 +
+
+
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+ >  + >
+ >
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+
+
+
+
+
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+ 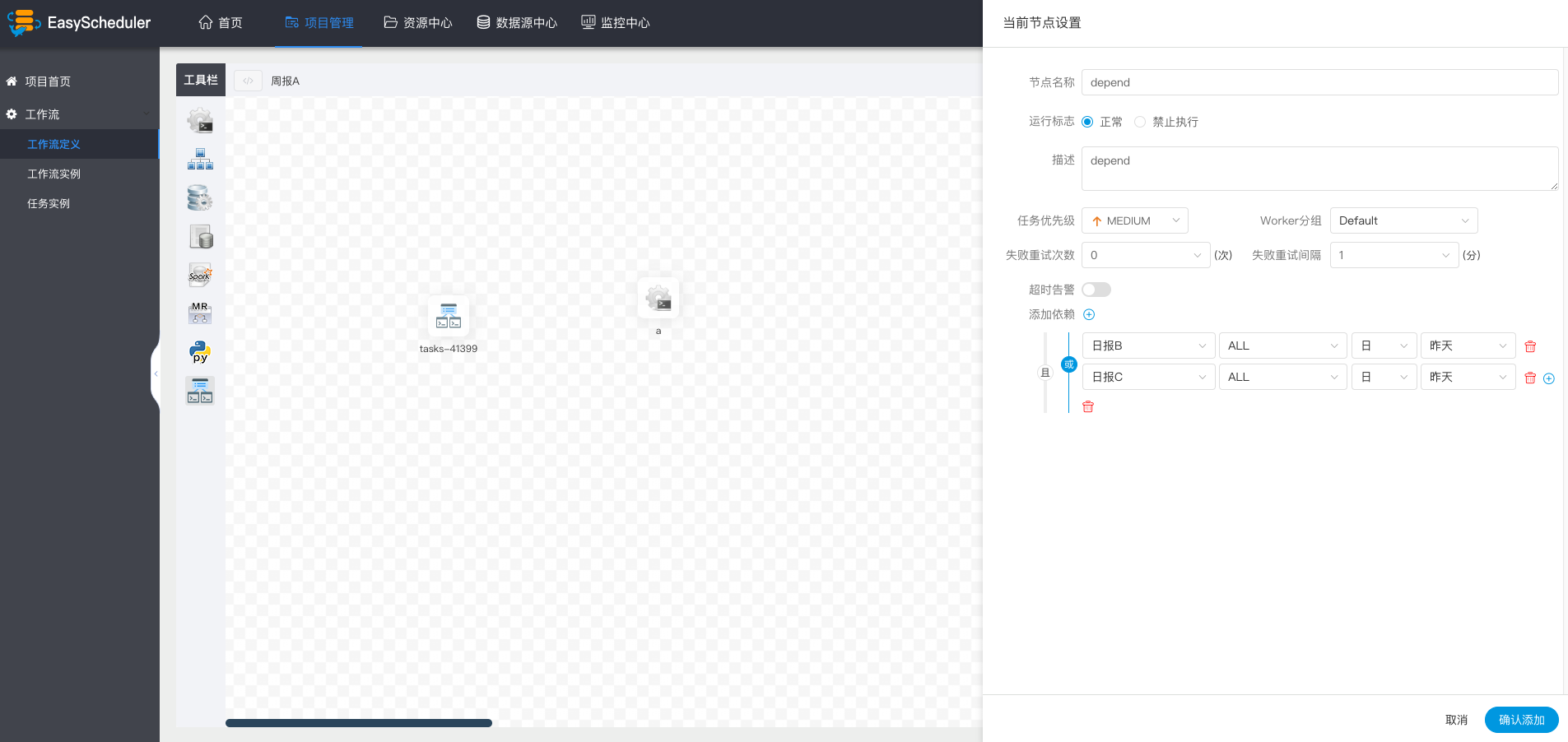 +
+
+ 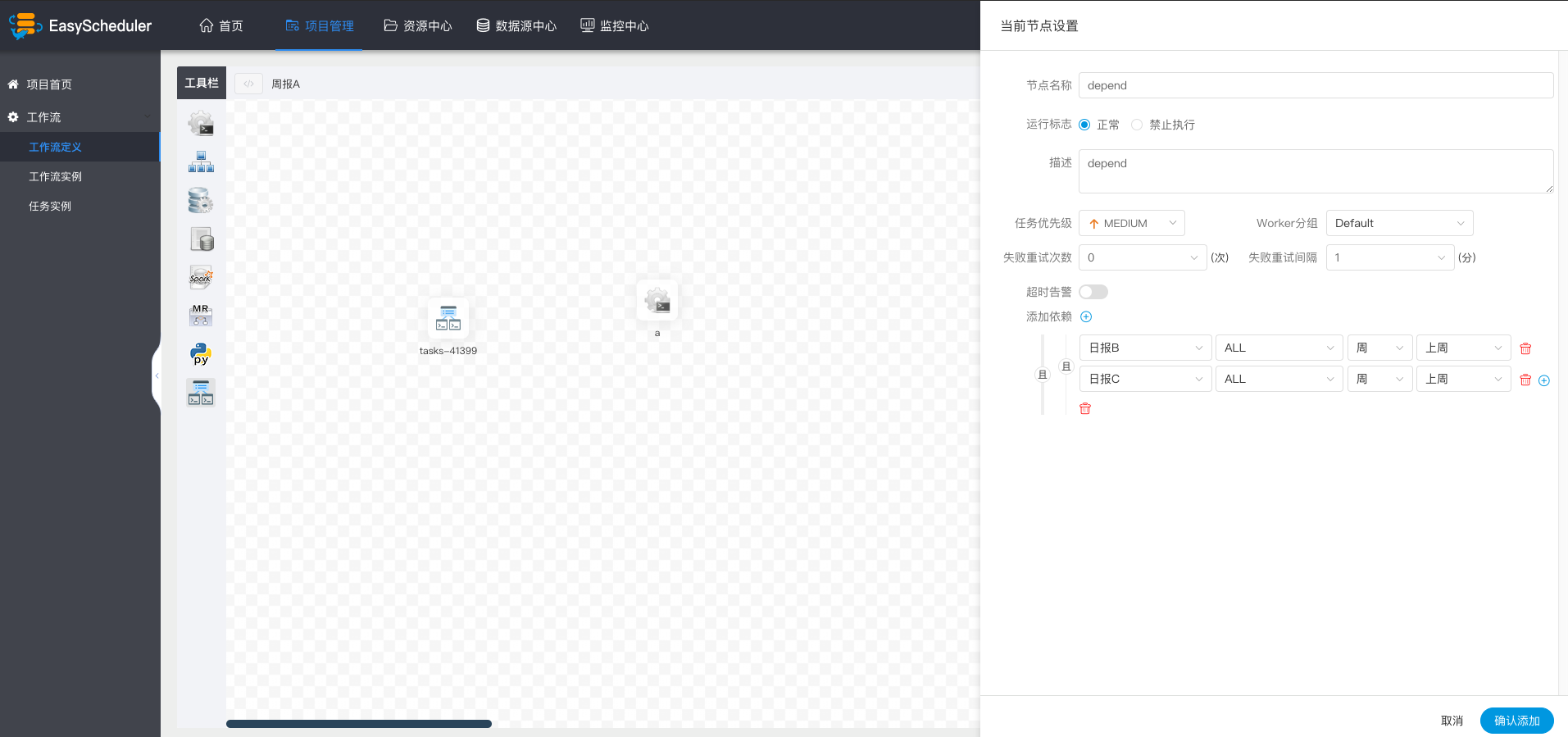 +
+
+ 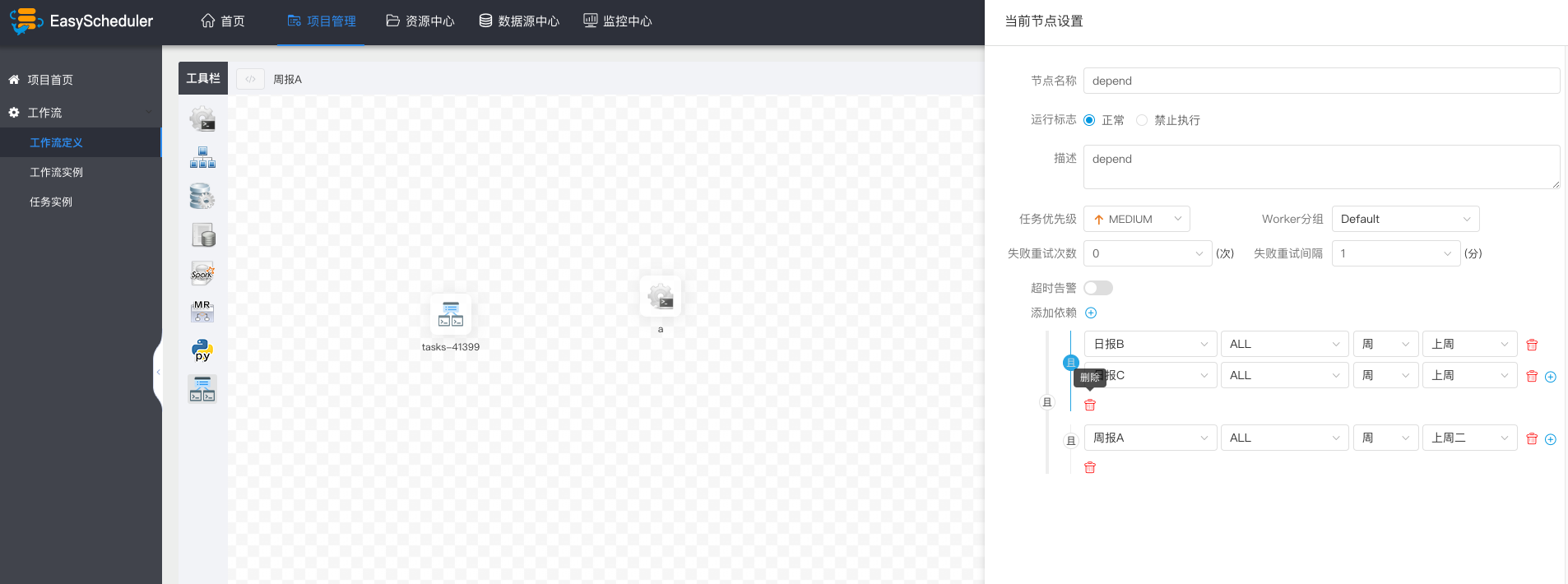 +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
| variable | meaning |
|---|---|
| ${system.biz.date} | +The timing time of routine dispatching instance is one day before, in yyyyyMMdd format. When data is supplemented, the date + 1 | +
| ${system.biz.curdate} | +Daily scheduling example timing time, format is yyyyyMMdd, when supplementing data, the date + 1 | +
| ${system.datetime} | +Daily scheduling example timing time, format is yyyyyMMddHmmss, when supplementing data, the date + 1 | +
+  +
+
+  +
+