+
@@ -37,8 +37,10 @@
@@ -84,11 +86,18 @@
$('body').find('.tooltip.fade.top.in').remove()
},
_onDeleteAll (i) {
- this._deleteDep(i)
+ this.dependTaskList.map((item,i)=>{
+ if(item.dependItemList.length === 0){
+ this.dependTaskList.splice(i,1)
+ }
+ })
},
_setGlobalRelation () {
this.relation = this.relation === 'AND' ? 'OR' : 'AND'
},
+ getDependTaskList(i){
+ // console.log('getDependTaskList',i)
+ },
_setRelation (i) {
this.dependTaskList[i].relation = this.dependTaskList[i].relation === 'AND' ? 'OR' : 'AND'
},
diff --git a/escheduler-ui/src/js/conf/home/pages/dag/_source/formModel/tasks/flink.vue b/escheduler-ui/src/js/conf/home/pages/dag/_source/formModel/tasks/flink.vue
new file mode 100644
index 0000000000..1c3b18a64c
--- /dev/null
+++ b/escheduler-ui/src/js/conf/home/pages/dag/_source/formModel/tasks/flink.vue
@@ -0,0 +1,388 @@
+
+
+
+ {{$t('Program Type')}}
+
+
+
+
+
+
+
+
+
+ {{$t('Main class')}}
+
+
+
+
+
+
+ {{$t('Main jar package')}}
+
+
+
+
+
+
+
+
+ {{$t('Deploy Mode')}}
+
+
+
+
+
+
+
+
+ {{$t('slot')}}
+
+
+
+
+ {{$t('taskManager')}}
+
+
+
+
+
+
+ {{$t('jobManagerMemory')}}
+
+
+
+
+ {{$t('taskManagerMemory')}}
+
+
+
+
+
+
+
+
+ {{$t('Command-line parameters')}}
+
+
+
+
+
+
+ {{$t('Other parameters')}}
+
+
+
+
+
+
+ {{$t('Resources')}}
+
+
+
+
+
+
+ {{$t('Custom Parameters')}}
+
+
+
+
+
+
+
+
+
diff --git a/escheduler-ui/src/js/conf/home/pages/dag/_source/plugIn/jsPlumbHandle.js b/escheduler-ui/src/js/conf/home/pages/dag/_source/plugIn/jsPlumbHandle.js
index 440deb48fb..807c70bfd5 100644
--- a/escheduler-ui/src/js/conf/home/pages/dag/_source/plugIn/jsPlumbHandle.js
+++ b/escheduler-ui/src/js/conf/home/pages/dag/_source/plugIn/jsPlumbHandle.js
@@ -645,7 +645,6 @@ JSP.prototype.saveStore = function () {
})
})
- console.log(tasksAll())
_.map(tasksAll(), v => {
locations[v.id] = {
@@ -656,7 +655,6 @@ JSP.prototype.saveStore = function () {
}
})
- console.log(locations)
// Storage node
store.commit('dag/setTasks', tasks)
diff --git a/escheduler-ui/src/js/conf/home/pages/dag/definitionDetails.vue b/escheduler-ui/src/js/conf/home/pages/dag/definitionDetails.vue
index c8849d594e..7812aff2b1 100644
--- a/escheduler-ui/src/js/conf/home/pages/dag/definitionDetails.vue
+++ b/escheduler-ui/src/js/conf/home/pages/dag/definitionDetails.vue
@@ -25,7 +25,7 @@
props: {},
methods: {
...mapMutations('dag', ['resetParams', 'setIsDetails']),
- ...mapActions('dag', ['getProcessList', 'getResourcesList', 'getProcessDetails']),
+ ...mapActions('dag', ['getProcessList','getProjectList', 'getResourcesList', 'getProcessDetails']),
...mapActions('security', ['getTenantList','getWorkerGroupsAll']),
/**
* init
@@ -40,6 +40,8 @@
this.getProcessDetails(this.$route.params.id),
// get process definition
this.getProcessList(),
+ // get project
+ this.getProjectList(),
// get resource
this.getResourcesList(),
// get worker group list
diff --git a/escheduler-ui/src/js/conf/home/pages/dag/img/toobar_flink.svg b/escheduler-ui/src/js/conf/home/pages/dag/img/toobar_flink.svg
new file mode 100644
index 0000000000..33ba8b7b3d
--- /dev/null
+++ b/escheduler-ui/src/js/conf/home/pages/dag/img/toobar_flink.svg
@@ -0,0 +1,211 @@
+
+
diff --git a/escheduler-ui/src/js/conf/home/pages/dag/index.vue b/escheduler-ui/src/js/conf/home/pages/dag/index.vue
index 7a3429f3b1..3af74e12d3 100644
--- a/escheduler-ui/src/js/conf/home/pages/dag/index.vue
+++ b/escheduler-ui/src/js/conf/home/pages/dag/index.vue
@@ -24,7 +24,7 @@
props: {},
methods: {
...mapMutations('dag', ['resetParams']),
- ...mapActions('dag', ['getProcessList', 'getResourcesList']),
+ ...mapActions('dag', ['getProcessList','getProjectList', 'getResourcesList']),
...mapActions('security', ['getTenantList','getWorkerGroupsAll']),
/**
* init
@@ -37,6 +37,8 @@
Promise.all([
// get process definition
this.getProcessList(),
+ // get project
+ this.getProjectList(),
// get resource
this.getResourcesList(),
// get worker group list
diff --git a/escheduler-ui/src/js/conf/home/pages/dag/instanceDetails.vue b/escheduler-ui/src/js/conf/home/pages/dag/instanceDetails.vue
index 705a151b78..65b76b6532 100644
--- a/escheduler-ui/src/js/conf/home/pages/dag/instanceDetails.vue
+++ b/escheduler-ui/src/js/conf/home/pages/dag/instanceDetails.vue
@@ -27,7 +27,7 @@
props: {},
methods: {
...mapMutations('dag', ['setIsDetails', 'resetParams']),
- ...mapActions('dag', ['getProcessList', 'getResourcesList', 'getInstancedetail']),
+ ...mapActions('dag', ['getProcessList','getProjectList', 'getResourcesList', 'getInstancedetail']),
...mapActions('security', ['getTenantList','getWorkerGroupsAll']),
/**
* init
@@ -42,6 +42,8 @@
this.getInstancedetail(this.$route.params.id),
// get process definition
this.getProcessList(),
+ // get project
+ this.getProjectList(),
// get resources
this.getResourcesList(),
// get worker group list
diff --git a/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/email.vue b/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/email.vue
index f5c38f9a12..ec34c78648 100644
--- a/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/email.vue
+++ b/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/email.vue
@@ -271,13 +271,11 @@
$(this).prop('comStart', true)
// Check mailbox index initialization
this.activeIndex = null
- // console.log('中文输入:开始');
this.isCn = true
}).on('compositionend', () => {
$(this).prop('comStart', false)
// Check mailbox index initialization
this.activeIndex = null
- // console.log('中文输入:结束');
this.isCn = false
})
}
diff --git a/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/timing.vue b/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/timing.vue
index bdd9fa40ba..1dd6630c41 100644
--- a/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/timing.vue
+++ b/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/timing.vue
@@ -48,7 +48,7 @@
{{$t('Next five execution times')}}
@@ -289,6 +289,9 @@
watch: {
},
created () {
+ if(this.item.crontab !== null){
+ this.crontab = this.item.crontab
+ }
this.receivers = _.cloneDeep(this.receiversD)
this.receiversCc = _.cloneDeep(this.receiversCcD)
},
diff --git a/escheduler-ui/src/js/conf/home/pages/projects/pages/instance/pages/list/_source/list.vue b/escheduler-ui/src/js/conf/home/pages/projects/pages/instance/pages/list/_source/list.vue
index 619407a61a..9efc9f721a 100644
--- a/escheduler-ui/src/js/conf/home/pages/projects/pages/instance/pages/list/_source/list.vue
+++ b/escheduler-ui/src/js/conf/home/pages/projects/pages/instance/pages/list/_source/list.vue
@@ -123,6 +123,7 @@
shape="circle"
size="xsmall"
data-toggle="tooltip"
+ :disabled="item.state === 'RUNNING_EXEUTION'"
:title="$t('delete')">
diff --git a/escheduler-ui/src/js/conf/home/pages/security/pages/users/_source/createUser.vue b/escheduler-ui/src/js/conf/home/pages/security/pages/users/_source/createUser.vue
index 378f410d38..b45e6555ab 100644
--- a/escheduler-ui/src/js/conf/home/pages/security/pages/users/_source/createUser.vue
+++ b/escheduler-ui/src/js/conf/home/pages/security/pages/users/_source/createUser.vue
@@ -203,7 +203,6 @@
},
_submit () {
this.$refs['popup'].spinnerLoading = true
- console.log(this.tenantId.id)
let param = {
userName: this.userName,
userPassword: this.userPassword,
diff --git a/escheduler-ui/src/js/conf/home/store/dag/actions.js b/escheduler-ui/src/js/conf/home/store/dag/actions.js
index 7482dbed9b..9d73918f6d 100644
--- a/escheduler-ui/src/js/conf/home/store/dag/actions.js
+++ b/escheduler-ui/src/js/conf/home/store/dag/actions.js
@@ -261,6 +261,35 @@ export default {
})
})
},
+ /**
+ * Get a list of project
+ */
+ getProjectList ({ state }, payload) {
+ return new Promise((resolve, reject) => {
+ if (state.projectListS.length) {
+ resolve()
+ return
+ }
+ io.get(`projects/queryAllProjectList`, payload, res => {
+ state.projectListS = res.data
+ resolve(res.data)
+ }).catch(res => {
+ reject(res)
+ })
+ })
+ },
+ /**
+ * Get a list of process definitions by project id
+ */
+ getProcessByProjectId ({ state }, payload) {
+ return new Promise((resolve, reject) => {
+ io.get(`projects/${state.projectName}/process/queryProccessDefinitionAllByProjectId`, payload, res => {
+ resolve(res.data)
+ }).catch(res => {
+ reject(res)
+ })
+ })
+ },
/**
* get datasource
*/
diff --git a/escheduler-ui/src/js/conf/home/store/dag/mutations.js b/escheduler-ui/src/js/conf/home/store/dag/mutations.js
index d3386bc76a..4a94fe093e 100644
--- a/escheduler-ui/src/js/conf/home/store/dag/mutations.js
+++ b/escheduler-ui/src/js/conf/home/store/dag/mutations.js
@@ -109,6 +109,7 @@ export default {
state.tenantId = payload && payload.tenantId || -1
state.processListS = payload && payload.processListS || []
state.resourcesListS = payload && payload.resourcesListS || []
+ state.projectListS = payload && payload.projectListS || []
state.isDetails = payload && payload.isDetails || false
state.runFlag = payload && payload.runFlag || ''
state.locations = payload && payload.locations || {}
diff --git a/escheduler-ui/src/js/conf/home/store/dag/state.js b/escheduler-ui/src/js/conf/home/store/dag/state.js
index c875500f5f..26891a6774 100644
--- a/escheduler-ui/src/js/conf/home/store/dag/state.js
+++ b/escheduler-ui/src/js/conf/home/store/dag/state.js
@@ -47,6 +47,8 @@ export default {
syncDefine: true,
// tasks processList
processListS: [],
+ // projectList
+ projectListS: [],
// tasks resourcesList
resourcesListS: [],
// tasks datasource Type
diff --git a/escheduler-ui/src/js/module/i18n/locale/zh_CN.js b/escheduler-ui/src/js/module/i18n/locale/zh_CN.js
index 7ac3dda87e..cfa0224185 100644
--- a/escheduler-ui/src/js/module/i18n/locale/zh_CN.js
+++ b/escheduler-ui/src/js/module/i18n/locale/zh_CN.js
@@ -476,5 +476,9 @@ export default {
'warning of timeout': '超时告警',
'Next five execution times': '接下来五次执行时间',
'Execute time': '执行时间',
- 'Complement range': '补数范围'
+ 'Complement range': '补数范围',
+ 'slot':'slot数量',
+ 'taskManager':'taskManage数量',
+ 'jobManagerMemory':'jobManager内存数',
+ 'taskManagerMemory':'taskManager内存数'
}
diff --git a/escheduler-ui/src/lib/@analysys/ans-ui/package.json b/escheduler-ui/src/lib/@analysys/ans-ui/package.json
index cddb561eb3..061f54a7ad 100644
--- a/escheduler-ui/src/lib/@analysys/ans-ui/package.json
+++ b/escheduler-ui/src/lib/@analysys/ans-ui/package.json
@@ -53,7 +53,6 @@
"babel-plugin-transform-runtime": "^6.23.0",
"babel-plugin-transform-vue-jsx": "^3.7.0",
"babel-preset-env": "^1.5.2",
- "babel-runtime": "^6.26.0",
"cross-env": "^5.2.0",
"css-loader": "0.28.8",
"cssnano": "^4.0.3",
diff --git a/escheduler-ui/src/lib/@fedor/io/package.json b/escheduler-ui/src/lib/@fedor/io/package.json
index 0066dfa8f0..20563bedeb 100644
--- a/escheduler-ui/src/lib/@fedor/io/package.json
+++ b/escheduler-ui/src/lib/@fedor/io/package.json
@@ -23,7 +23,6 @@
"babel-plugin-transform-class-properties": "^6.24.1",
"babel-plugin-transform-runtime": "^6.23.0",
"babel-preset-env": "^1.5.2",
- "babel-runtime": "^6.26.0",
"body-parser": "^1.17.2",
"chai": "^4.1.1",
"cors": "^2.8.4",
diff --git a/escheduler-ui/src/lib/@vue/crontab/example/app.vue b/escheduler-ui/src/lib/@vue/crontab/example/app.vue
index c691638a64..7328886801 100644
--- a/escheduler-ui/src/lib/@vue/crontab/example/app.vue
+++ b/escheduler-ui/src/lib/@vue/crontab/example/app.vue
@@ -36,7 +36,6 @@
_lang (type) {
this.is = false
this.lang = type
- console.log(this.lang)
setTimeout(() => {
this.is = true
}, 1)
diff --git a/escheduler-ui/src/view/docs/zh_CN/_book/images/flink_edit.png b/escheduler-ui/src/view/docs/zh_CN/_book/images/flink_edit.png
new file mode 100644
index 0000000000..b7c2321157
Binary files /dev/null and b/escheduler-ui/src/view/docs/zh_CN/_book/images/flink_edit.png differ
diff --git a/install.sh b/install.sh
index 894a4c2f18..dc09ce3c97 100644
--- a/install.sh
+++ b/install.sh
@@ -34,252 +34,257 @@ fi
source ${workDir}/conf/config/run_config.conf
source ${workDir}/conf/config/install_config.conf
-# mysql配置
-# mysql 地址,端口
+# mysql config
+# mysql address and port
mysqlHost="192.168.xx.xx:3306"
-# mysql 数据库名称
+# mysql database
mysqlDb="escheduler"
-# mysql 用户名
+# mysql username
mysqlUserName="xx"
-# mysql 密码
-# 注意:如果有特殊字符,请用 \ 转移符进行转移
+# mysql passwprd
+# Note: if there are special characters, please use the \ transfer character to transfer
mysqlPassword="xx"
-# conf/config/install_config.conf配置
-# 注意:安装路径,不要当前路径(pwd)一样
+# conf/config/install_config.conf config
+# Note: the installation path is not the same as the current path (pwd)
installPath="/data1_1T/escheduler"
-# 部署用户
-# 注意:部署用户需要有sudo权限及操作hdfs的权限,如果开启hdfs,根目录需要自行创建
+# deployment user
+# Note: the deployment user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled, the root directory needs to be created by itself
deployUser="escheduler"
-# zk集群
+# zk cluster
zkQuorum="192.168.xx.xx:2181,192.168.xx.xx:2181,192.168.xx.xx:2181"
-# 安装hosts
-# 注意:安装调度的机器hostname列表,如果是伪分布式,则只需写一个伪分布式hostname即可
+# install hosts
+# Note: install the scheduled hostname list. If it is pseudo-distributed, just write a pseudo-distributed hostname
ips="ark0,ark1,ark2,ark3,ark4"
-# conf/config/run_config.conf配置
-# 运行Master的机器
-# 注意:部署master的机器hostname列表
+# conf/config/run_config.conf config
+# run master machine
+# Note: list of hosts hostname for deploying master
masters="ark0,ark1"
-# 运行Worker的机器
-# 注意:部署worker的机器hostname列表
+# run worker machine
+# note: list of machine hostnames for deploying workers
workers="ark2,ark3,ark4"
-# 运行Alert的机器
-# 注意:部署alert server的机器hostname列表
+# run alert machine
+# note: list of machine hostnames for deploying alert server
alertServer="ark3"
-# 运行Api的机器
-# 注意:部署api server的机器hostname列表
+# run api machine
+# note: list of machine hostnames for deploying api server
apiServers="ark1"
-# alert配置
-# 邮件协议
+# alert config
+# mail protocol
mailProtocol="SMTP"
-# 邮件服务host
+# mail server host
mailServerHost="smtp.exmail.qq.com"
-# 邮件服务端口
+# mail server port
mailServerPort="25"
-# 发送人
+# sender
mailSender="xxxxxxxxxx"
-# 发送人密码
+# sender password
mailPassword="xxxxxxxxxx"
-# TLS邮件协议支持
+# TLS mail protocol support
starttlsEnable="false"
-# SSL邮件协议支持
-# 注意:默认开启的是SSL协议,TLS和SSL只能有一个处于true状态
+# SSL mail protocol support
+# note: The SSL protocol is enabled by default.
+# only one of TLS and SSL can be in the true state.
sslEnable="true"
-# 下载Excel路径
+# download excel path
xlsFilePath="/tmp/xls"
-# 企业微信企业ID配置
+# Enterprise WeChat Enterprise ID Configuration
enterpriseWechatCorpId="xxxxxxxxxx"
-# 企业微信应用Secret配置
+# Enterprise WeChat application Secret configuration
enterpriseWechatSecret="xxxxxxxxxx"
-# 企业微信应用AgentId配置
+# Enterprise WeChat Application AgentId Configuration
enterpriseWechatAgentId="xxxxxxxxxx"
-# 企业微信用户配置,多个用户以,分割
+# Enterprise WeChat user configuration, multiple users to , split
enterpriseWechatUsers="xxxxx,xxxxx"
-#是否启动监控自启动脚本
+# whether to start monitoring self-starting scripts
monitorServerState="false"
-# 资源中心上传选择存储方式:HDFS,S3,NONE
+# resource Center upload and select storage method:HDFS,S3,NONE
resUploadStartupType="NONE"
-# 如果resUploadStartupType为HDFS,defaultFS写namenode地址,支持HA,需要将core-site.xml和hdfs-site.xml放到conf目录下
-# 如果是S3,则写S3地址,比如说:s3a://escheduler,注意,一定要创建根目录/escheduler
+# if resUploadStartupType is HDFS,defaultFS write namenode address,HA you need to put core-site.xml and hdfs-site.xml in the conf directory.
+# if S3,write S3 address,HA,for example :s3a://escheduler,
+# Note,s3 be sure to create the root directory /escheduler
defaultFS="hdfs://mycluster:8020"
-# 如果配置了S3,则需要有以下配置
+# if S3 is configured, the following configuration is required.
s3Endpoint="http://192.168.xx.xx:9010"
s3AccessKey="xxxxxxxxxx"
s3SecretKey="xxxxxxxxxx"
-# resourcemanager HA配置,如果是单resourcemanager,这里为yarnHaIps=""
+# resourcemanager HA configuration, if it is a single resourcemanager, here is yarnHaIps=""
yarnHaIps="192.168.xx.xx,192.168.xx.xx"
-# 如果是单 resourcemanager,只需要配置一个主机名称,如果是resourcemanager HA,则默认配置就好
+# if it is a single resourcemanager, you only need to configure one host name. If it is resourcemanager HA, the default configuration is fine.
singleYarnIp="ark1"
-# hdfs根路径,根路径的owner必须是部署用户。1.1.0之前版本不会自动创建hdfs根目录,需要自行创建
+# hdfs root path, the owner of the root path must be the deployment user.
+# versions prior to 1.1.0 do not automatically create the hdfs root directory, you need to create it yourself.
hdfsPath="/escheduler"
-# 拥有在hdfs根路径/下创建目录权限的用户
-# 注意:如果开启了kerberos,则直接hdfsRootUser="",就可以
+# have users who create directory permissions under hdfs root path /
+# Note: if kerberos is enabled, hdfsRootUser="" can be used directly.
hdfsRootUser="hdfs"
-# common 配置
-# 程序路径
+# common config
+# Program root path
programPath="/tmp/escheduler"
-#下载路径
+# download path
downloadPath="/tmp/escheduler/download"
-# 任务执行路径
+# task execute path
execPath="/tmp/escheduler/exec"
-# SHELL环境变量路径
+# SHELL environmental variable path
shellEnvPath="$installPath/conf/env/.escheduler_env.sh"
-# 资源文件的后缀
+# suffix of the resource file
resSuffixs="txt,log,sh,conf,cfg,py,java,sql,hql,xml"
-# 开发状态,如果是true,对于SHELL脚本可以在execPath目录下查看封装后的SHELL脚本,如果是false则执行完成直接删除
+# development status, if true, for the SHELL script, you can view the encapsulated SHELL script in the execPath directory.
+# If it is false, execute the direct delete
devState="true"
-# kerberos 配置
-# kerberos 是否启动
+# kerberos config
+# kerberos whether to start
kerberosStartUp="false"
-# kdc krb5 配置文件路径
+# kdc krb5 config file path
krb5ConfPath="$installPath/conf/krb5.conf"
-# keytab 用户名
+# keytab username
keytabUserName="hdfs-mycluster@ESZ.COM"
-# 用户 keytab路径
+# username keytab path
keytabPath="$installPath/conf/hdfs.headless.keytab"
-# zk 配置
-# zk根目录
+# zk config
+# zk root directory
zkRoot="/escheduler"
-# 用来记录挂掉机器的zk目录
+# used to record the zk directory of the hanging machine
zkDeadServers="/escheduler/dead-servers"
-# masters目录
-zkMasters="/escheduler/masters"
+# masters directory
+zkMasters="$zkRoot/masters"
-# workers目录
-zkWorkers="/escheduler/workers"
+# workers directory
+zkWorkers="$zkRoot/workers"
-# zk master分布式锁
-mastersLock="/escheduler/lock/masters"
+# zk master distributed lock
+mastersLock="$zkRoot/lock/masters"
-# zk worker分布式锁
-workersLock="/escheduler/lock/workers"
+# zk worker distributed lock
+workersLock="$zkRoot/lock/workers"
-# zk master容错分布式锁
-mastersFailover="/escheduler/lock/failover/masters"
+# zk master fault-tolerant distributed lock
+mastersFailover="$zkRoot/lock/failover/masters"
-# zk worker容错分布式锁
-workersFailover="/escheduler/lock/failover/workers"
+# zk worker fault-tolerant distributed lock
+workersFailover="$zkRoot/lock/failover/workers"
-# zk master启动容错分布式锁
-mastersStartupFailover="/escheduler/lock/failover/startup-masters"
+# zk master start fault tolerant distributed lock
+mastersStartupFailover="$zkRoot/lock/failover/startup-masters"
-# zk session 超时
+# zk session timeout
zkSessionTimeout="300"
-# zk 连接超时
+# zk connection timeout
zkConnectionTimeout="300"
-# zk 重试间隔
+# zk retry interval
zkRetrySleep="100"
-# zk重试最大次数
+# zk retry maximum number of times
zkRetryMaxtime="5"
-# master 配置
-# master执行线程最大数,流程实例的最大并行度
+# master config
+# master execution thread maximum number, maximum parallelism of process instance
masterExecThreads="100"
-# master任务执行线程最大数,每一个流程实例的最大并行度
+# the maximum number of master task execution threads, the maximum degree of parallelism for each process instance
masterExecTaskNum="20"
-# master心跳间隔
+# master heartbeat interval
masterHeartbeatInterval="10"
-# master任务提交重试次数
+# master task submission retries
masterTaskCommitRetryTimes="5"
-# master任务提交重试时间间隔
+# master task submission retry interval
masterTaskCommitInterval="100"
-# master最大cpu平均负载,用来判断master是否还有执行能力
+# master maximum cpu average load, used to determine whether the master has execution capability
masterMaxCpuLoadAvg="10"
-# master预留内存,用来判断master是否还有执行能力
+# master reserve memory to determine if the master has execution capability
masterReservedMemory="1"
-# worker 配置
-# worker执行线程
+# worker config
+# worker execution thread
workerExecThreads="100"
-# worker心跳间隔
+# worker heartbeat interval
workerHeartbeatInterval="10"
-# worker一次抓取任务数
+# worker number of fetch tasks
workerFetchTaskNum="3"
-# worker最大cpu平均负载,用来判断worker是否还有执行能力,保持系统默认,默认为cpu核数的2倍,当负载达到2倍时,
+# workerThe maximum cpu average load, used to determine whether the worker still has the ability to execute,
+# keep the system default, the default is twice the number of cpu cores, when the load reaches 2 times
#workerMaxCupLoadAvg="10"
-# worker预留内存,用来判断master是否还有执行能力
+# worker reserve memory to determine if the master has execution capability
workerReservedMemory="1"
-# api 配置
-# api 服务端口
+# api config
+# api server port
apiServerPort="12345"
-# api session 超时
+# api session timeout
apiServerSessionTimeout="7200"
-# api 上下文路径
+# api server context path
apiServerContextPath="/escheduler/"
-# spring 最大文件大小
+# spring max file size
springMaxFileSize="1024MB"
-# spring 最大请求文件大小
+# spring max request size
springMaxRequestSize="1024MB"
-# api 最大post请求大小
+# api max http post size
apiMaxHttpPostSize="5000000"
-# 1,替换文件
-echo "1,替换文件"
+# 1,replace file
+echo "1,replace file"
sed -i ${txt} "s#spring.datasource.url.*#spring.datasource.url=jdbc:mysql://${mysqlHost}/${mysqlDb}?characterEncoding=UTF-8#g" conf/dao/data_source.properties
sed -i ${txt} "s#spring.datasource.username.*#spring.datasource.username=${mysqlUserName}#g" conf/dao/data_source.properties
sed -i ${txt} "s#spring.datasource.password.*#spring.datasource.password=${mysqlPassword}#g" conf/dao/data_source.properties
@@ -375,8 +380,8 @@ sed -i ${txt} "s#alertServer.*#alertServer=${alertServer}#g" conf/config/run_con
sed -i ${txt} "s#apiServers.*#apiServers=${apiServers}#g" conf/config/run_config.conf
-# 2,创建目录
-echo "2,创建目录"
+# 2,create directory
+echo "2,create directory"
if [ ! -d $installPath ];then
sudo mkdir -p $installPath
@@ -387,22 +392,22 @@ hostsArr=(${ips//,/ })
for host in ${hostsArr[@]}
do
-# 如果programPath不存在,则创建
+# create if programPath does not exist
if ! ssh $host test -e $programPath; then
ssh $host "sudo mkdir -p $programPath;sudo chown -R $deployUser:$deployUser $programPath"
fi
-# 如果downloadPath不存在,则创建
+# create if downloadPath does not exist
if ! ssh $host test -e $downloadPath; then
ssh $host "sudo mkdir -p $downloadPath;sudo chown -R $deployUser:$deployUser $downloadPath"
fi
-# 如果$execPath不存在,则创建
+# create if execPath does not exist
if ! ssh $host test -e $execPath; then
ssh $host "sudo mkdir -p $execPath; sudo chown -R $deployUser:$deployUser $execPath"
fi
-# 如果$xlsFilePath不存在,则创建
+# create if xlsFilePath does not exist
if ! ssh $host test -e $xlsFilePath; then
ssh $host "sudo mkdir -p $xlsFilePath; sudo chown -R $deployUser:$deployUser $xlsFilePath"
fi
@@ -410,31 +415,31 @@ fi
done
-# 3,停止服务
-echo "3,停止服务"
-sh ${workDir}/script/stop_all.sh
+# 3,stop server
+echo "3,stop server"
+sh ${workDir}/script/stop-all.sh
-# 4,删除zk节点
-echo "4,删除zk节点"
+# 4,delete zk node
+echo "4,delete zk node"
sleep 1
-python ${workDir}/script/del_zk_node.py $zkQuorum $zkRoot
+python ${workDir}/script/del-zk-node.py $zkQuorum $zkRoot
-# 5,scp资源
-echo "5,scp资源"
-sh ${workDir}/script/scp_hosts.sh
+# 5,scp resources
+echo "5,scp resources"
+sh ${workDir}/script/scp-hosts.sh
if [ $? -eq 0 ]
then
- echo 'scp拷贝完成'
+ echo 'scp copy completed'
else
- echo 'sc 拷贝失败退出'
+ echo 'sc copy failed to exit'
exit -1
fi
-# 6,启动
-echo "6,启动"
-sh ${workDir}/script/start_all.sh
+# 6,startup
+echo "6,startup"
+sh ${workDir}/script/start-all.sh
-# 7,启动监控自启动脚本
+# 7,start monitoring self-starting script
monitor_pid=${workDir}/monitor_server.pid
if [ "true" = $monitorServerState ];then
if [ -f $monitor_pid ]; then
@@ -453,9 +458,8 @@ if [ "true" = $monitorServerState ];then
echo "monitor server running as process ${TARGET_PID}.Stopped success"
rm -f $monitor_pid
fi
- nohup python -u ${workDir}/script/monitor_server.py $installPath $zkQuorum $zkMasters $zkWorkers > ${workDir}/monitor_server.log 2>&1 &
+ nohup python -u ${workDir}/script/monitor-server.py $installPath $zkQuorum $zkMasters $zkWorkers > ${workDir}/monitor-server.log 2>&1 &
echo $! > $monitor_pid
echo "start monitor server success as process `cat $monitor_pid`"
-fi
-
+fi
\ No newline at end of file
diff --git a/package.xml b/package.xml
index 619dfb07cf..153dceec9b 100644
--- a/package.xml
+++ b/package.xml
@@ -70,8 +70,8 @@
script
- start_all.sh
- stop_all.sh
+ start-all.sh
+ stop-all.sh
escheduler-daemon.sh
./bin
diff --git a/pom.xml b/pom.xml
index f8f64313d8..1d1858cd52 100644
--- a/pom.xml
+++ b/pom.xml
@@ -20,6 +20,39 @@
2.7.3
2.2.3
2.9.8
+ 3.5.1
+ 2.0.1
+ 5.0.5
+ 1.2.61
+ 1.1.14
+ 1.3.163
+ 1.6
+ 1.1.1
+ 4.4.1
+ 4.4.1
+ 4.12
+ 5.1.34
+ 1.7.5
+ 1.7.5
+ 3.2.2
+ 2.3
+ 3.5
+ 3.0.1
+ 1.7.0
+ 1.10
+ 1.5
+ 3.17
+ 2.3.21
+ 3.1.0
+ 4.1
+ 20.0
+ 42.1.4
+ 2.1.0
+ 2.4
+ 3.5.0
+ 0.1.52
+ 6.1.0.jre8
+ 6.1.14
@@ -28,22 +61,22 @@
org.mybatis
mybatis
- 3.5.1
+ ${mybatis.version}
org.mybatis
mybatis-spring
- 2.0.1
+ ${mybatis.spring.version}
org.mybatis.spring.boot
mybatis-spring-boot-autoconfigure
- 2.0.1
+ ${mybatis.spring.version}
org.mybatis.spring.boot
mybatis-spring-boot-starter
- 2.0.1
+ ${mybatis.spring.version}
@@ -60,18 +93,18 @@
com.cronutils
cron-utils
- 5.0.5
+ ${cron.utils.version}
com.alibaba
fastjson
- 1.2.29
+ ${fastjson.version}
com.alibaba
druid
- 1.1.14
+ ${druid.version}
@@ -116,7 +149,7 @@
com.h2database
h2
- 1.3.163
+ ${h2.version}
test
@@ -165,22 +198,22 @@
commons-codec
commons-codec
- 1.6
+ ${commons.codec.version}
commons-logging
commons-logging
- 1.1.1
+ ${commons.logging.version}
org.apache.httpcomponents
httpclient
- 4.4.1
+ ${httpclient.version}
org.apache.httpcomponents
httpcore
- 4.4.1
+ ${httpcore.version}
com.fasterxml.jackson.core
@@ -201,56 +234,56 @@
junit
junit
- 4.12
+ ${junit.version}
mysql
mysql-connector-java
- 5.1.34
+ ${mysql.connector.version}
org.slf4j
slf4j-api
- 1.7.5
+ ${slf4j.api.version}
org.slf4j
slf4j-log4j12
- 1.7.5
+ ${slf4j.log4j12.version}
commons-collections
commons-collections
- 3.2.2
+ ${commons.collections.version}
commons-lang
commons-lang
- 2.3
+ ${commons.lang.version}
org.apache.commons
commons-lang3
- 3.5
+ ${commons.lang3.version}
commons-httpclient
commons-httpclient
- 3.0.1
+ ${commons.httpclient}
commons-beanutils
commons-beanutils
- 1.7.0
+ ${commons.beanutils.version}
commons-configuration
commons-configuration
- 1.10
+ ${commons.configuration.version}
@@ -268,20 +301,20 @@
org.apache.commons
commons-email
- 1.5
+ ${commons.email.version}
org.apache.poi
poi
- 3.17
+ ${poi.version}
org.freemarker
freemarker
- 2.3.21
+ ${freemarker.version}
@@ -325,61 +358,61 @@
javax.servlet
javax.servlet-api
- 3.1.0
+ ${javax.servlet.api.version}
org.apache.commons
commons-collections4
- 4.1
+ ${commons.collections4.version}
com.google.guava
guava
- 20.0
+ ${guava.version}
org.postgresql
postgresql
- 42.1.4
+ ${postgresql.version}
org.apache.hive
hive-jdbc
- 2.1.0
+ ${hive.jdbc.version}
commons-io
commons-io
- 2.4
+ ${commons.io.version}
com.github.oshi
oshi-core
- 3.5.0
+ ${oshi.core.version}
ru.yandex.clickhouse
clickhouse-jdbc
- 0.1.52
+ ${clickhouse.jdbc.version}
com.microsoft.sqlserver
mssql-jdbc
- 6.1.0.jre8
+ ${mssql.jdbc.version}
org.mortbay.jetty
jsp-2.1
- 6.1.14
+ ${jsp.version}
@@ -489,4 +522,4 @@
escheduler-rpc
-
\ No newline at end of file
+
diff --git a/script/create_escheduler.sh b/script/create-escheduler.sh
similarity index 91%
rename from script/create_escheduler.sh
rename to script/create-escheduler.sh
index c88da7bb6d..ded20a29b3 100644
--- a/script/create_escheduler.sh
+++ b/script/create-escheduler.sh
@@ -13,7 +13,7 @@ export ESCHEDULER_LIB_JARS=$ESCHEDULER_HOME/lib/*
export ESCHEDULER_OPTS="-server -Xmx1g -Xms1g -Xss512k -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70"
export STOP_TIMEOUT=5
-CLASS=cn.escheduler.dao.upgrade.shell.CreateEscheduler
+CLASS=cn.escheduler.dao.upgrade.shell.CreateDolphinScheduler
exec_command="$ESCHEDULER_OPTS -classpath $ESCHEDULER_CONF_DIR:$ESCHEDULER_LIB_JARS $CLASS"
diff --git a/script/del_zk_node.py b/script/del-zk-node.py
similarity index 100%
rename from script/del_zk_node.py
rename to script/del-zk-node.py
diff --git a/script/env/.escheduler_env.sh b/script/env/.escheduler_env.sh
index 5a08343c84..e1975816d9 100644
--- a/script/env/.escheduler_env.sh
+++ b/script/env/.escheduler_env.sh
@@ -5,5 +5,5 @@ export SPARK_HOME2=/opt/soft/spark2
export PYTHON_HOME=/opt/soft/python
export JAVA_HOME=/opt/soft/java
export HIVE_HOME=/opt/soft/hive
-
-export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH
\ No newline at end of file
+export FLINK_HOME=/opt/soft/flink
+export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH:$FLINK_HOME/bin:$PATH
diff --git a/script/escheduler-daemon.sh b/script/escheduler-daemon.sh
index 99f0dee444..d54272c886 100644
--- a/script/escheduler-daemon.sh
+++ b/script/escheduler-daemon.sh
@@ -47,7 +47,7 @@ elif [ "$command" = "master-server" ]; then
LOG_FILE="-Dspring.config.location=conf/application_master.properties -Ddruid.mysql.usePingMethod=false"
CLASS=cn.escheduler.server.master.MasterServer
elif [ "$command" = "worker-server" ]; then
- LOG_FILE="-Dlogback.configurationFile=conf/worker_logback.xml -Ddruid.mysql.usePingMethod=false"
+ LOG_FILE="-Dspring.config.location=conf/application_worker.properties -Ddruid.mysql.usePingMethod=false"
CLASS=cn.escheduler.server.worker.WorkerServer
elif [ "$command" = "alert-server" ]; then
LOG_FILE="-Dlogback.configurationFile=conf/alert_logback.xml"
diff --git a/script/monitor_server.py b/script/monitor-server.py
similarity index 74%
rename from script/monitor_server.py
rename to script/monitor-server.py
index 5f236cac7e..546104c8f6 100644
--- a/script/monitor_server.py
+++ b/script/monitor-server.py
@@ -1,21 +1,26 @@
#!/usr/bin/env python
# -*- coding:utf-8 -*-
-# Author:qiaozhanwei
'''
-yum 安装pip
+1, yum install pip
yum -y install python-pip
-pip install kazoo 安装
-conda install -c conda-forge kazoo 安装
+2, pip install kazoo
+pip install kazoo
-运行脚本及参数说明:
+or
+
+3, conda install kazoo
+conda install -c conda-forge kazoo
+
+run script and parameter description:
nohup python -u monitor_server.py /data1_1T/escheduler 192.168.xx.xx:2181,192.168.xx.xx:2181,192.168.xx.xx:2181 /escheduler/masters /escheduler/workers> monitor_server.log 2>&1 &
-参数说明如下:
-/data1_1T/escheduler的值来自install.sh中的installPath
-192.168.xx.xx:2181,192.168.xx.xx:2181,192.168.xx.xx:2181的值来自install.sh中的zkQuorum
-/escheduler/masters的值来自install.sh中的zkMasters
-/escheduler/workers的值来自install.sh中的zkWorkers
+the parameters are as follows:
+/data1_1T/escheduler : the value comes from the installPath in install.sh
+192.168.xx.xx:2181,192.168.xx.xx:2181,192.168.xx.xx:2181 : the value comes from zkQuorum in install.sh
+the value comes from zkWorkers in install.sh
+/escheduler/masters : the value comes from zkMasters in install.sh
+/escheduler/workers : the value comes from zkWorkers in install.sh
'''
import sys
import socket
@@ -29,11 +34,11 @@ schedule = sched.scheduler(time.time, time.sleep)
class ZkClient:
def __init__(self):
- # hosts配置zk地址集群
+ # hosts configuration zk address cluster
self.zk = KazooClient(hosts=zookeepers)
self.zk.start()
- # 读取配置文件,组装成字典
+ # read configuration files and assemble them into a dictionary
def read_file(self,path):
with open(path, 'r') as f:
dict = {}
@@ -43,11 +48,11 @@ class ZkClient:
dict[arr[0]] = arr[1]
return dict
- # 根据hostname获取ip地址
+ # get the ip address according to hostname
def get_ip_by_hostname(self,hostname):
return socket.gethostbyname(hostname)
- # 重启服务
+ # restart server
def restart_server(self,inc):
config_dict = self.read_file(install_path + '/conf/config/run_config.conf')
@@ -67,7 +72,7 @@ class ZkClient:
restart_master_list = list(set(master_list) - set(zk_master_list))
if (len(restart_master_list) != 0):
for master in restart_master_list:
- print("master " + self.get_ip_by_hostname(master) + " 服务已经掉了")
+ print("master " + self.get_ip_by_hostname(master) + " server has down")
os.system('ssh ' + self.get_ip_by_hostname(master) + ' sh ' + install_path + '/bin/escheduler-daemon.sh start master-server')
if (self.zk.exists(workers_zk_path)):
@@ -78,15 +83,15 @@ class ZkClient:
restart_worker_list = list(set(worker_list) - set(zk_worker_list))
if (len(restart_worker_list) != 0):
for worker in restart_worker_list:
- print("worker " + self.get_ip_by_hostname(worker) + " 服务已经掉了")
+ print("worker " + self.get_ip_by_hostname(worker) + " server has down")
os.system('ssh ' + self.get_ip_by_hostname(worker) + ' sh ' + install_path + '/bin/escheduler-daemon.sh start worker-server')
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
schedule.enter(inc, 0, self.restart_server, (inc,))
- # 默认参数60s
+ # default parameter 60s
def main(self,inc=60):
- # enter四个参数分别为:间隔事件、优先级(用于同时间到达的两个事件同时执行时定序)、被调用触发的函数,
- # 给该触发函数的参数(tuple形式)
+ # the enter four parameters are: interval event, priority (sequence for simultaneous execution of two events arriving at the same time), function triggered by the call,
+ # the argument to the trigger function (tuple form)
schedule.enter(0, 0, self.restart_server, (inc,))
schedule.run()
if __name__ == '__main__':
@@ -97,4 +102,4 @@ if __name__ == '__main__':
masters_zk_path = sys.argv[3]
workers_zk_path = sys.argv[4]
zkClient = ZkClient()
- zkClient.main(300)
+ zkClient.main(300)
\ No newline at end of file
diff --git a/script/scp_hosts.sh b/script/scp-hosts.sh
old mode 100755
new mode 100644
similarity index 100%
rename from script/scp_hosts.sh
rename to script/scp-hosts.sh
diff --git a/script/start_all.sh b/script/start-all.sh
old mode 100755
new mode 100644
similarity index 100%
rename from script/start_all.sh
rename to script/start-all.sh
diff --git a/script/stop_all.sh b/script/stop-all.sh
old mode 100755
new mode 100644
similarity index 100%
rename from script/stop_all.sh
rename to script/stop-all.sh
diff --git a/script/upgrade_escheduler.sh b/script/upgrade-escheduler.sh
similarity index 91%
rename from script/upgrade_escheduler.sh
rename to script/upgrade-escheduler.sh
index 6bd6439a58..453bd611ac 100644
--- a/script/upgrade_escheduler.sh
+++ b/script/upgrade-escheduler.sh
@@ -13,7 +13,7 @@ export ESCHEDULER_LIB_JARS=$ESCHEDULER_HOME/lib/*
export ESCHEDULER_OPTS="-server -Xmx1g -Xms1g -Xss512k -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70"
export STOP_TIMEOUT=5
-CLASS=cn.escheduler.dao.upgrade.shell.UpgradeEscheduler
+CLASS=cn.escheduler.dao.upgrade.shell.UpgradeDolphinScheduler
exec_command="$ESCHEDULER_OPTS -classpath $ESCHEDULER_CONF_DIR:$ESCHEDULER_LIB_JARS $CLASS"
diff --git a/sql/create/release-1.0.0_schema/mysql/escheduler_ddl.sql b/sql/create/release-1.0.0_schema/mysql/dolphinscheduler_ddl.sql
similarity index 100%
rename from sql/create/release-1.0.0_schema/mysql/escheduler_ddl.sql
rename to sql/create/release-1.0.0_schema/mysql/dolphinscheduler_ddl.sql
diff --git a/sql/create/release-1.0.0_schema/mysql/escheduler_dml.sql b/sql/create/release-1.0.0_schema/mysql/dolphinscheduler_dml.sql
similarity index 100%
rename from sql/create/release-1.0.0_schema/mysql/escheduler_dml.sql
rename to sql/create/release-1.0.0_schema/mysql/dolphinscheduler_dml.sql
diff --git a/sql/create/release-1.2.0_schema/postgresql/dolphinscheduler_ddl.sql b/sql/create/release-1.2.0_schema/postgresql/dolphinscheduler_ddl.sql
new file mode 100644
index 0000000000..3dc3a5b9a3
--- /dev/null
+++ b/sql/create/release-1.2.0_schema/postgresql/dolphinscheduler_ddl.sql
@@ -0,0 +1,804 @@
+DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
+CREATE TABLE QRTZ_BLOB_TRIGGERS (
+ SCHED_NAME varchar(120) NOT NULL,
+ TRIGGER_NAME varchar(200) NOT NULL,
+ TRIGGER_GROUP varchar(200) NOT NULL,
+ BLOB_DATA bytea NULL,
+ PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
+);
+
+--
+-- Table structure for table QRTZ_CALENDARS
+--
+
+DROP TABLE IF EXISTS QRTZ_CALENDARS;
+CREATE TABLE QRTZ_CALENDARS (
+ SCHED_NAME varchar(120) NOT NULL,
+ CALENDAR_NAME varchar(200) NOT NULL,
+ CALENDAR bytea NOT NULL,
+ PRIMARY KEY (SCHED_NAME,CALENDAR_NAME)
+);
+--
+-- Table structure for table QRTZ_CRON_TRIGGERS
+--
+
+DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
+CREATE TABLE QRTZ_CRON_TRIGGERS (
+ SCHED_NAME varchar(120) NOT NULL,
+ TRIGGER_NAME varchar(200) NOT NULL,
+ TRIGGER_GROUP varchar(200) NOT NULL,
+ CRON_EXPRESSION varchar(120) NOT NULL,
+ TIME_ZONE_ID varchar(80) DEFAULT NULL,
+ PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
+);
+
+--
+-- Table structure for table QRTZ_FIRED_TRIGGERS
+--
+
+DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
+CREATE TABLE QRTZ_FIRED_TRIGGERS (
+ SCHED_NAME varchar(120) NOT NULL,
+ ENTRY_ID varchar(95) NOT NULL,
+ TRIGGER_NAME varchar(200) NOT NULL,
+ TRIGGER_GROUP varchar(200) NOT NULL,
+ INSTANCE_NAME varchar(200) NOT NULL,
+ FIRED_TIME bigint NOT NULL,
+ SCHED_TIME bigint NOT NULL,
+ PRIORITY int NOT NULL,
+ STATE varchar(16) NOT NULL,
+ JOB_NAME varchar(200) DEFAULT NULL,
+ JOB_GROUP varchar(200) DEFAULT NULL,
+ IS_NONCONCURRENT varchar(1) DEFAULT NULL,
+ REQUESTS_RECOVERY varchar(1) DEFAULT NULL,
+ PRIMARY KEY (SCHED_NAME,ENTRY_ID)
+) ;
+ create index IDX_QRTZ_FT_TRIG_INST_NAME on QRTZ_FIRED_TRIGGERS (SCHED_NAME,INSTANCE_NAME);
+ create index IDX_QRTZ_FT_INST_JOB_REQ_RCVRY on QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME,REQUESTS_RECOVERY);
+ create index IDX_QRTZ_FT_J_G on QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
+ create index IDX_QRTZ_FT_JG on QRTZ_FIRED_TRIGGERS (SCHED_NAME,JOB_GROUP);
+ create index IDX_QRTZ_FT_T_G on QRTZ_FIRED_TRIGGERS (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP);
+ create index IDX_QRTZ_FT_TG on QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);
+
+--
+-- Table structure for table QRTZ_LOCKS
+--
+
+DROP TABLE IF EXISTS QRTZ_LOCKS;
+CREATE TABLE QRTZ_LOCKS (
+ SCHED_NAME varchar(120) NOT NULL,
+ LOCK_NAME varchar(40) NOT NULL,
+ PRIMARY KEY (SCHED_NAME,LOCK_NAME)
+) ;
+
+--
+-- Table structure for table QRTZ_PAUSED_TRIGGER_GRPS
+--
+
+DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
+CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS (
+ SCHED_NAME varchar(120) NOT NULL,
+ TRIGGER_GROUP varchar(200) NOT NULL,
+ PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP)
+) ;
+
+--
+-- Table structure for table QRTZ_SCHEDULER_STATE
+--
+
+DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
+CREATE TABLE QRTZ_SCHEDULER_STATE (
+ SCHED_NAME varchar(120) NOT NULL,
+ INSTANCE_NAME varchar(200) NOT NULL,
+ LAST_CHECKIN_TIME bigint NOT NULL,
+ CHECKIN_INTERVAL bigint NOT NULL,
+ PRIMARY KEY (SCHED_NAME,INSTANCE_NAME)
+) ;
+
+--
+-- Table structure for table QRTZ_SIMPLE_TRIGGERS
+--
+
+DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
+CREATE TABLE QRTZ_SIMPLE_TRIGGERS (
+ SCHED_NAME varchar(120) NOT NULL,
+ TRIGGER_NAME varchar(200) NOT NULL,
+ TRIGGER_GROUP varchar(200) NOT NULL,
+ REPEAT_COUNT bigint NOT NULL,
+ REPEAT_INTERVAL bigint NOT NULL,
+ TIMES_TRIGGERED bigint NOT NULL,
+ PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
+
+) ;
+
+--
+-- Table structure for table QRTZ_SIMPROP_TRIGGERS
+--
+
+DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
+CREATE TABLE QRTZ_SIMPROP_TRIGGERS (
+ SCHED_NAME varchar(120) NOT NULL,
+ TRIGGER_NAME varchar(200) NOT NULL,
+ TRIGGER_GROUP varchar(200) NOT NULL,
+ STR_PROP_1 varchar(512) DEFAULT NULL,
+ STR_PROP_2 varchar(512) DEFAULT NULL,
+ STR_PROP_3 varchar(512) DEFAULT NULL,
+ INT_PROP_1 int DEFAULT NULL,
+ INT_PROP_2 int DEFAULT NULL,
+ LONG_PROP_1 bigint DEFAULT NULL,
+ LONG_PROP_2 bigint DEFAULT NULL,
+ DEC_PROP_1 decimal(13,4) DEFAULT NULL,
+ DEC_PROP_2 decimal(13,4) DEFAULT NULL,
+ BOOL_PROP_1 varchar(1) DEFAULT NULL,
+ BOOL_PROP_2 varchar(1) DEFAULT NULL,
+ PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
+) ;
+
+--
+-- Table structure for table QRTZ_TRIGGERS
+--
+
+DROP TABLE IF EXISTS QRTZ_TRIGGERS;
+CREATE TABLE QRTZ_TRIGGERS (
+ SCHED_NAME varchar(120) NOT NULL,
+ TRIGGER_NAME varchar(200) NOT NULL,
+ TRIGGER_GROUP varchar(200) NOT NULL,
+ JOB_NAME varchar(200) NOT NULL,
+ JOB_GROUP varchar(200) NOT NULL,
+ DESCRIPTION varchar(250) DEFAULT NULL,
+ NEXT_FIRE_TIME bigint DEFAULT NULL,
+ PREV_FIRE_TIME bigint DEFAULT NULL,
+ PRIORITY int DEFAULT NULL,
+ TRIGGER_STATE varchar(16) NOT NULL,
+ TRIGGER_TYPE varchar(8) NOT NULL,
+ START_TIME bigint NOT NULL,
+ END_TIME bigint DEFAULT NULL,
+ CALENDAR_NAME varchar(200) DEFAULT NULL,
+ MISFIRE_INSTR smallint DEFAULT NULL,
+ JOB_DATA bytea,
+ PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
+) ;
+
+ create index IDX_QRTZ_T_J on QRTZ_TRIGGERS (SCHED_NAME,JOB_NAME,JOB_GROUP);
+ create index IDX_QRTZ_T_JG on QRTZ_TRIGGERS (SCHED_NAME,JOB_GROUP);
+ create index IDX_QRTZ_T_C on QRTZ_TRIGGERS (SCHED_NAME,CALENDAR_NAME);
+ create index IDX_QRTZ_T_G on QRTZ_TRIGGERS (SCHED_NAME,TRIGGER_GROUP);
+ create index IDX_QRTZ_T_STATE on QRTZ_TRIGGERS (SCHED_NAME,TRIGGER_STATE);
+ create index IDX_QRTZ_T_N_STATE on QRTZ_TRIGGERS (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP,TRIGGER_STATE);
+ create index IDX_QRTZ_T_N_G_STATE on QRTZ_TRIGGERS (SCHED_NAME,TRIGGER_GROUP,TRIGGER_STATE);
+ create index IDX_QRTZ_T_NEXT_FIRE_TIME on QRTZ_TRIGGERS (SCHED_NAME,NEXT_FIRE_TIME);
+ create index IDX_QRTZ_T_NFT_ST on QRTZ_TRIGGERS (SCHED_NAME,TRIGGER_STATE,NEXT_FIRE_TIME);
+ create index IDX_QRTZ_T_NFT_MISFIRE on QRTZ_TRIGGERS (SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME);
+ create index IDX_QRTZ_T_NFT_ST_MISFIRE on QRTZ_TRIGGERS (SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_STATE);
+ create index IDX_QRTZ_T_NFT_ST_MISFIRE_GRP on QRTZ_TRIGGERS (SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_GROUP,TRIGGER_STATE);
+
+
+--
+-- Table structure for table QRTZ_JOB_DETAILS
+--
+
+DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
+CREATE TABLE QRTZ_JOB_DETAILS (
+ SCHED_NAME varchar(120) NOT NULL,
+ JOB_NAME varchar(200) NOT NULL,
+ JOB_GROUP varchar(200) NOT NULL,
+ DESCRIPTION varchar(250) DEFAULT NULL,
+ JOB_CLASS_NAME varchar(250) NOT NULL,
+ IS_DURABLE varchar(1) NOT NULL,
+ IS_NONCONCURRENT varchar(1) NOT NULL,
+ IS_UPDATE_DATA varchar(1) NOT NULL,
+ REQUESTS_RECOVERY varchar(1) NOT NULL,
+ JOB_DATA bytea,
+ PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
+) ;
+ create index IDX_QRTZ_J_REQ_RECOVERY on QRTZ_JOB_DETAILS (SCHED_NAME,REQUESTS_RECOVERY);
+ create index IDX_QRTZ_J_GRP on QRTZ_JOB_DETAILS (SCHED_NAME,JOB_GROUP);
+
+alter table QRTZ_BLOB_TRIGGERS drop CONSTRAINT if EXISTS QRTZ_BLOB_TRIGGERS_ibfk_1;
+alter table QRTZ_BLOB_TRIGGERS add CONSTRAINT QRTZ_BLOB_TRIGGERS_ibfk_1 FOREIGN KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP) REFERENCES QRTZ_TRIGGERS (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP);
+
+alter table QRTZ_CRON_TRIGGERS drop CONSTRAINT if EXISTS QRTZ_CRON_TRIGGERS_ibfk_1;
+alter table QRTZ_CRON_TRIGGERS add CONSTRAINT QRTZ_CRON_TRIGGERS_ibfk_1 FOREIGN KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP) REFERENCES QRTZ_TRIGGERS (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP);
+
+alter table QRTZ_SIMPLE_TRIGGERS drop CONSTRAINT if EXISTS QRTZ_SIMPLE_TRIGGERS_ibfk_1;
+alter table QRTZ_SIMPLE_TRIGGERS add CONSTRAINT QRTZ_SIMPLE_TRIGGERS_ibfk_1 FOREIGN KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP) REFERENCES QRTZ_TRIGGERS (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP);
+
+alter table QRTZ_SIMPROP_TRIGGERS drop CONSTRAINT if EXISTS QRTZ_SIMPROP_TRIGGERS_ibfk_1;
+alter table QRTZ_SIMPROP_TRIGGERS add CONSTRAINT QRTZ_SIMPROP_TRIGGERS_ibfk_1 FOREIGN KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP) REFERENCES QRTZ_TRIGGERS (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP);
+
+alter table QRTZ_TRIGGERS drop CONSTRAINT if EXISTS QRTZ_TRIGGERS_ibfk_1;
+alter table QRTZ_TRIGGERS add CONSTRAINT QRTZ_TRIGGERS_ibfk_1 FOREIGN KEY (SCHED_NAME, JOB_NAME, JOB_GROUP) REFERENCES QRTZ_JOB_DETAILS (SCHED_NAME, JOB_NAME, JOB_GROUP);
+
+
+
+--
+-- Table structure for table t_escheduler_access_token
+--
+
+DROP TABLE IF EXISTS t_escheduler_access_token;
+CREATE TABLE t_escheduler_access_token (
+ id int NOT NULL ,
+ user_id int DEFAULT NULL ,
+ token varchar(64) DEFAULT NULL ,
+ expire_time timestamp DEFAULT NULL ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+
+--
+-- Table structure for table t_escheduler_alert
+--
+
+DROP TABLE IF EXISTS t_escheduler_alert;
+CREATE TABLE t_escheduler_alert (
+ id int NOT NULL ,
+ title varchar(64) DEFAULT NULL ,
+ show_type int DEFAULT NULL ,
+ content text ,
+ alert_type int DEFAULT NULL ,
+ alert_status int DEFAULT '0' ,
+ log text ,
+ alertgroup_id int DEFAULT NULL ,
+ receivers text ,
+ receivers_cc text ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+--
+-- Table structure for table t_escheduler_alertgroup
+--
+
+DROP TABLE IF EXISTS t_escheduler_alertgroup;
+CREATE TABLE t_escheduler_alertgroup (
+ id int NOT NULL ,
+ group_name varchar(255) DEFAULT NULL ,
+ group_type int DEFAULT NULL ,
+ "desc" varchar(255) DEFAULT NULL ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+
+--
+-- Table structure for table t_escheduler_command
+--
+
+DROP TABLE IF EXISTS t_escheduler_command;
+CREATE TABLE t_escheduler_command (
+ id int NOT NULL ,
+ command_type int DEFAULT NULL ,
+ process_definition_id int DEFAULT NULL ,
+ command_param text ,
+ task_depend_type int DEFAULT NULL ,
+ failure_strategy int DEFAULT '0' ,
+ warning_type int DEFAULT '0' ,
+ warning_group_id int DEFAULT NULL ,
+ schedule_time timestamp DEFAULT NULL ,
+ start_time timestamp DEFAULT NULL ,
+ executor_id int DEFAULT NULL ,
+ dependence varchar(255) DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ process_instance_priority int DEFAULT NULL ,
+ worker_group_id int DEFAULT '-1' ,
+ PRIMARY KEY (id)
+) ;
+
+--
+-- Table structure for table t_escheduler_datasource
+--
+
+DROP TABLE IF EXISTS t_escheduler_datasource;
+CREATE TABLE t_escheduler_datasource (
+ id int NOT NULL ,
+ name varchar(64) NOT NULL ,
+ note varchar(256) DEFAULT NULL ,
+ type int NOT NULL ,
+ user_id int NOT NULL ,
+ connection_params text NOT NULL ,
+ create_time timestamp NOT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+
+--
+-- Table structure for table t_escheduler_error_command
+--
+
+DROP TABLE IF EXISTS t_escheduler_error_command;
+CREATE TABLE t_escheduler_error_command (
+ id int NOT NULL ,
+ command_type int DEFAULT NULL ,
+ executor_id int DEFAULT NULL ,
+ process_definition_id int DEFAULT NULL ,
+ command_param text ,
+ task_depend_type int DEFAULT NULL ,
+ failure_strategy int DEFAULT '0' ,
+ warning_type int DEFAULT '0' ,
+ warning_group_id int DEFAULT NULL ,
+ schedule_time timestamp DEFAULT NULL ,
+ start_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ dependence text ,
+ process_instance_priority int DEFAULT NULL ,
+ worker_group_id int DEFAULT '-1' ,
+ message text ,
+ PRIMARY KEY (id)
+);
+--
+-- Table structure for table t_escheduler_master_server
+--
+
+DROP TABLE IF EXISTS t_escheduler_master_server;
+CREATE TABLE t_escheduler_master_server (
+ id int NOT NULL ,
+ host varchar(45) DEFAULT NULL ,
+ port int DEFAULT NULL ,
+ zk_directory varchar(64) DEFAULT NULL ,
+ res_info varchar(256) DEFAULT NULL ,
+ create_time timestamp DEFAULT NULL ,
+ last_heartbeat_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+
+--
+-- Table structure for table t_escheduler_process_definition
+--
+
+DROP TABLE IF EXISTS t_escheduler_process_definition;
+CREATE TABLE t_escheduler_process_definition (
+ id int NOT NULL ,
+ name varchar(255) DEFAULT NULL ,
+ version int DEFAULT NULL ,
+ release_state int DEFAULT NULL ,
+ project_id int DEFAULT NULL ,
+ user_id int DEFAULT NULL ,
+ process_definition_json text ,
+ "desc" text ,
+ global_params text ,
+ flag int DEFAULT NULL ,
+ locations text ,
+ connects text ,
+ receivers text ,
+ receivers_cc text ,
+ create_time timestamp DEFAULT NULL ,
+ timeout int DEFAULT '0' ,
+ tenant_id int NOT NULL DEFAULT '-1' ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+
+create index process_definition_index on t_escheduler_process_definition (project_id,id);
+
+--
+-- Table structure for table t_escheduler_process_instance
+--
+
+DROP TABLE IF EXISTS t_escheduler_process_instance;
+CREATE TABLE t_escheduler_process_instance (
+ id int NOT NULL ,
+ name varchar(255) DEFAULT NULL ,
+ process_definition_id int DEFAULT NULL ,
+ state int DEFAULT NULL ,
+ recovery int DEFAULT NULL ,
+ start_time timestamp DEFAULT NULL ,
+ end_time timestamp DEFAULT NULL ,
+ run_times int DEFAULT NULL ,
+ host varchar(45) DEFAULT NULL ,
+ command_type int DEFAULT NULL ,
+ command_param text ,
+ task_depend_type int DEFAULT NULL ,
+ max_try_times int DEFAULT '0' ,
+ failure_strategy int DEFAULT '0' ,
+ warning_type int DEFAULT '0' ,
+ warning_group_id int DEFAULT NULL ,
+ schedule_time timestamp DEFAULT NULL ,
+ command_start_time timestamp DEFAULT NULL ,
+ global_params text ,
+ process_instance_json text ,
+ flag int DEFAULT '1' ,
+ update_time timestamp NULL ,
+ is_sub_process int DEFAULT '0' ,
+ executor_id int NOT NULL ,
+ locations text ,
+ connects text ,
+ history_cmd text ,
+ dependence_schedule_times text ,
+ process_instance_priority int DEFAULT NULL ,
+ worker_group_id int DEFAULT '-1' ,
+ timeout int DEFAULT '0' ,
+ tenant_id int NOT NULL DEFAULT '-1' ,
+ PRIMARY KEY (id)
+) ;
+ create index process_instance_index on t_escheduler_process_instance (process_definition_id,id);
+ create index start_time_index on t_escheduler_process_instance (start_time);
+
+--
+-- Table structure for table t_escheduler_project
+--
+
+DROP TABLE IF EXISTS t_escheduler_project;
+CREATE TABLE t_escheduler_project (
+ id int NOT NULL ,
+ name varchar(100) DEFAULT NULL ,
+ ”desc“ varchar(200) DEFAULT NULL ,
+ user_id int DEFAULT NULL ,
+ flag int DEFAULT '1' ,
+ create_time timestamp DEFAULT CURRENT_TIMESTAMP ,
+ update_time timestamp DEFAULT CURRENT_TIMESTAMP ,
+ PRIMARY KEY (id)
+) ;
+ create index user_id_index on t_escheduler_project (user_id);
+
+--
+-- Table structure for table t_escheduler_queue
+--
+
+DROP TABLE IF EXISTS t_escheduler_queue;
+CREATE TABLE t_escheduler_queue (
+ id int NOT NULL ,
+ queue_name varchar(64) DEFAULT NULL ,
+ queue varchar(64) DEFAULT NULL ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+);
+
+
+--
+-- Table structure for table t_escheduler_relation_datasource_user
+--
+
+DROP TABLE IF EXISTS t_escheduler_relation_datasource_user;
+CREATE TABLE t_escheduler_relation_datasource_user (
+ id int NOT NULL ,
+ user_id int NOT NULL ,
+ datasource_id int DEFAULT NULL ,
+ perm int DEFAULT '1' ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+;
+
+--
+-- Table structure for table t_escheduler_relation_process_instance
+--
+
+DROP TABLE IF EXISTS t_escheduler_relation_process_instance;
+CREATE TABLE t_escheduler_relation_process_instance (
+ id int NOT NULL ,
+ parent_process_instance_id int DEFAULT NULL ,
+ parent_task_instance_id int DEFAULT NULL ,
+ process_instance_id int DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+
+
+--
+-- Table structure for table t_escheduler_relation_project_user
+--
+
+DROP TABLE IF EXISTS t_escheduler_relation_project_user;
+CREATE TABLE t_escheduler_relation_project_user (
+ id int NOT NULL ,
+ user_id int NOT NULL ,
+ project_id int DEFAULT NULL ,
+ perm int DEFAULT '1' ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+create index relation_project_user_id_index on t_escheduler_relation_project_user (user_id);
+
+--
+-- Table structure for table t_escheduler_relation_resources_user
+--
+
+DROP TABLE IF EXISTS t_escheduler_relation_resources_user;
+CREATE TABLE t_escheduler_relation_resources_user (
+ id int NOT NULL ,
+ user_id int NOT NULL ,
+ resources_id int DEFAULT NULL ,
+ perm int DEFAULT '1' ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+
+--
+-- Table structure for table t_escheduler_relation_udfs_user
+--
+
+DROP TABLE IF EXISTS t_escheduler_relation_udfs_user;
+CREATE TABLE t_escheduler_relation_udfs_user (
+ id int NOT NULL ,
+ user_id int NOT NULL ,
+ udf_id int DEFAULT NULL ,
+ perm int DEFAULT '1' ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+;
+
+--
+-- Table structure for table t_escheduler_relation_user_alertgroup
+--
+
+DROP TABLE IF EXISTS t_escheduler_relation_user_alertgroup;
+CREATE TABLE t_escheduler_relation_user_alertgroup (
+ id int NOT NULL,
+ alertgroup_id int DEFAULT NULL,
+ user_id int DEFAULT NULL,
+ create_time timestamp DEFAULT NULL,
+ update_time timestamp DEFAULT NULL,
+ PRIMARY KEY (id)
+);
+
+--
+-- Table structure for table t_escheduler_resources
+--
+
+DROP TABLE IF EXISTS t_escheduler_resources;
+CREATE TABLE t_escheduler_resources (
+ id int NOT NULL ,
+ alias varchar(64) DEFAULT NULL ,
+ file_name varchar(64) DEFAULT NULL ,
+ "desc" varchar(256) DEFAULT NULL ,
+ user_id int DEFAULT NULL ,
+ type int DEFAULT NULL ,
+ size bigint DEFAULT NULL ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+;
+
+--
+-- Table structure for table t_escheduler_schedules
+--
+
+DROP TABLE IF EXISTS t_escheduler_schedules;
+CREATE TABLE t_escheduler_schedules (
+ id int NOT NULL ,
+ process_definition_id int NOT NULL ,
+ start_time timestamp NOT NULL ,
+ end_time timestamp NOT NULL ,
+ crontab varchar(256) NOT NULL ,
+ failure_strategy int NOT NULL ,
+ user_id int NOT NULL ,
+ release_state int NOT NULL ,
+ warning_type int NOT NULL ,
+ warning_group_id int DEFAULT NULL ,
+ process_instance_priority int DEFAULT NULL ,
+ worker_group_id int DEFAULT '-1' ,
+ create_time timestamp NOT NULL ,
+ update_time timestamp NOT NULL ,
+ PRIMARY KEY (id)
+);
+
+--
+-- Table structure for table t_escheduler_session
+--
+
+DROP TABLE IF EXISTS t_escheduler_session;
+CREATE TABLE t_escheduler_session (
+ id varchar(64) NOT NULL ,
+ user_id int DEFAULT NULL ,
+ ip varchar(45) DEFAULT NULL ,
+ last_login_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+);
+
+--
+-- Table structure for table t_escheduler_task_instance
+--
+
+DROP TABLE IF EXISTS t_escheduler_task_instance;
+CREATE TABLE t_escheduler_task_instance (
+ id int NOT NULL ,
+ name varchar(255) DEFAULT NULL ,
+ task_type varchar(64) DEFAULT NULL ,
+ process_definition_id int DEFAULT NULL ,
+ process_instance_id int DEFAULT NULL ,
+ task_json text ,
+ state int DEFAULT NULL ,
+ submit_time timestamp DEFAULT NULL ,
+ start_time timestamp DEFAULT NULL ,
+ end_time timestamp DEFAULT NULL ,
+ host varchar(45) DEFAULT NULL ,
+ execute_path varchar(200) DEFAULT NULL ,
+ log_path varchar(200) DEFAULT NULL ,
+ alert_flag int DEFAULT NULL ,
+ retry_times int DEFAULT '0' ,
+ pid int DEFAULT NULL ,
+ app_link varchar(255) DEFAULT NULL ,
+ flag int DEFAULT '1' ,
+ retry_interval int DEFAULT NULL ,
+ max_retry_times int DEFAULT NULL ,
+ task_instance_priority int DEFAULT NULL ,
+ worker_group_id int DEFAULT '-1' ,
+ PRIMARY KEY (id)
+) ;
+
+--
+-- Table structure for table t_escheduler_tenant
+--
+
+DROP TABLE IF EXISTS t_escheduler_tenant;
+CREATE TABLE t_escheduler_tenant (
+ id int NOT NULL ,
+ tenant_code varchar(64) DEFAULT NULL ,
+ tenant_name varchar(64) DEFAULT NULL ,
+ "desc" varchar(256) DEFAULT NULL ,
+ queue_id int DEFAULT NULL ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+
+--
+-- Table structure for table t_escheduler_udfs
+--
+
+DROP TABLE IF EXISTS t_escheduler_udfs;
+CREATE TABLE t_escheduler_udfs (
+ id int NOT NULL ,
+ user_id int NOT NULL ,
+ func_name varchar(100) NOT NULL ,
+ class_name varchar(255) NOT NULL ,
+ type int NOT NULL ,
+ arg_types varchar(255) DEFAULT NULL ,
+ database varchar(255) DEFAULT NULL ,
+ "desc" varchar(255) DEFAULT NULL ,
+ resource_id int NOT NULL ,
+ resource_name varchar(255) NOT NULL ,
+ create_time timestamp NOT NULL ,
+ update_time timestamp NOT NULL ,
+ PRIMARY KEY (id)
+) ;
+
+--
+-- Table structure for table t_escheduler_user
+--
+
+DROP TABLE IF EXISTS t_escheduler_user;
+CREATE TABLE t_escheduler_user (
+ id int NOT NULL ,
+ user_name varchar(64) DEFAULT NULL ,
+ user_password varchar(64) DEFAULT NULL ,
+ user_type int DEFAULT NULL ,
+ email varchar(64) DEFAULT NULL ,
+ phone varchar(11) DEFAULT NULL ,
+ tenant_id int DEFAULT NULL ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ queue varchar(64) DEFAULT NULL ,
+ PRIMARY KEY (id)
+);
+
+--
+-- Table structure for table t_escheduler_version
+--
+
+DROP TABLE IF EXISTS t_escheduler_version;
+CREATE TABLE t_escheduler_version (
+ id int NOT NULL ,
+ version varchar(200) NOT NULL,
+ PRIMARY KEY (id)
+) ;
+create index version_index on t_escheduler_version(version);
+
+--
+-- Table structure for table t_escheduler_worker_group
+--
+
+DROP TABLE IF EXISTS t_escheduler_worker_group;
+CREATE TABLE t_escheduler_worker_group (
+ id bigint NOT NULL ,
+ name varchar(256) DEFAULT NULL ,
+ ip_list varchar(256) DEFAULT NULL ,
+ create_time timestamp DEFAULT NULL ,
+ update_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+
+--
+-- Table structure for table t_escheduler_worker_server
+--
+
+DROP TABLE IF EXISTS t_escheduler_worker_server;
+CREATE TABLE t_escheduler_worker_server (
+ id int NOT NULL ,
+ host varchar(45) DEFAULT NULL ,
+ port int DEFAULT NULL ,
+ zk_directory varchar(64) DEFAULT NULL ,
+ res_info varchar(255) DEFAULT NULL ,
+ create_time timestamp DEFAULT NULL ,
+ last_heartbeat_time timestamp DEFAULT NULL ,
+ PRIMARY KEY (id)
+) ;
+
+
+DROP SEQUENCE IF EXISTS t_escheduler_access_token_id_sequence;
+CREATE SEQUENCE t_escheduler_access_token_id_sequence;
+ALTER TABLE t_escheduler_access_token ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_access_token_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_alert_id_sequence;
+CREATE SEQUENCE t_escheduler_alert_id_sequence;
+ALTER TABLE t_escheduler_alert ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_alert_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_alertgroup_id_sequence;
+CREATE SEQUENCE t_escheduler_alertgroup_id_sequence;
+ALTER TABLE t_escheduler_alertgroup ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_alertgroup_id_sequence');
+
+DROP SEQUENCE IF EXISTS t_escheduler_command_id_sequence;
+CREATE SEQUENCE t_escheduler_command_id_sequence;
+ALTER TABLE t_escheduler_command ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_command_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_datasource_id_sequence;
+CREATE SEQUENCE t_escheduler_datasource_id_sequence;
+ALTER TABLE t_escheduler_datasource ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_datasource_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_master_server_id_sequence;
+CREATE SEQUENCE t_escheduler_master_server_id_sequence;
+ALTER TABLE t_escheduler_master_server ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_master_server_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_process_definition_id_sequence;
+CREATE SEQUENCE t_escheduler_process_definition_id_sequence;
+ALTER TABLE t_escheduler_process_definition ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_process_definition_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_process_instance_id_sequence;
+CREATE SEQUENCE t_escheduler_process_instance_id_sequence;
+ALTER TABLE t_escheduler_process_instance ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_process_instance_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_project_id_sequence;
+CREATE SEQUENCE t_escheduler_project_id_sequence;
+ALTER TABLE t_escheduler_project ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_project_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_queue_id_sequence;
+CREATE SEQUENCE t_escheduler_queue_id_sequence;
+ALTER TABLE t_escheduler_queue ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_queue_id_sequence');
+
+DROP SEQUENCE IF EXISTS t_escheduler_relation_datasource_user_id_sequence;
+CREATE SEQUENCE t_escheduler_relation_datasource_user_id_sequence;
+ALTER TABLE t_escheduler_relation_datasource_user ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_relation_datasource_user_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_relation_process_instance_id_sequence;
+CREATE SEQUENCE t_escheduler_relation_process_instance_id_sequence;
+ALTER TABLE t_escheduler_relation_process_instance ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_relation_process_instance_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_relation_project_user_id_sequence;
+CREATE SEQUENCE t_escheduler_relation_project_user_id_sequence;
+ALTER TABLE t_escheduler_relation_project_user ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_relation_project_user_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_relation_resources_user_id_sequence;
+CREATE SEQUENCE t_escheduler_relation_resources_user_id_sequence;
+ALTER TABLE t_escheduler_relation_resources_user ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_relation_resources_user_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_relation_udfs_user_id_sequence;
+CREATE SEQUENCE t_escheduler_relation_udfs_user_id_sequence;
+ALTER TABLE t_escheduler_relation_udfs_user ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_relation_udfs_user_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_relation_user_alertgroup_id_sequence;
+CREATE SEQUENCE t_escheduler_relation_user_alertgroup_id_sequence;
+ALTER TABLE t_escheduler_relation_user_alertgroup ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_relation_user_alertgroup_id_sequence');
+
+DROP SEQUENCE IF EXISTS t_escheduler_resources_id_sequence;
+CREATE SEQUENCE t_escheduler_resources_id_sequence;
+ALTER TABLE t_escheduler_resources ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_resources_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_schedules_id_sequence;
+CREATE SEQUENCE t_escheduler_schedules_id_sequence;
+ALTER TABLE t_escheduler_schedules ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_schedules_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_task_instance_id_sequence;
+CREATE SEQUENCE t_escheduler_task_instance_id_sequence;
+ALTER TABLE t_escheduler_task_instance ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_task_instance_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_tenant_id_sequence;
+CREATE SEQUENCE t_escheduler_tenant_id_sequence;
+ALTER TABLE t_escheduler_tenant ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_tenant_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_udfs_id_sequence;
+CREATE SEQUENCE t_escheduler_udfs_id_sequence;
+ALTER TABLE t_escheduler_udfs ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_udfs_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_user_id_sequence;
+CREATE SEQUENCE t_escheduler_user_id_sequence;
+ALTER TABLE t_escheduler_user ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_user_id_sequence');
+
+DROP SEQUENCE IF EXISTS t_escheduler_version_id_sequence;
+CREATE SEQUENCE t_escheduler_version_id_sequence;
+ALTER TABLE t_escheduler_version ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_version_id_sequence');
+
+DROP SEQUENCE IF EXISTS t_escheduler_worker_group_id_sequence;
+CREATE SEQUENCE t_escheduler_worker_group_id_sequence;
+ALTER TABLE t_escheduler_worker_group ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_worker_group_id_sequence');
+DROP SEQUENCE IF EXISTS t_escheduler_worker_server_id_sequence;
+CREATE SEQUENCE t_escheduler_worker_server_id_sequence;
+ALTER TABLE t_escheduler_worker_server ALTER COLUMN id SET DEFAULT NEXTVAL('t_escheduler_worker_server_id_sequence');
\ No newline at end of file
diff --git a/sql/create/release-1.2.0_schema/postgresql/dolphinscheduler_dml.sql b/sql/create/release-1.2.0_schema/postgresql/dolphinscheduler_dml.sql
new file mode 100644
index 0000000000..72e60ace3b
--- /dev/null
+++ b/sql/create/release-1.2.0_schema/postgresql/dolphinscheduler_dml.sql
@@ -0,0 +1,8 @@
+-- Records of t_escheduler_user,user : admin , password : escheduler123
+INSERT INTO "t_escheduler_user" VALUES ('1', 'admin', '055a97b5fcd6d120372ad1976518f371', '0', 'xxx@qq.com', 'xx', '0', '2018-03-27 15:48:50', '2018-10-24 17:40:22');
+INSERT INTO "t_escheduler_alertgroup" VALUES (1, 'escheduler管理员告警组', '0', 'escheduler管理员告警组','2018-11-29 10:20:39', '2018-11-29 10:20:39');
+INSERT INTO "t_escheduler_relation_user_alertgroup" VALUES ('1', '1', '1', '2018-11-29 10:22:33', '2018-11-29 10:22:33');
+
+-- Records of t_escheduler_queue,default queue name : default
+INSERT INTO "t_escheduler_queue" VALUES ('1', 'default', 'default');
+INSERT INTO "t_escheduler_version" VALUES ('1', '1.2.0');
\ No newline at end of file
diff --git a/sql/soft_version b/sql/soft_version
index 1cc5f657e0..867e52437a 100644
--- a/sql/soft_version
+++ b/sql/soft_version
@@ -1 +1 @@
-1.1.0
\ No newline at end of file
+1.2.0
\ No newline at end of file
diff --git a/sql/upgrade/1.0.1_schema/mysql/escheduler_ddl.sql b/sql/upgrade/1.0.1_schema/mysql/dolphinscheduler_ddl.sql
similarity index 100%
rename from sql/upgrade/1.0.1_schema/mysql/escheduler_ddl.sql
rename to sql/upgrade/1.0.1_schema/mysql/dolphinscheduler_ddl.sql
diff --git a/sql/upgrade/1.0.1_schema/mysql/escheduler_dml.sql b/sql/upgrade/1.0.1_schema/mysql/dolphinscheduler_dml.sql
similarity index 100%
rename from sql/upgrade/1.0.1_schema/mysql/escheduler_dml.sql
rename to sql/upgrade/1.0.1_schema/mysql/dolphinscheduler_dml.sql
diff --git a/sql/upgrade/1.0.2_schema/mysql/escheduler_ddl.sql b/sql/upgrade/1.0.2_schema/mysql/dolphinscheduler_ddl.sql
similarity index 100%
rename from sql/upgrade/1.0.2_schema/mysql/escheduler_ddl.sql
rename to sql/upgrade/1.0.2_schema/mysql/dolphinscheduler_ddl.sql
diff --git a/sql/upgrade/1.0.2_schema/mysql/escheduler_dml.sql b/sql/upgrade/1.0.2_schema/mysql/dolphinscheduler_dml.sql
similarity index 100%
rename from sql/upgrade/1.0.2_schema/mysql/escheduler_dml.sql
rename to sql/upgrade/1.0.2_schema/mysql/dolphinscheduler_dml.sql
diff --git a/sql/upgrade/1.1.0_schema/mysql/escheduler_ddl.sql b/sql/upgrade/1.1.0_schema/mysql/dolphinscheduler_ddl.sql
similarity index 100%
rename from sql/upgrade/1.1.0_schema/mysql/escheduler_ddl.sql
rename to sql/upgrade/1.1.0_schema/mysql/dolphinscheduler_ddl.sql
diff --git a/sql/upgrade/1.1.0_schema/mysql/escheduler_dml.sql b/sql/upgrade/1.1.0_schema/mysql/dolphinscheduler_dml.sql
similarity index 100%
rename from sql/upgrade/1.1.0_schema/mysql/escheduler_dml.sql
rename to sql/upgrade/1.1.0_schema/mysql/dolphinscheduler_dml.sql
diff --git a/sql/upgrade/1.2.0_schema/mysql/dolphinscheduler_ddl.sql b/sql/upgrade/1.2.0_schema/mysql/dolphinscheduler_ddl.sql
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/sql/upgrade/1.2.0_schema/mysql/dolphinscheduler_dml.sql b/sql/upgrade/1.2.0_schema/mysql/dolphinscheduler_dml.sql
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/sql/upgrade/1.2.0_schema/postgresql/dolphinscheduler_ddl.sql b/sql/upgrade/1.2.0_schema/postgresql/dolphinscheduler_ddl.sql
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/sql/upgrade/1.2.0_schema/postgresql/dolphinscheduler_dml.sql b/sql/upgrade/1.2.0_schema/postgresql/dolphinscheduler_dml.sql
new file mode 100644
index 0000000000..e69de29bb2
 +
+ 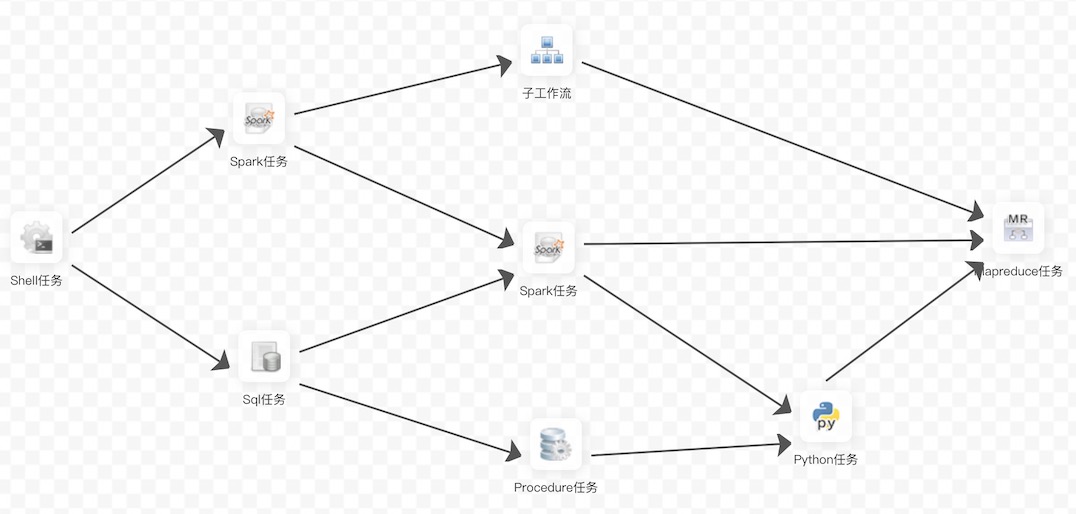
 +
+ 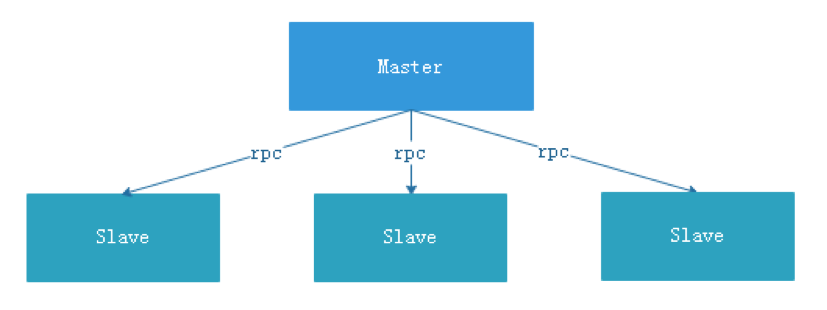
 - In the decentralized design, there is usually no Master/Slave concept, all roles are the same, the status is equal, the global Internet is a typical decentralized distributed system, networked arbitrary node equipment down machine , all will only affect a small range of features.
@@ -141,13 +141,13 @@ EasyScheduler uses ZooKeeper distributed locks to implement only one Master to e
1. The core process algorithm for obtaining distributed locks is as follows
- In the decentralized design, there is usually no Master/Slave concept, all roles are the same, the status is equal, the global Internet is a typical decentralized distributed system, networked arbitrary node equipment down machine , all will only affect a small range of features.
@@ -141,13 +141,13 @@ EasyScheduler uses ZooKeeper distributed locks to implement only one Master to e
1. The core process algorithm for obtaining distributed locks is as follows
 +
+ 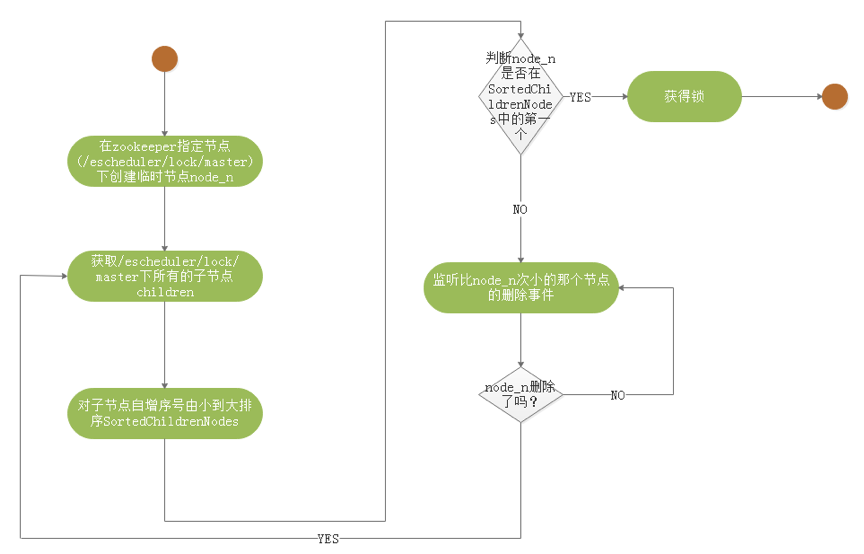
 +
+ 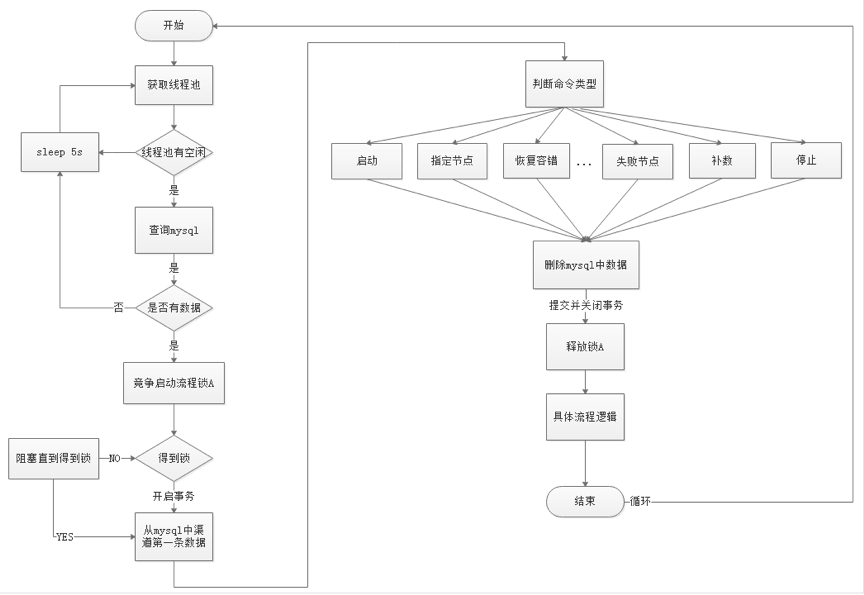
 +
+ 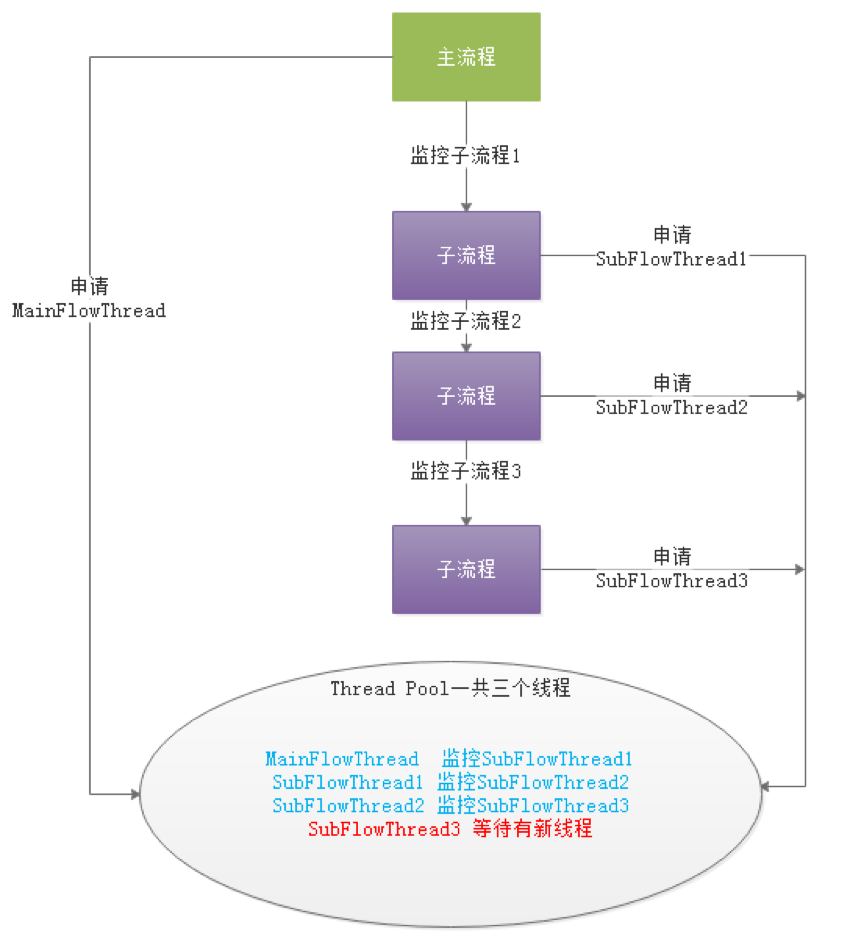
 +
+ 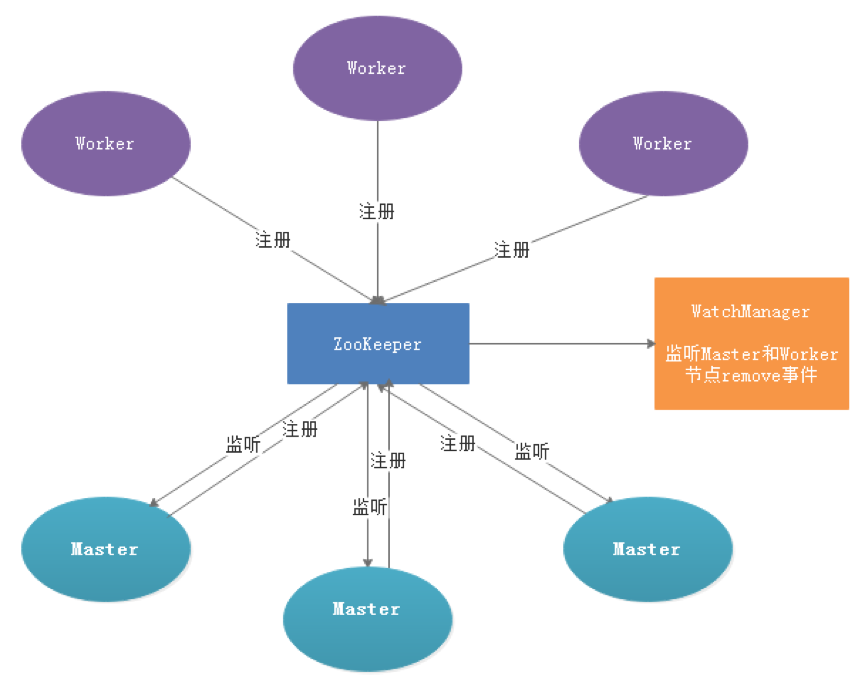
 +
+ 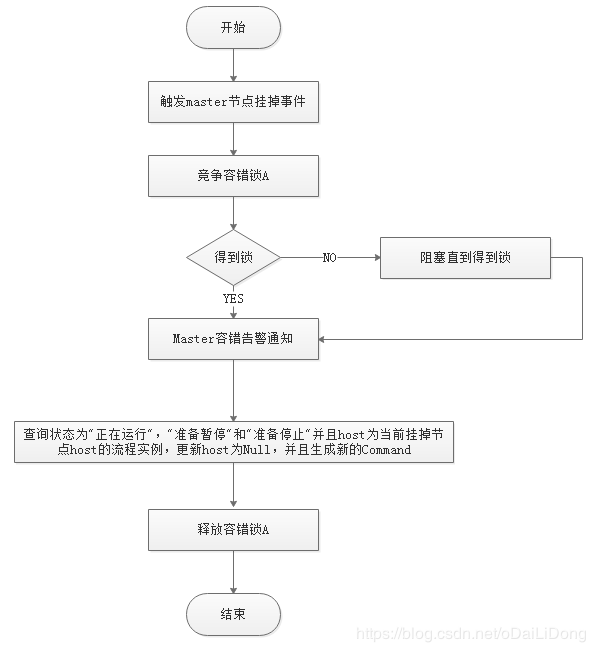
 +
+ 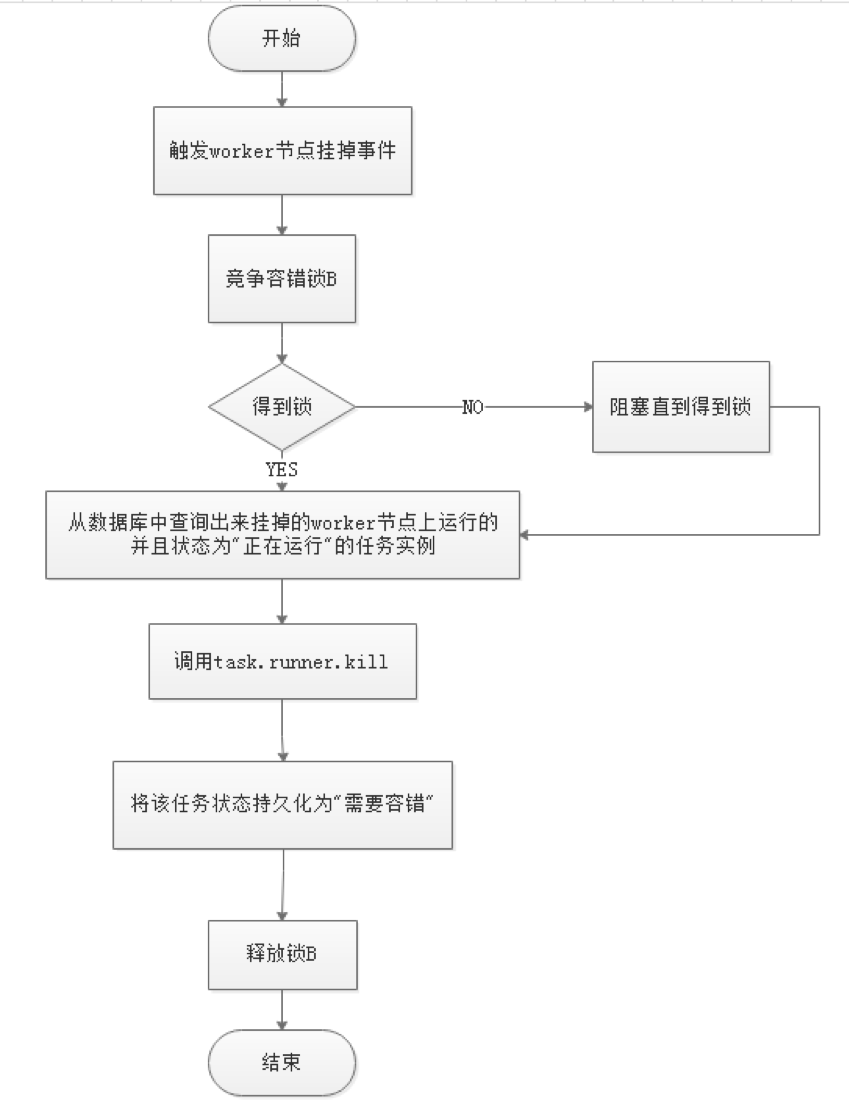
 +
+ 
 +
+ 
 +
+ 

 -- Datasource: The data source type of stored procedure supports MySQL and POSTGRRESQL, and chooses the corresponding data source.
+- Datasource: The data source type of stored procedure supports MySQL and POSTGRESQL, and chooses the corresponding data source.
- Method: The method name of the stored procedure
- Custom parameters: Custom parameter types of stored procedures support IN and OUT, and data types support nine data types: VARCHAR, INTEGER, LONG, FLOAT, DOUBLE, DATE, TIME, TIMESTAMP and BOOLEAN.
diff --git a/docs/en_US/upgrade.md b/docs/en_US/upgrade.md
index 47bfc19f18..b5c743fd84 100644
--- a/docs/en_US/upgrade.md
+++ b/docs/en_US/upgrade.md
@@ -5,7 +5,7 @@
## 2. Stop all services of escheduler
- `sh ./script/stop_all.sh`
+ `sh ./script/stop-all.sh`
## 3. Download the new version of the installation package
@@ -23,7 +23,7 @@
- Execute database upgrade script
-`sh ./script/upgrade_escheduler.sh`
+`sh ./script/upgrade-escheduler.sh`
## 5. Backend service upgrade
diff --git a/docs/zh_CN/前端开发文档.md b/docs/zh_CN/前端开发文档.md
index b3e8aa82d9..f805f5ed8c 100644
--- a/docs/zh_CN/前端开发文档.md
+++ b/docs/zh_CN/前端开发文档.md
@@ -64,7 +64,7 @@ npm install node-sass --unsafe-perm //单独安装node-sass依赖
访问地址 `http://localhost:8888/#/`
-#### Liunx下使用node启动并且守护进程
+#### Linux下使用node启动并且守护进程
安装pm2 `npm install -g pm2`
@@ -237,7 +237,7 @@ export default {
├── conditions
├── conditions.vue
└── _source
- └── serach.vue
+ └── search.vue
└── util.js
```
diff --git a/docs/zh_CN/升级文档.md b/docs/zh_CN/升级文档.md
index f7bafff6c1..83166971fc 100644
--- a/docs/zh_CN/升级文档.md
+++ b/docs/zh_CN/升级文档.md
@@ -5,7 +5,7 @@
## 2. 停止escheduler所有服务
- `sh ./script/stop_all.sh`
+ `sh ./script/stop-all.sh`
## 3. 下载新版本的安装包
@@ -23,7 +23,7 @@
- 执行数据库升级脚本
-`sh ./script/upgrade_escheduler.sh`
+`sh ./script/upgrade-escheduler.sh`
## 5. 后端服务升级
diff --git a/docs/zh_CN/后端部署文档.md b/docs/zh_CN/后端部署文档.md
index 8ab315a355..bf217880a5 100644
--- a/docs/zh_CN/后端部署文档.md
+++ b/docs/zh_CN/后端部署文档.md
@@ -63,7 +63,7 @@ escheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL
```
执行创建表和导入基础数据脚本
```
- sh ./script/create_escheduler.sh
+ sh ./script/create-escheduler.sh
```
#### 准备五: 修改部署目录权限及运行参数
@@ -164,11 +164,11 @@ install.sh : 一键部署脚本
* 一键停止集群所有服务
- ` sh ./bin/stop_all.sh`
+ ` sh ./bin/stop-all.sh`
* 一键开启集群所有服务
- ` sh ./bin/start_all.sh`
+ ` sh ./bin/start-all.sh`
* 启停Master
@@ -206,5 +206,5 @@ sh ./bin/escheduler-daemon.sh stop alert-server
## 3、数据库升级
数据库升级是在1.0.2版本增加的功能,执行以下命令即可自动升级数据库
```
-sh ./script/upgrade_escheduler.sh
+sh ./script/upgrade-escheduler.sh
```
diff --git a/docs/zh_CN/系统使用手册.md b/docs/zh_CN/系统使用手册.md
index 2e5ee635b3..348cc2b36a 100644
--- a/docs/zh_CN/系统使用手册.md
+++ b/docs/zh_CN/系统使用手册.md
@@ -110,7 +110,7 @@
> 点击任务实例节点,点击**查看历史**,可以查看该工作流实例运行的该任务实例列表
-- Datasource: The data source type of stored procedure supports MySQL and POSTGRRESQL, and chooses the corresponding data source.
+- Datasource: The data source type of stored procedure supports MySQL and POSTGRESQL, and chooses the corresponding data source.
- Method: The method name of the stored procedure
- Custom parameters: Custom parameter types of stored procedures support IN and OUT, and data types support nine data types: VARCHAR, INTEGER, LONG, FLOAT, DOUBLE, DATE, TIME, TIMESTAMP and BOOLEAN.
diff --git a/docs/en_US/upgrade.md b/docs/en_US/upgrade.md
index 47bfc19f18..b5c743fd84 100644
--- a/docs/en_US/upgrade.md
+++ b/docs/en_US/upgrade.md
@@ -5,7 +5,7 @@
## 2. Stop all services of escheduler
- `sh ./script/stop_all.sh`
+ `sh ./script/stop-all.sh`
## 3. Download the new version of the installation package
@@ -23,7 +23,7 @@
- Execute database upgrade script
-`sh ./script/upgrade_escheduler.sh`
+`sh ./script/upgrade-escheduler.sh`
## 5. Backend service upgrade
diff --git a/docs/zh_CN/前端开发文档.md b/docs/zh_CN/前端开发文档.md
index b3e8aa82d9..f805f5ed8c 100644
--- a/docs/zh_CN/前端开发文档.md
+++ b/docs/zh_CN/前端开发文档.md
@@ -64,7 +64,7 @@ npm install node-sass --unsafe-perm //单独安装node-sass依赖
访问地址 `http://localhost:8888/#/`
-#### Liunx下使用node启动并且守护进程
+#### Linux下使用node启动并且守护进程
安装pm2 `npm install -g pm2`
@@ -237,7 +237,7 @@ export default {
├── conditions
├── conditions.vue
└── _source
- └── serach.vue
+ └── search.vue
└── util.js
```
diff --git a/docs/zh_CN/升级文档.md b/docs/zh_CN/升级文档.md
index f7bafff6c1..83166971fc 100644
--- a/docs/zh_CN/升级文档.md
+++ b/docs/zh_CN/升级文档.md
@@ -5,7 +5,7 @@
## 2. 停止escheduler所有服务
- `sh ./script/stop_all.sh`
+ `sh ./script/stop-all.sh`
## 3. 下载新版本的安装包
@@ -23,7 +23,7 @@
- 执行数据库升级脚本
-`sh ./script/upgrade_escheduler.sh`
+`sh ./script/upgrade-escheduler.sh`
## 5. 后端服务升级
diff --git a/docs/zh_CN/后端部署文档.md b/docs/zh_CN/后端部署文档.md
index 8ab315a355..bf217880a5 100644
--- a/docs/zh_CN/后端部署文档.md
+++ b/docs/zh_CN/后端部署文档.md
@@ -63,7 +63,7 @@ escheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL
```
执行创建表和导入基础数据脚本
```
- sh ./script/create_escheduler.sh
+ sh ./script/create-escheduler.sh
```
#### 准备五: 修改部署目录权限及运行参数
@@ -164,11 +164,11 @@ install.sh : 一键部署脚本
* 一键停止集群所有服务
- ` sh ./bin/stop_all.sh`
+ ` sh ./bin/stop-all.sh`
* 一键开启集群所有服务
- ` sh ./bin/start_all.sh`
+ ` sh ./bin/start-all.sh`
* 启停Master
@@ -206,5 +206,5 @@ sh ./bin/escheduler-daemon.sh stop alert-server
## 3、数据库升级
数据库升级是在1.0.2版本增加的功能,执行以下命令即可自动升级数据库
```
-sh ./script/upgrade_escheduler.sh
+sh ./script/upgrade-escheduler.sh
```
diff --git a/docs/zh_CN/系统使用手册.md b/docs/zh_CN/系统使用手册.md
index 2e5ee635b3..348cc2b36a 100644
--- a/docs/zh_CN/系统使用手册.md
+++ b/docs/zh_CN/系统使用手册.md
@@ -110,7 +110,7 @@
> 点击任务实例节点,点击**查看历史**,可以查看该工作流实例运行的该任务实例列表
 +
+ 
 +
+