下载escheduler-backend-x.x.x.tar.gz(后端简称escheduler-backend),escheduler-ui-x.x.x.tar.gz(前端简称escheduler-ui)
#### 准备一: 基础软件安装(必装项请自行安装)
diff --git a/docs/zh_CN/快速上手.md b/docs/zh_CN/快速上手.md
index 9834fba4d4..966ef88e84 100644
--- a/docs/zh_CN/快速上手.md
+++ b/docs/zh_CN/快速上手.md
@@ -37,13 +37,13 @@
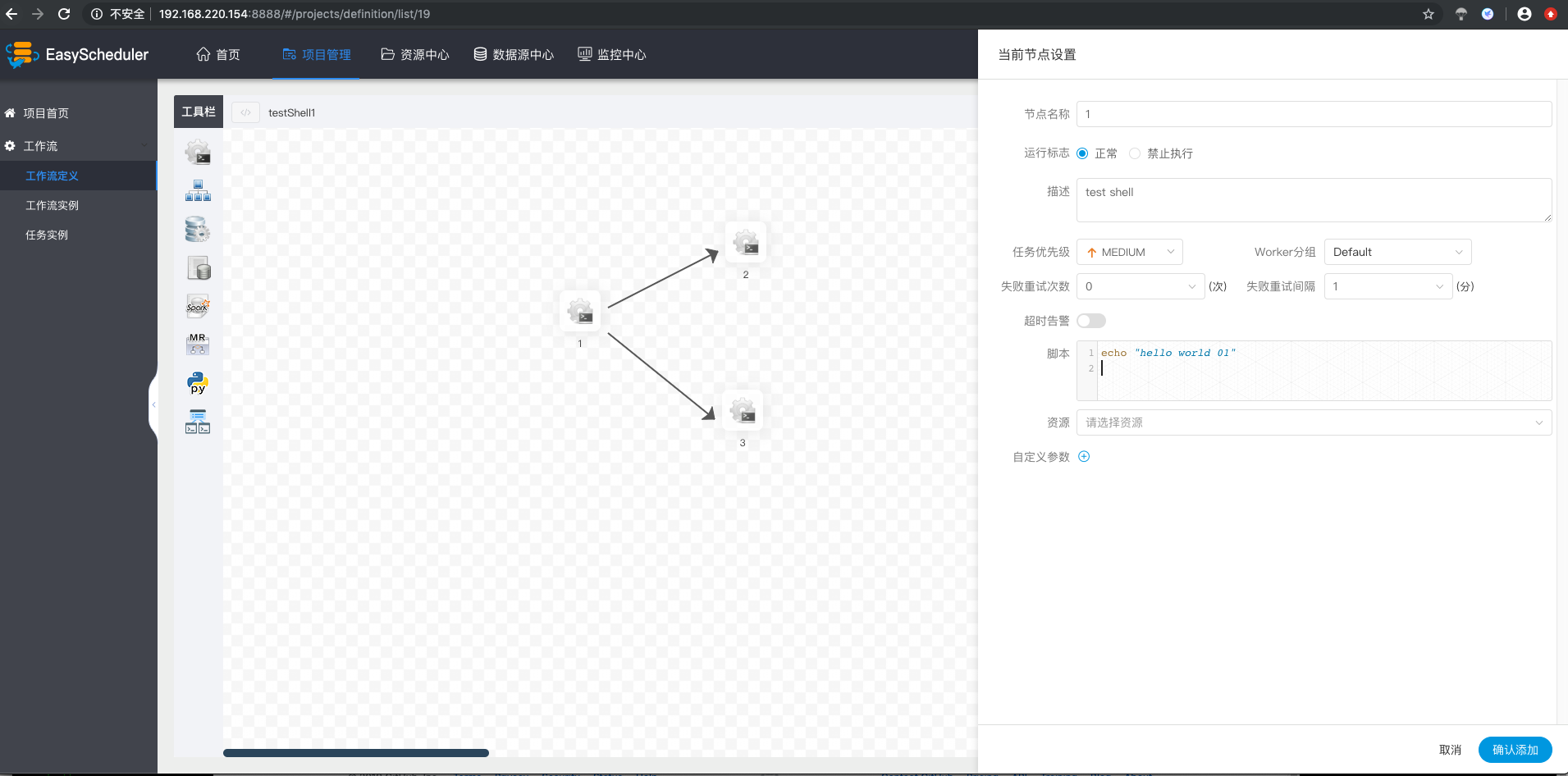
 - * 点击工作流定义->创建工作流定义->上线流程定义
+ * 点击工作流定义->创建工作流定义->上线工作流定义
- * 点击工作流定义->创建工作流定义->上线流程定义
+ * 点击工作流定义->创建工作流定义->上线工作流定义
- * 运行流程定义->点击工作流实例->点击流程实例名称->双击任务节点->查看任务执行日志
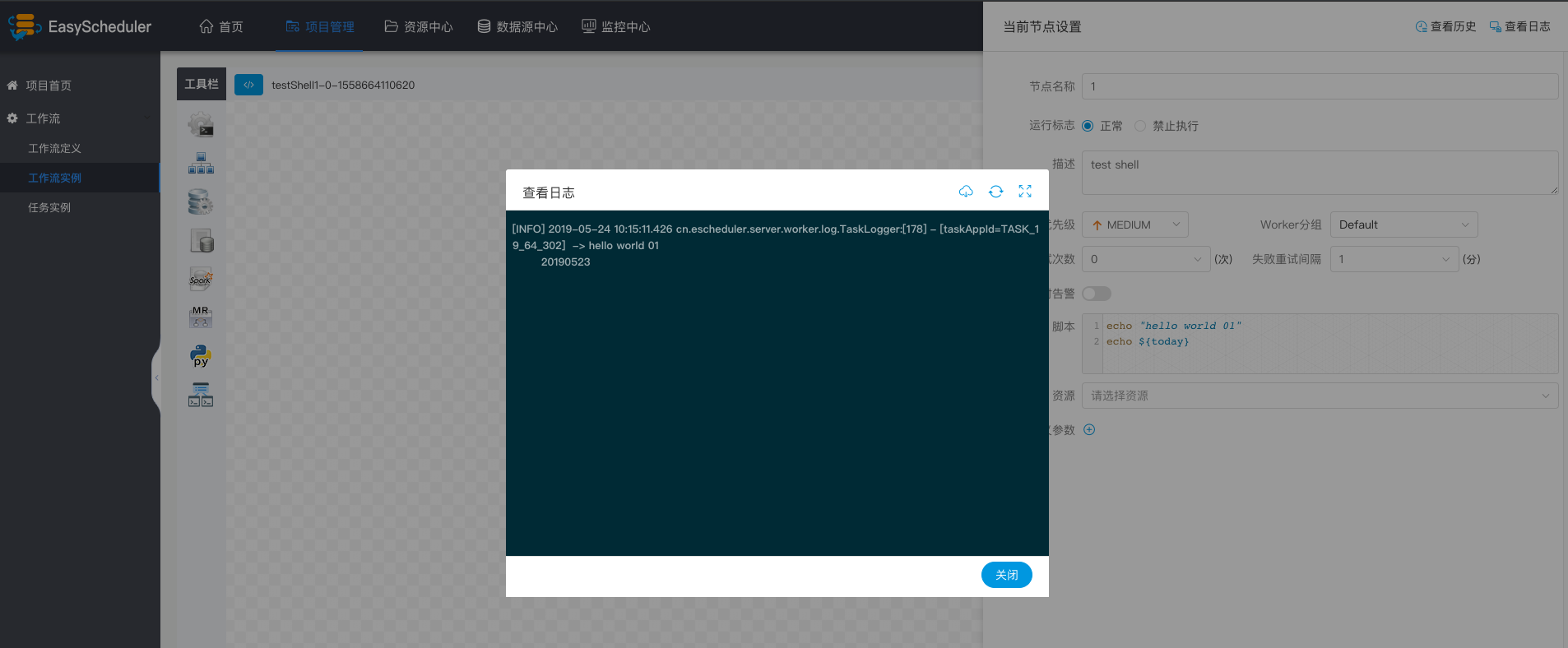
+ * 运行工作流定义->点击工作流实例->点击工作流实例名称->双击任务节点->查看任务执行日志
 diff --git a/docs/zh_CN/系统使用手册.md b/docs/zh_CN/系统使用手册.md
index 0f847012bd..2e5ee635b3 100644
--- a/docs/zh_CN/系统使用手册.md
+++ b/docs/zh_CN/系统使用手册.md
@@ -15,16 +15,16 @@
diff --git a/docs/zh_CN/系统使用手册.md b/docs/zh_CN/系统使用手册.md
index 0f847012bd..2e5ee635b3 100644
--- a/docs/zh_CN/系统使用手册.md
+++ b/docs/zh_CN/系统使用手册.md
@@ -15,16 +15,16 @@
-> 项目首页其中包含任务状态统计,流程状态统计、流程定义统计
+> 项目首页其中包含任务状态统计,流程状态统计、工作流定义统计
- 任务状态统计:是指在指定时间范围内,统计任务实例中的待运行、失败、运行中、完成、成功的个数
- - 流程状态统计:是指在指定时间范围内,统计流程实例中的待运行、失败、运行中、完成、成功的个数
- - 流程定义统计:是统计该用户创建的流程定义及管理员授予该用户的流程定义
+ - 流程状态统计:是指在指定时间范围内,统计工作流实例中的待运行、失败、运行中、完成、成功的个数
+ - 工作流定义统计:是统计该用户创建的工作流定义及管理员授予该用户的工作流定义
### 创建工作流定义
- - 进入项目首页,点击“工作流定义”,进入流程定义列表页。
- - 点击“创建工作流”,创建新的流程定义。
+ - 进入项目首页,点击“工作流定义”,进入工作流定义列表页。
+ - 点击“创建工作流”,创建新的工作流定义。
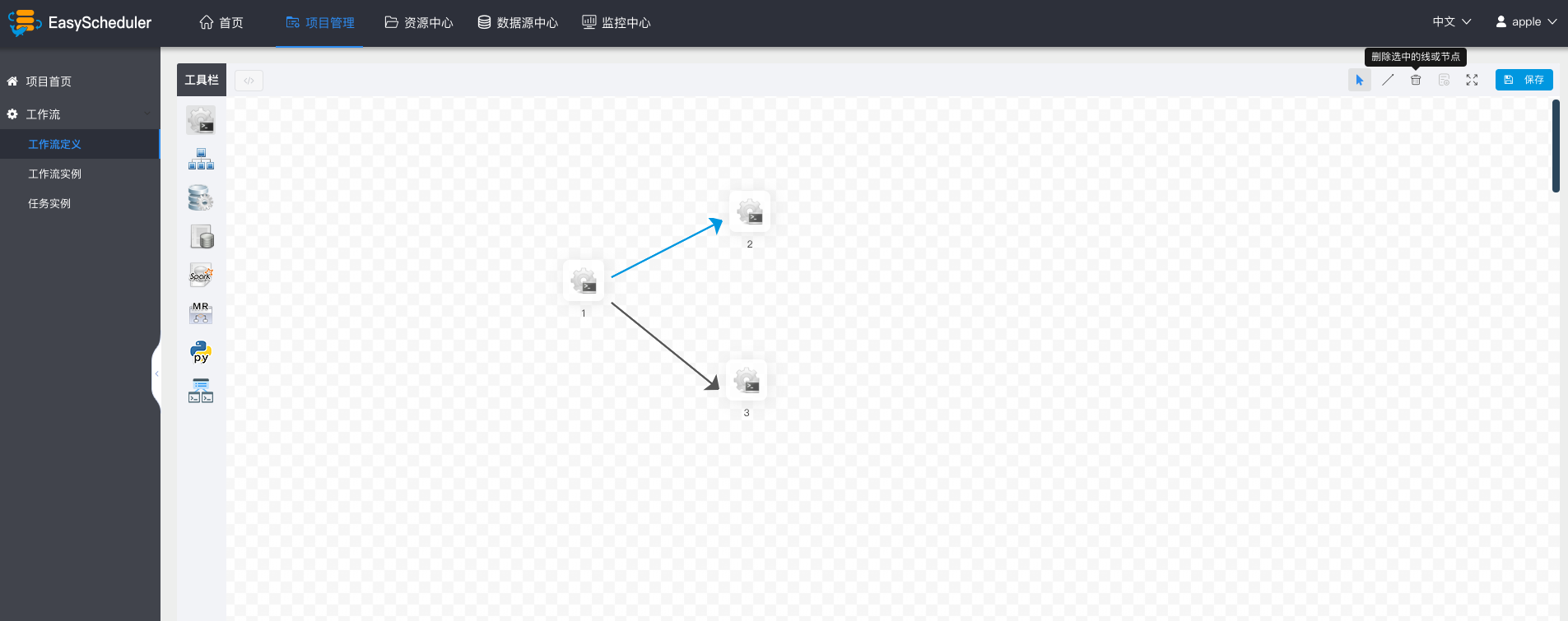
- 拖拽“SHELL"节点到画布,新增一个Shell任务。
- 填写”节点名称“,”描述“,”脚本“字段。
- 选择“任务优先级”,级别高的任务在执行队列中会优先执行,相同优先级的任务按照先进先出的顺序执行。
@@ -45,7 +45,7 @@
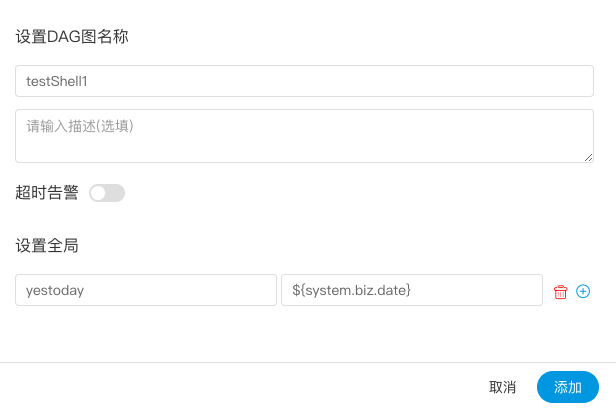
 - - 点击”保存“,输入流程定义名称,流程定义描述,设置全局参数,参考[自定义参数](#用户自定义参数)。
+ - 点击”保存“,输入工作流定义名称,工作流定义描述,设置全局参数,参考[自定义参数](#用户自定义参数)。
- - 点击”保存“,输入流程定义名称,流程定义描述,设置全局参数,参考[自定义参数](#用户自定义参数)。
+ - 点击”保存“,输入工作流定义名称,工作流定义描述,设置全局参数,参考[自定义参数](#用户自定义参数)。
 @@ -53,9 +53,9 @@
- 其他类型节点,请参考 [任务节点类型和参数设置](#任务节点类型和参数设置)
-### 执行流程定义
- - **未上线状态的流程定义可以编辑,但是不可以运行**,所以先上线工作流
- > 点击工作流定义,返回流程定义列表,点击”上线“图标,上线工作流定义。
+### 执行工作流定义
+ - **未上线状态的工作流定义可以编辑,但是不可以运行**,所以先上线工作流
+ > 点击工作流定义,返回工作流定义列表,点击”上线“图标,上线工作流定义。
> 下线工作流定义的时候,要先将定时管理中的定时任务下线,这样才能成功下线工作流定义
@@ -92,8 +92,8 @@
- 定时上线,**新创建的定时是下线状态,需要点击“定时管理->上线”,定时才能正常工作**。
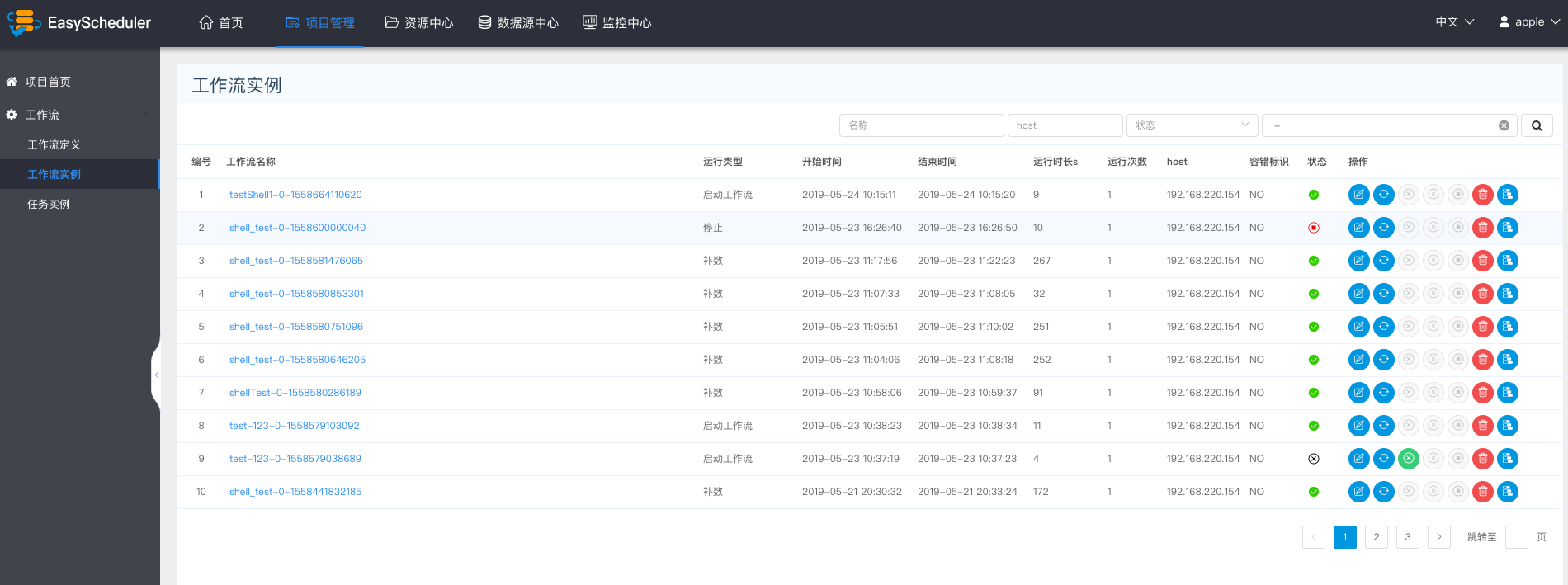
-### 查看流程实例
- > 点击“工作流实例”,查看流程实例列表。
+### 查看工作流实例
+ > 点击“工作流实例”,查看工作流实例列表。
> 点击工作流名称,查看任务执行状态。
@@ -107,7 +107,7 @@
@@ -53,9 +53,9 @@
- 其他类型节点,请参考 [任务节点类型和参数设置](#任务节点类型和参数设置)
-### 执行流程定义
- - **未上线状态的流程定义可以编辑,但是不可以运行**,所以先上线工作流
- > 点击工作流定义,返回流程定义列表,点击”上线“图标,上线工作流定义。
+### 执行工作流定义
+ - **未上线状态的工作流定义可以编辑,但是不可以运行**,所以先上线工作流
+ > 点击工作流定义,返回工作流定义列表,点击”上线“图标,上线工作流定义。
> 下线工作流定义的时候,要先将定时管理中的定时任务下线,这样才能成功下线工作流定义
@@ -92,8 +92,8 @@
- 定时上线,**新创建的定时是下线状态,需要点击“定时管理->上线”,定时才能正常工作**。
-### 查看流程实例
- > 点击“工作流实例”,查看流程实例列表。
+### 查看工作流实例
+ > 点击“工作流实例”,查看工作流实例列表。
> 点击工作流名称,查看任务执行状态。
@@ -107,7 +107,7 @@
- > 点击任务实例节点,点击**查看历史**,可以查看该流程实例运行的该任务实例列表
+ > 点击任务实例节点,点击**查看历史**,可以查看该工作流实例运行的该任务实例列表
 @@ -120,14 +120,14 @@
@@ -120,14 +120,14 @@
- * 编辑:可以对已经终止的流程进行编辑,编辑后保存的时候,可以选择是否更新到流程定义。
+ * 编辑:可以对已经终止的流程进行编辑,编辑后保存的时候,可以选择是否更新到工作流定义。
* 重跑:可以对已经终止的流程进行重新执行。
* 恢复失败:针对失败的流程,可以执行恢复失败操作,从失败的节点开始执行。
* 停止:对正在运行的流程进行**停止**操作,后台会先对worker进程`kill`,再执行`kill -9`操作
* 暂停:可以对正在运行的流程进行**暂停**操作,系统状态变为**等待执行**,会等待正在执行的任务结束,暂停下一个要执行的任务。
* 恢复暂停:可以对暂停的流程恢复,直接从**暂停的节点**开始运行
- * 删除:删除流程实例及流程实例下的任务实例
- * 甘特图:Gantt图纵轴是某个流程实例下的任务实例的拓扑排序,横轴是任务实例的运行时间,如图示:
+ * 删除:删除工作流实例及工作流实例下的任务实例
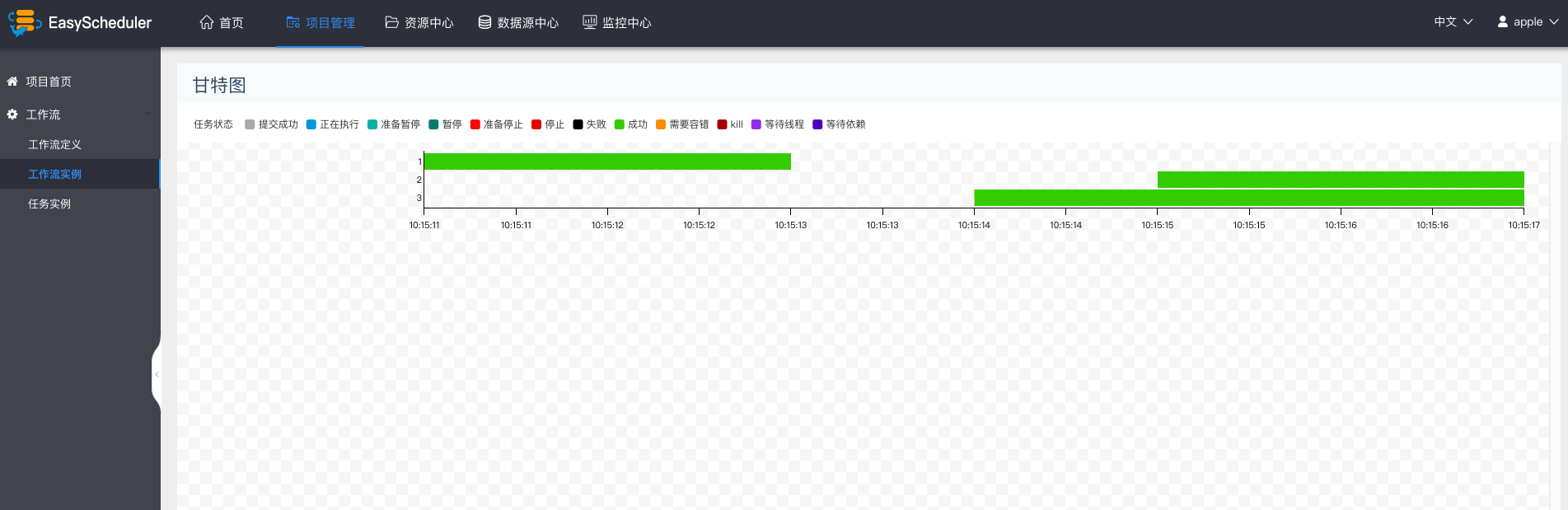
+ * 甘特图:Gantt图纵轴是某个工作流实例下的任务实例的拓扑排序,横轴是任务实例的运行时间,如图示:
@@ -343,8 +343,8 @@ conf/common/hadoop.properties
### 创建普通用户
- 用户分为**管理员用户**和**普通用户**
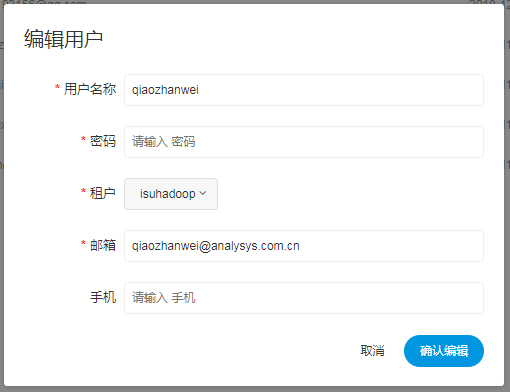
- * 管理员有**授权和用户管理**等权限,没有**创建项目和流程定义**的操作的权限
- * 普通用户可以**创建项目和对流程定义的创建,编辑,执行**等操作。
+ * 管理员有**授权和用户管理**等权限,没有**创建项目和工作流定义**的操作的权限
+ * 普通用户可以**创建项目和对工作流定义的创建,编辑,执行**等操作。
* 注意:**如果该用户切换了租户,则该用户所在租户下所有资源将复制到切换的新租户下**
 @@ -465,7 +465,7 @@ conf/common/hadoop.properties
@@ -465,7 +465,7 @@ conf/common/hadoop.properties
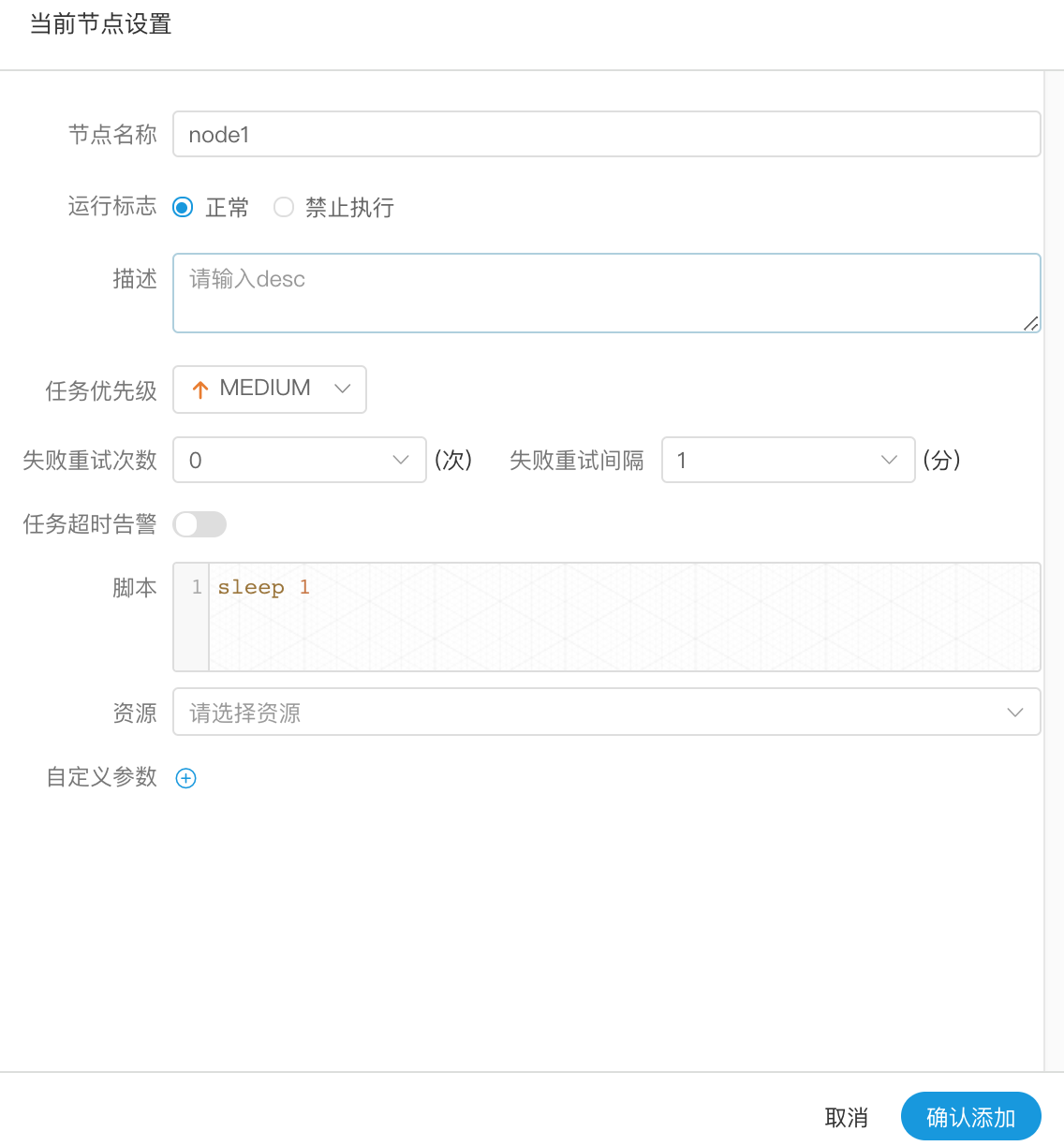
-- 节点名称:一个流程定义中的节点名称是唯一的
+- 节点名称:一个工作流定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度,如果不需要执行,可以打开禁止执行开关。
- 描述信息:描述该节点的功能
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填
@@ -482,10 +482,10 @@ conf/common/hadoop.properties
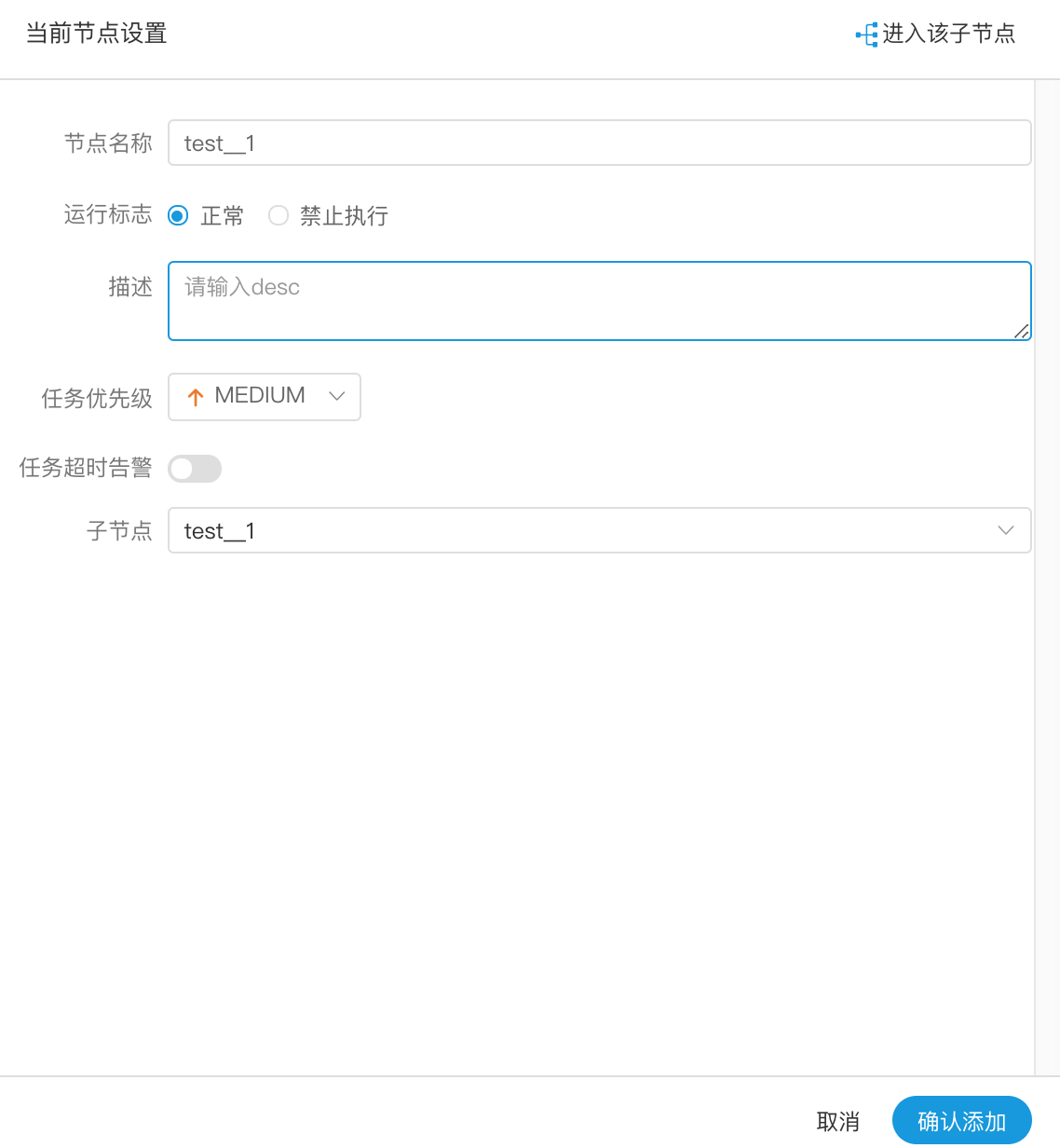 -- 节点名称:一个流程定义中的节点名称是唯一的
+- 节点名称:一个工作流定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
-- 子节点:是选择子流程的流程定义,右上角进入该子节点可以跳转到所选子流程的流程定义
+- 子节点:是选择子流程的工作流定义,右上角进入该子节点可以跳转到所选子流程的工作流定义
### 依赖(DEPENDENT)节点
- 依赖节点,就是**依赖检查节点**。比如A流程依赖昨天的B流程执行成功,依赖节点会去检查B流程在昨天是否有执行成功的实例。
@@ -658,7 +658,7 @@ conf/common/hadoop.properties
### 用户自定义参数
-> 用户自定义参数分为全局参数和局部参数。全局参数是保存流程定义和流程实例的时候传递的全局参数,全局参数可以在整个流程中的任何一个任务节点的局部参数引用。
+> 用户自定义参数分为全局参数和局部参数。全局参数是保存工作流定义和工作流实例的时候传递的全局参数,全局参数可以在整个流程中的任何一个任务节点的局部参数引用。
> 例如:
-- 节点名称:一个流程定义中的节点名称是唯一的
+- 节点名称:一个工作流定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
-- 子节点:是选择子流程的流程定义,右上角进入该子节点可以跳转到所选子流程的流程定义
+- 子节点:是选择子流程的工作流定义,右上角进入该子节点可以跳转到所选子流程的工作流定义
### 依赖(DEPENDENT)节点
- 依赖节点,就是**依赖检查节点**。比如A流程依赖昨天的B流程执行成功,依赖节点会去检查B流程在昨天是否有执行成功的实例。
@@ -658,7 +658,7 @@ conf/common/hadoop.properties
### 用户自定义参数
-> 用户自定义参数分为全局参数和局部参数。全局参数是保存流程定义和流程实例的时候传递的全局参数,全局参数可以在整个流程中的任何一个任务节点的局部参数引用。
+> 用户自定义参数分为全局参数和局部参数。全局参数是保存工作流定义和工作流实例的时候传递的全局参数,全局参数可以在整个流程中的任何一个任务节点的局部参数引用。
> 例如: