diff --git a/docs/docs/en/architecture/design.md b/docs/docs/en/architecture/design.md
index d2b8be211c..24776101fd 100644
--- a/docs/docs/en/architecture/design.md
+++ b/docs/docs/en/architecture/design.md
@@ -5,7 +5,7 @@
### System Architecture Diagram
-  +
+ 
System architecture diagram
@@ -14,7 +14,7 @@
### Start Process Activity Diagram
-  +
+ 
Start process activity diagram
@@ -29,14 +29,20 @@
MasterServer provides monitoring services based on netty.
#### The Service Mainly Includes:
+
+ - **DistributedQuartz** distributed scheduling component, which is mainly responsible for the start and stop operations of scheduled tasks. When quartz start the task, there will be a thread pool inside the Master responsible for the follow-up operation of the processing task;
+
+ - **MasterSchedulerService** is a scanning thread that regularly scans the `t_ds_command` table in the database, runs different business operations according to different **command types**;
+
+ - **WorkflowExecuteRunnable** is mainly responsible for DAG task segmentation, task submission monitoring, and logical processing of different event types;
- - **Distributed Quartz** distributed scheduling component, which is mainly responsible for the start and stop operations of schedule tasks. When Quartz starts the task, there will be a thread pool inside the Master responsible for the follow-up operation of the processing task.
+ - **TaskExecuteRunnable** is mainly responsible for the processing and persistence of tasks, and generates task events and submits them to the event queue of the process instance;
- - **MasterSchedulerThread** is a scanning thread that regularly scans the **command** table in the database and runs different business operations according to different **command types**.
+ - **EventExecuteService** is mainly responsible for the polling of the event queue of the process instances;
- - **MasterExecThread** is mainly responsible for DAG task segmentation, task submission monitoring, and logical processing to different command types.
+ - **StateWheelExecuteThread** is mainly responsible for process instance and task timeout, task retry, task-dependent polling, and generates the corresponding process instance or task event and submits it to the event queue of the process instance;
- - **MasterTaskExecThread** is mainly responsible for the persistence to tasks.
+ - **FailoverExecuteThread** is mainly responsible for the logic of Master fault tolerance and Worker fault tolerance;
* **WorkerServer**
@@ -46,8 +52,12 @@
Server provides monitoring services based on netty.
#### The Service Mainly Includes:
-
- - **Fetch TaskThread** is mainly responsible for continuously getting tasks from the **Task Queue**, and calling **TaskScheduleThread** corresponding executor according to different task types.
+
+ - **WorkerManagerThread** is mainly responsible for the submission of the task queue, continuously receives tasks from the task queue, and submits them to the thread pool for processing;
+
+ - **TaskExecuteThread** is mainly responsible for the process of task execution, and the actual processing of tasks according to different task types;
+
+ - **RetryReportTaskStatusThread** is mainly responsible for regularly polling to report the task status to the Master until the Master replies to the status ack to avoid the loss of the task status;
* **ZooKeeper**
@@ -55,18 +65,13 @@
We have also implemented queues based on Redis, but we hope DolphinScheduler depends on as few components as possible, so we finally removed the Redis implementation.
-* **Task Queue**
-
- Provide task queue operation, the current queue is also implement base on ZooKeeper. Due to little information stored in the queue, there is no need to worry about excessive data in the queue. In fact, we have tested the millions of data storage in queues, which has no impact on system stability and performance.
-
-* **Alert**
+* **AlertServer**
- Provide alarm related interface, the interface mainly includes **alarm** two types of alarm data storage, query and notification functions. Among them, there are **email notification** and **SNMP (not yet implemented)**.
+ Provides alarm services, and implements rich alarm methods through alarm plugins.
* **API**
The API interface layer is mainly responsible for processing requests from the front-end UI layer. The service uniformly provides RESTful APIs to provide request services to external.
- Interfaces include workflow creation, definition, query, modification, release, logoff, manual start, stop, pause, resume, start execution from specific node, etc.
* **UI**
@@ -102,41 +107,6 @@ Problems in centralized thought design:
- In fact, truly decentralized distributed systems are rare. Instead, dynamic centralized distributed systems are constantly pouring out. Under this architecture, the managers in the cluster are dynamically selected, rather than preset, and when the cluster fails, the nodes of the cluster will automatically hold "meetings" to elect new "managers" To preside over the work. The most typical case is Etcd implemented by ZooKeeper and Go language.
- The decentralization of DolphinScheduler is that the Master and Worker register in ZooKeeper, for implement the centerless feature to Master cluster and Worker cluster. Use the ZooKeeper distributed lock to elect one of the Master or Worker as the "manager" to perform the task.
-#### Distributed Lock Practice
-
-DolphinScheduler uses ZooKeeper distributed lock to implement only one Master executes Scheduler at the same time, or only one Worker executes the submission of tasks.
-1. The following shows the core process algorithm for acquiring distributed locks:
-
- 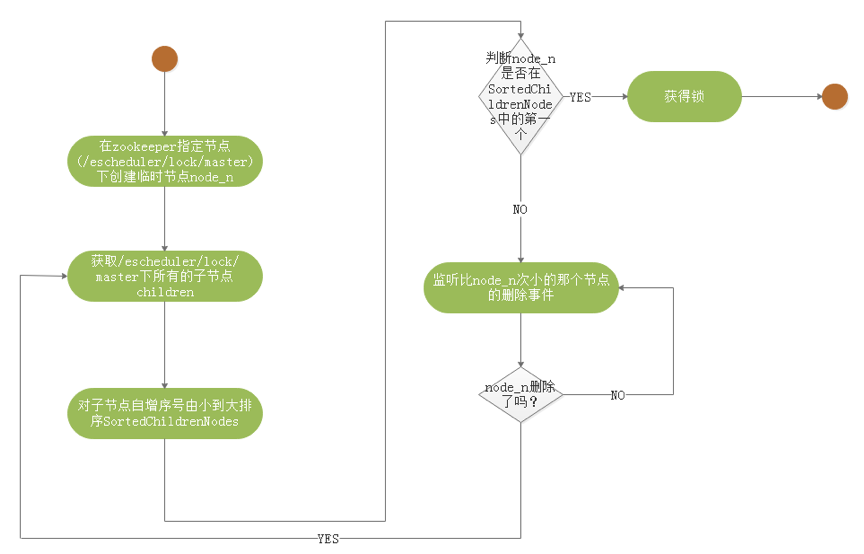 -
-
-
-2. Flow diagram of implementation of Scheduler thread distributed lock in DolphinScheduler:
-
-  -
-
-
-
-#### Insufficient Thread Loop Waiting Problem
-
-- If there is no sub-process in a DAG, when the number of data in the Command is greater than the threshold set by the thread pool, the process directly waits or fails.
-- If a large DAG nests many sub-processes, there will produce a "dead" state as the following figure:
-
-
- 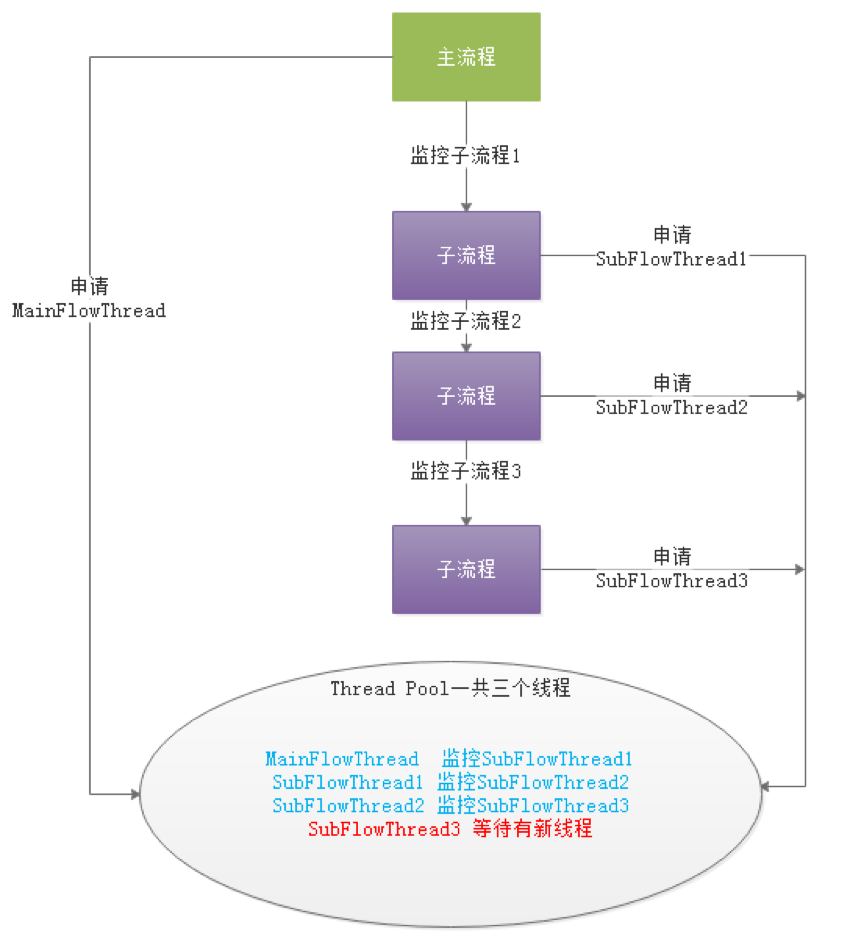 -
-
-In the above figure, MainFlowThread waits for the end of SubFlowThread1, SubFlowThread1 waits for the end of SubFlowThread2, SubFlowThread2 waits for the end of SubFlowThread3, and SubFlowThread3 waits for a new thread in the thread pool, then the entire DAG process cannot finish, and the threads cannot be released. In this situation, the state of the child-parent process loop waiting is formed. At this moment, unless a new Master is started and add threads to break such a "stalemate", the scheduling cluster will no longer use.
-
-It seems a bit unsatisfactory to start a new Master to break the deadlock, so we proposed the following three solutions to reduce this risk:
-
-1. Calculate the sum of all Master threads, and then calculate the number of threads required for each DAG, that is, pre-calculate before the DAG process executes. Because it is a multi-master thread pool, it is unlikely to obtain the total number of threads in real time.
-2. Judge whether the single-master thread pool is full, let the thread fail directly when fulfilled.
-3. Add a Command type with insufficient resources. If the thread pool is insufficient, suspend the main process. In this way, there are new threads in the thread pool, which can make the process suspended by insufficient resources wake up to execute again.
-
-Note: The Master Scheduler thread executes by FIFO when acquiring the Command.
-
-So we choose the third way to solve the problem of insufficient threads.
-
-
#### Fault-Tolerant Design
Fault tolerance divides into service downtime fault tolerance and task retry, and service downtime fault tolerance divides into master fault tolerance and worker fault tolerance.
@@ -155,7 +125,7 @@ Among them, the Master monitors the directories of other Masters and Workers. If
- Master fault tolerance:
-  +
+ 
Fault tolerance range: From the perspective of host, the fault tolerance range of Master includes: own host and node host that does not exist in the registry, and the entire process of fault tolerance will be locked;
@@ -167,7 +137,7 @@ Fault-tolerant post-processing: After the fault tolerance of ZooKeeper Master co
- Worker fault tolerance:
-  +
+ 
Fault tolerance range: From the perspective of process instance, each Master is only responsible for fault tolerance of its own process instance; it will lock only when `handleDeadServer`;
@@ -188,11 +158,11 @@ Here we must first distinguish the concepts of task failure retry, process failu
Next to the main point, we divide the task nodes in the workflow into two types.
-- One is a business node, which corresponds to an actual script or process command, such as shell node, MR node, Spark node, and dependent node.
+- One is a business task, which corresponds to an actual script or process command, such as Shell task, SQL task, and Spark task.
-- Another is a logical node, which does not operate actual script or process command, but only logical processing to the entire process flow, such as sub-process sections.
+- Another is a logical task, which does not operate actual script or process command, but only logical processing to the entire process flow, such as sub-process task, dependent task.
-Each **business node** can configure the number of failed retries. When the task node fails, it will automatically retry until it succeeds or exceeds the retry times. **Logical node** failure retry is not supported, but the tasks in the logical node support.
+**Business node** can configure the number of failed retries. When the task node fails, it will automatically retry until it succeeds or exceeds the retry times. **Logical node** failure retry is not supported.
If there is a task failure in the workflow that reaches the maximum retry times, the workflow will fail and stop, and the failed workflow can be manually re-run or process recovery operations.
@@ -225,55 +195,29 @@ In the early schedule design, if there is no priority design and use the fair sc
 -- We use the customized FileAppender and Filter functions from Logback to implement each task instance generates one log file.
-- The following is the FileAppender implementation:
-
-```java
- /**
- * task log appender
- */
- public class TaskLogAppender extends FileAppender {
-
- ...
-
- @Override
- protected void append(ILoggingEvent event) {
-
- if (currentlyActiveFile == null){
- currentlyActiveFile = getFile();
- }
- String activeFile = currentlyActiveFile;
- // thread name: taskThreadName-processDefineId_processInstanceId_taskInstanceId
- String threadName = event.getThreadName();
- String[] threadNameArr = threadName.split("-");
- // logId = processDefineId_processInstanceId_taskInstanceId
- String logId = threadNameArr[1];
- ...
- super.subAppend(event);
- }
-}
-```
-
-Generate logs in the form of /process definition id /process instance id /task instance id.log
-
-- Filter to match the thread name starting with TaskLogInfo:
-
-- The following shows the TaskLogFilter implementation:
-
- ```java
- /**
- * task log filter
- */
-public class TaskLogFilter extends Filter {
-
- @Override
- public FilterReply decide(ILoggingEvent event) {
- if (event.getThreadName().startsWith("TaskLogInfo-")){
- return FilterReply.ACCEPT;
- }
- return FilterReply.DENY;
- }
-}
+- For details, please refer to the logback configuration of Master and Worker, as shown in the following example:
+
+```xml
+
+
+
+
+ taskAppId
+ ${log.base}
+
+
+
+ ${log.base}/${taskAppId}.log
+
+
+ [%level] %date{yyyy-MM-dd HH:mm:ss.SSS Z} [%thread] %logger{96}:[%line] - %messsage%n
+
+ UTF-8
+
+ true
+
+
+
```
## Sum Up
diff --git a/docs/docs/en/architecture/metadata.md b/docs/docs/en/architecture/metadata.md
index 54ebc56fbf..2e55e1d925 100644
--- a/docs/docs/en/architecture/metadata.md
+++ b/docs/docs/en/architecture/metadata.md
@@ -1,33 +1,7 @@
# MetaData
-## DolphinScheduler DB Table Overview
-
-| Table Name | Comment |
-| :---: | :---: |
-| t_ds_access_token | token for access DolphinScheduler backend |
-| t_ds_alert | alert detail |
-| t_ds_alertgroup | alert group |
-| t_ds_command | command detail |
-| t_ds_datasource | data source |
-| t_ds_error_command | error command detail |
-| t_ds_process_definition | process definition |
-| t_ds_process_instance | process instance |
-| t_ds_project | project |
-| t_ds_queue | queue |
-| t_ds_relation_datasource_user | datasource related to user |
-| t_ds_relation_process_instance | sub process |
-| t_ds_relation_project_user | project related to user |
-| t_ds_relation_resources_user | resource related to user |
-| t_ds_relation_udfs_user | UDF functions related to user |
-| t_ds_relation_user_alertgroup | alert group related to user |
-| t_ds_resources | resoruce center file |
-| t_ds_schedules | process definition schedule |
-| t_ds_session | user login session |
-| t_ds_task_instance | task instance |
-| t_ds_tenant | tenant |
-| t_ds_udfs | UDF resource |
-| t_ds_user | user detail |
-| t_ds_version | DolphinScheduler version |
+## Table Schema
+see sql files in `dolphinscheduler/dolphinscheduler-dao/src/main/resources/sql`
---
@@ -36,158 +10,31 @@
### User Queue DataSource
-
+
- One tenant can own Multiple users.
-- The queue field in the t_ds_user table stores the queue_name information in the t_ds_queue table, t_ds_tenant stores queue information using queue_id column. During the execution of the process definition, the user queue has the highest priority. If the user queue is null, use the tenant queue.
-- The user_id field in the t_ds_datasource table shows the user who create the data source. The user_id in t_ds_relation_datasource_user shows the user who has permission to the data source.
+- The queue field in the `t_ds_user` table stores the `queue_name` information in the `t_ds_queue` table, `t_ds_tenant` stores queue information using `queue_id` column. During the execution of the process definition, the user queue has the highest priority. If the user queue is null, use the tenant queue.
+- The `user_id` field in the `t_ds_datasource` table shows the user who create the data source. The user_id in `t_ds_relation_datasource_user` shows the user who has permission to the data source.
### Project Resource Alert
-
-
-- User can have multiple projects, user project authorization completes the relationship binding using project_id and user_id in t_ds_relation_project_user table.
-- The user_id in the t_ds_projcet table represents the user who create the project, and the user_id in the t_ds_relation_project_user table represents users who have permission to the project.
-- The user_id in the t_ds_resources table represents the user who create the resource, and the user_id in t_ds_relation_resources_user represents the user who has permissions to the resource.
-- The user_id in the t_ds_udfs table represents the user who create the UDF, and the user_id in the t_ds_relation_udfs_user table represents a user who has permission to the UDF.
-
-### Command Process Task
-
-
-- We use the customized FileAppender and Filter functions from Logback to implement each task instance generates one log file.
-- The following is the FileAppender implementation:
-
-```java
- /**
- * task log appender
- */
- public class TaskLogAppender extends FileAppender {
-
- ...
-
- @Override
- protected void append(ILoggingEvent event) {
-
- if (currentlyActiveFile == null){
- currentlyActiveFile = getFile();
- }
- String activeFile = currentlyActiveFile;
- // thread name: taskThreadName-processDefineId_processInstanceId_taskInstanceId
- String threadName = event.getThreadName();
- String[] threadNameArr = threadName.split("-");
- // logId = processDefineId_processInstanceId_taskInstanceId
- String logId = threadNameArr[1];
- ...
- super.subAppend(event);
- }
-}
-```
-
-Generate logs in the form of /process definition id /process instance id /task instance id.log
-
-- Filter to match the thread name starting with TaskLogInfo:
-
-- The following shows the TaskLogFilter implementation:
-
- ```java
- /**
- * task log filter
- */
-public class TaskLogFilter extends Filter {
-
- @Override
- public FilterReply decide(ILoggingEvent event) {
- if (event.getThreadName().startsWith("TaskLogInfo-")){
- return FilterReply.ACCEPT;
- }
- return FilterReply.DENY;
- }
-}
+- For details, please refer to the logback configuration of Master and Worker, as shown in the following example:
+
+```xml
+
+
+
+
+ taskAppId
+ ${log.base}
+
+
+
+ ${log.base}/${taskAppId}.log
+
+
+ [%level] %date{yyyy-MM-dd HH:mm:ss.SSS Z} [%thread] %logger{96}:[%line] - %messsage%n
+
+ UTF-8
+
+ true
+
+
+
```
## Sum Up
diff --git a/docs/docs/en/architecture/metadata.md b/docs/docs/en/architecture/metadata.md
index 54ebc56fbf..2e55e1d925 100644
--- a/docs/docs/en/architecture/metadata.md
+++ b/docs/docs/en/architecture/metadata.md
@@ -1,33 +1,7 @@
# MetaData
-## DolphinScheduler DB Table Overview
-
-| Table Name | Comment |
-| :---: | :---: |
-| t_ds_access_token | token for access DolphinScheduler backend |
-| t_ds_alert | alert detail |
-| t_ds_alertgroup | alert group |
-| t_ds_command | command detail |
-| t_ds_datasource | data source |
-| t_ds_error_command | error command detail |
-| t_ds_process_definition | process definition |
-| t_ds_process_instance | process instance |
-| t_ds_project | project |
-| t_ds_queue | queue |
-| t_ds_relation_datasource_user | datasource related to user |
-| t_ds_relation_process_instance | sub process |
-| t_ds_relation_project_user | project related to user |
-| t_ds_relation_resources_user | resource related to user |
-| t_ds_relation_udfs_user | UDF functions related to user |
-| t_ds_relation_user_alertgroup | alert group related to user |
-| t_ds_resources | resoruce center file |
-| t_ds_schedules | process definition schedule |
-| t_ds_session | user login session |
-| t_ds_task_instance | task instance |
-| t_ds_tenant | tenant |
-| t_ds_udfs | UDF resource |
-| t_ds_user | user detail |
-| t_ds_version | DolphinScheduler version |
+## Table Schema
+see sql files in `dolphinscheduler/dolphinscheduler-dao/src/main/resources/sql`
---
@@ -36,158 +10,31 @@
### User Queue DataSource
-
+
- One tenant can own Multiple users.
-- The queue field in the t_ds_user table stores the queue_name information in the t_ds_queue table, t_ds_tenant stores queue information using queue_id column. During the execution of the process definition, the user queue has the highest priority. If the user queue is null, use the tenant queue.
-- The user_id field in the t_ds_datasource table shows the user who create the data source. The user_id in t_ds_relation_datasource_user shows the user who has permission to the data source.
+- The queue field in the `t_ds_user` table stores the `queue_name` information in the `t_ds_queue` table, `t_ds_tenant` stores queue information using `queue_id` column. During the execution of the process definition, the user queue has the highest priority. If the user queue is null, use the tenant queue.
+- The `user_id` field in the `t_ds_datasource` table shows the user who create the data source. The user_id in `t_ds_relation_datasource_user` shows the user who has permission to the data source.
### Project Resource Alert
-
-
-- User can have multiple projects, user project authorization completes the relationship binding using project_id and user_id in t_ds_relation_project_user table.
-- The user_id in the t_ds_projcet table represents the user who create the project, and the user_id in the t_ds_relation_project_user table represents users who have permission to the project.
-- The user_id in the t_ds_resources table represents the user who create the resource, and the user_id in t_ds_relation_resources_user represents the user who has permissions to the resource.
-- The user_id in the t_ds_udfs table represents the user who create the UDF, and the user_id in the t_ds_relation_udfs_user table represents a user who has permission to the UDF.
-
-### Command Process Task
-
-

-
-- A project has multiple process definitions, a process definition can generate multiple process instances, and a process instance can generate multiple task instances.
-- The t_ds_schedulers table stores the specified time schedule information for process definition.
-- The data stored in the t_ds_relation_process_instance table is used to deal with the sub-processes of a process definition, parent_process_instance_id field represents the id of the main process instance who contains child processes, process_instance_id field represents the id of the sub-process instance, parent_task_instance_id field represents the task instance id of the sub-process node.
-- The process instance table and the task instance table correspond to the t_ds_process_instance table and the t_ds_task_instance table, respectively.
-
----
-
-## Core Table Schema
-
-### t_ds_process_definition
-
-| Field | Type | Comment |
-| --- | --- | --- |
-| id | int | primary key |
-| name | varchar | process definition name |
-| version | int | process definition version |
-| release_state | tinyint | process definition release state:0:offline,1:online |
-| project_id | int | project id |
-| user_id | int | process definition creator id |
-| process_definition_json | longtext | process definition JSON content |
-| description | text | process definition description |
-| global_params | text | global parameters |
-| flag | tinyint | whether process available: 0 not available, 1 available |
-| locations | text | Node location information |
-| connects | text | Node connection information |
-| receivers | text | receivers |
-| receivers_cc | text | carbon copy list |
-| create_time | datetime | create time |
-| timeout | int | timeout |
-| tenant_id | int | tenant id |
-| update_time | datetime | update time |
-| modify_by | varchar | define user modify the process |
-| resource_ids | varchar | resource id set |
-
-### t_ds_process_instance
-
-| Field | Type | Comment |
-| --- | --- | --- |
-| id | int | primary key |
-| name | varchar | process instance name |
-| process_definition_id | int | process definition id |
-| state | tinyint | process instance Status: 0 successful commit, 1 running, 2 prepare to pause, 3 pause, 4 prepare to stop, 5 stop, 6 fail, 7 succeed, 8 need fault tolerance, 9 kill, 10 wait for thread, 11 wait for dependency to complete |
-| recovery | tinyint | process instance failover flag:0: normal,1: failover instance needs restart |
-| start_time | datetime | process instance start time |
-| end_time | datetime | process instance end time |
-| run_times | int | process instance run times |
-| host | varchar | process instance host |
-| command_type | tinyint | command type:0 start ,1 start from the current node,2 resume a fault-tolerant process,3 resume from pause process, 4 execute from the failed node,5 complement, 6 dispatch, 7 re-run, 8 pause, 9 stop, 10 resume waiting thread |
-| command_param | text | JSON command parameters |
-| task_depend_type | tinyint | node dependency type: 0 current node, 1 forward, 2 backward |
-| max_try_times | tinyint | max try times |
-| failure_strategy | tinyint | failure strategy, 0: end the process when node failed,1: continue run the other nodes when failed |
-| warning_type | tinyint | warning type 0: no warning, 1: warning if process success, 2: warning if process failed, 3: warning whatever results |
-| warning_group_id | int | warning group id |
-| schedule_time | datetime | schedule time |
-| command_start_time | datetime | command start time |
-| global_params | text | global parameters |
-| process_instance_json | longtext | process instance JSON |
-| flag | tinyint | whether process instance is available: 0 not available, 1 available |
-| update_time | timestamp | update time |
-| is_sub_process | int | whether the process is sub process: 1 sub-process, 0 not sub-process |
-| executor_id | int | executor id |
-| locations | text | node location information |
-| connects | text | node connection information |
-| history_cmd | text | history commands, record all the commands to a instance |
-| dependence_schedule_times | text | depend schedule estimate time |
-| process_instance_priority | int | process instance priority. 0 highest,1 high,2 medium,3 low,4 lowest |
-| worker_group | varchar | worker group who assign the task |
-| timeout | int | timeout |
-| tenant_id | int | tenant id |
-
-### t_ds_task_instance
+
-| Field | Type | Comment |
-| --- | --- | --- |
-| id | int | primary key |
-| name | varchar | task name |
-| task_type | varchar | task type |
-| process_definition_id | int | process definition id |
-| process_instance_id | int | process instance id |
-| task_json | longtext | task content JSON |
-| state | tinyint | Status: 0 commit succeeded, 1 running, 2 prepare to pause, 3 pause, 4 prepare to stop, 5 stop, 6 fail, 7 succeed, 8 need fault tolerance, 9 kill, 10 wait for thread, 11 wait for dependency to complete |
-| submit_time | datetime | task submit time |
-| start_time | datetime | task start time |
-| end_time | datetime | task end time |
-| host | varchar | host of task running on |
-| execute_path | varchar | task execute path in the host |
-| log_path | varchar | task log path |
-| alert_flag | tinyint | whether alert |
-| retry_times | int | task retry times |
-| pid | int | pid of task |
-| app_link | varchar | Yarn app id |
-| flag | tinyint | task instance is available : 0 not available, 1 available |
-| retry_interval | int | retry interval when task failed |
-| max_retry_times | int | max retry times |
-| task_instance_priority | int | task instance priority:0 highest,1 high,2 medium,3 low,4 lowest |
-| worker_group | varchar | worker group who assign the task |
+- User can have multiple projects, user project authorization completes the relationship binding using `project_id` and `user_id` in `t_ds_relation_project_user` table.
+- The `user_id` in the `t_ds_projcet` table represents the user who create the project, and the `user_id` in the `t_ds_relation_project_user` table represents users who have permission to the project.
+- The `user_id` in the `t_ds_resources` table represents the user who create the resource, and the `user_id` in `t_ds_relation_resources_user` represents the user who has permissions to the resource.
+- The `user_id` in the `t_ds_udfs` table represents the user who create the UDF, and the `user_id` in the `t_ds_relation_udfs_user` table represents a user who has permission to the UDF.
-#### t_ds_schedules
+### Project - Tenant - ProcessDefinition - Schedule
+
-| Field | Type | Comment |
-| --- | --- | --- |
-| id | int | primary key |
-| process_definition_id | int | process definition id |
-| start_time | datetime | schedule start time |
-| end_time | datetime | schedule end time |
-| crontab | varchar | crontab expression |
-| failure_strategy | tinyint | failure strategy: 0 end,1 continue |
-| user_id | int | user id |
-| release_state | tinyint | release status: 0 not yet released,1 released |
-| warning_type | tinyint | warning type: 0: no warning, 1: warning if process success, 2: warning if process failed, 3: warning whatever results |
-| warning_group_id | int | warning group id |
-| process_instance_priority | int | process instance priority:0 highest,1 high,2 medium,3 low,4 lowest |
-| worker_group | varchar | worker group who assign the task |
-| create_time | datetime | create time |
-| update_time | datetime | update time |
+- A project can have multiple process definitions, and each process definition belongs to only one project.
+- A tenant can be used by multiple process definitions, and each process definition must select only one tenant.
+- A workflow definition can have one or more schedules.
-### t_ds_command
+### Process Definition Execution
+
-| Field | Type | Comment |
-| --- | --- | --- |
-| id | int | primary key |
-| command_type | tinyint | command type: 0 start workflow, 1 start execution from current node, 2 resume fault-tolerant workflow, 3 resume pause process, 4 start execution from failed node, 5 complement, 6 schedule, 7 re-run, 8 pause, 9 stop, 10 resume waiting thread |
-| process_definition_id | int | process definition id |
-| command_param | text | JSON command parameters |
-| task_depend_type | tinyint | node dependency type: 0 current node, 1 forward, 2 backward |
-| failure_strategy | tinyint | failed policy: 0 end, 1 continue |
-| warning_type | tinyint | alarm type: 0 no alarm, 1 alarm if process success, 2: alarm if process failed, 3: warning whatever results |
-| warning_group_id | int | warning group id |
-| schedule_time | datetime | schedule time |
-| start_time | datetime | start time |
-| executor_id | int | executor id |
-| dependence | varchar | dependence column |
-| update_time | datetime | update time |
-| process_instance_priority | int | process instance priority: 0 highest,1 high,2 medium,3 low,4 lowest |
-| worker_group_id | int | worker group who assign the task |
\ No newline at end of file
+- A process definition corresponds to multiple task definitions, which are associated through `t_ds_process_task_relation` and the associated key is `code + version`. When the pre-task of the task is empty, the corresponding `pre_task_node` and `pre_task_version` are 0.
+- A process definition can have multiple process instances `t_ds_process_instance`, one process instance corresponds to one or more task instances `t_ds_task_instance`.
+- The data stored in the `t_ds_relation_process_instance` table is used to handle the case that the process definition contains sub-processes. `parent_process_instance_id` represents the id of the main process instance containing the sub-process, `process_instance_id` represents the id of the sub-process instance, `parent_task_instance_id` represents the task instance id of the sub-process node. The process instance table and the task instance table correspond to the `t_ds_process_instance` table and the `t_ds_task_instance` table, respectively.
\ No newline at end of file
diff --git a/docs/docs/zh/architecture/design.md b/docs/docs/zh/architecture/design.md
index a2183b0664..6e8a6f35fc 100644
--- a/docs/docs/zh/architecture/design.md
+++ b/docs/docs/zh/architecture/design.md
@@ -1,24 +1,24 @@
-## 系统架构设计
+# 系统架构设计
-### 2.系统架构
+## 系统架构
-#### 2.1 系统架构图
+### 系统架构图
-
+
系统架构图
-#### 2.2 启动流程活动图
+### 启动流程活动图
-
+
启动流程活动图
-#### 2.3 架构说明
+### 架构说明
* **MasterServer**
@@ -28,49 +28,55 @@
##### 该服务内主要包含:
- - **Distributed Quartz**分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作
+ - **DistributedQuartz**分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作;
- - **MasterSchedulerThread**是一个扫描线程,定时扫描数据库中的 **command** 表,根据不同的**命令类型**进行不同的业务操作
+ - **MasterSchedulerService**是一个扫描线程,定时扫描数据库中的`t_ds_command`表,根据不同的命令类型进行不同的业务操作;
- - **MasterExecThread**主要是负责DAG任务切分、任务提交监控、各种不同命令类型的逻辑处理
+ - **WorkflowExecuteRunnable**主要是负责DAG任务切分、任务提交监控、各种不同事件类型的逻辑处理;
- - **MasterTaskExecThread**主要负责任务的持久化
+ - **TaskExecuteRunnable**主要负责任务的处理和持久化,并生成任务事件提交到工作流的事件队列;
+ - **EventExecuteService**主要负责工作流实例的事件队列的轮询;
+
+ - **StateWheelExecuteThread**主要负责工作流和任务超时、任务重试、任务依赖的轮询,并生成对应的工作流或任务事件提交到工作流的事件队列;
+
+ - **FailoverExecuteThread**主要负责Master容错和Worker容错的相关逻辑;
+
* **WorkerServer**
WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。
WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。
- Server基于netty提供监听服务。Worker
+ Server基于netty提供监听服务。
##### 该服务包含:
- - **FetchTaskThread**主要负责不断从**Task Queue**中领取任务,并根据不同任务类型调用**TaskScheduleThread**对应执行器。
+
+ - **WorkerManagerThread**主要负责任务队列的提交,不断从任务队列中领取任务,提交到线程池处理;
+
+ - **TaskExecuteThread**主要负责任务执行的流程,根据不同的任务类型进行任务的实际处理;
+
+ - **RetryReportTaskStatusThread**主要负责定时轮询向Master汇报任务的状态,直到Master回复状态的ack,避免任务状态丢失;
* **ZooKeeper**
ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。
我们也曾经基于Redis实现过队列,不过我们希望DolphinScheduler依赖到的组件尽量地少,所以最后还是去掉了Redis实现。
-* **Task Queue**
-
- 提供任务队列的操作,目前队列也是基于Zookeeper来实现。由于队列中存的信息较少,不必担心队列里数据过多的情况,实际上我们压测过百万级数据存队列,对系统稳定性和性能没影响。
+* **AlertServer**
-* **Alert**
+ 提供告警服务,通过告警插件的方式实现丰富的告警手段。
- 提供告警相关接口,接口主要包括**告警**两种类型的告警数据的存储、查询和通知功能。其中通知功能又有**邮件通知**和**SNMP(暂未实现)**两种。
-
-* **API**
+* **ApiServer**
API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。
- 接口包括工作流的创建、定义、查询、修改、发布、下线、手工启动、停止、暂停、恢复、从该节点开始执行等等。
* **UI**
系统的前端页面,提供系统的各种可视化操作界面。
-#### 2.3 架构设计思想
+### 架构设计思想
-##### 一、去中心化vs中心化
+#### 一、去中心化vs中心化
-###### 中心化思想
+##### 中心化思想
中心化的设计理念比较简单,分布式集群中的节点按照角色分工,大体上分为两种角色:
@@ -87,9 +93,7 @@
- 一旦Master出现了问题,则群龙无首,整个集群就会崩溃。为了解决这个问题,大多数Master/Slave架构模式都采用了主备Master的设计方案,可以是热备或者冷备,也可以是自动切换或手动切换,而且越来越多的新系统都开始具备自动选举切换Master的能力,以提升系统的可用性。
- 另外一个问题是如果Scheduler在Master上,虽然可以支持一个DAG中不同的任务运行在不同的机器上,但是会产生Master的过负载。如果Scheduler在Slave上,则一个DAG中所有的任务都只能在某一台机器上进行作业提交,则并行任务比较多的时候,Slave的压力可能会比较大。
-
-
-###### 去中心化
+##### 去中心化
@@ -98,49 +102,12 @@
- 去中心化设计的核心设计在于整个分布式系统中不存在一个区别于其他节点的”管理者”,因此不存在单点故障问题。但由于不存在” 管理者”节点所以每个节点都需要跟其他节点通信才得到必须要的机器信息,而分布式系统通信的不可靠性,则大大增加了上述功能的实现难度。
- 实际上,真正去中心化的分布式系统并不多见。反而动态中心化分布式系统正在不断涌出。在这种架构下,集群中的管理者是被动态选择出来的,而不是预置的,并且集群在发生故障的时候,集群的节点会自发的举行"会议"来选举新的"管理者"去主持工作。最典型的案例就是ZooKeeper及Go语言实现的Etcd。
+- DolphinScheduler的去中心化是Master/Worker注册心跳到Zookeeper中,Master基于slot处理各自的Command,通过selector分发任务给worker,实现Master集群和Worker集群无中心。
-
-- DolphinScheduler的去中心化是Master/Worker注册到Zookeeper中,实现Master集群和Worker集群无中心,并使用Zookeeper分布式锁来选举其中的一台Master或Worker为“管理者”来执行任务。
-
-##### 二、分布式锁实践
-
-DolphinScheduler使用ZooKeeper分布式锁来实现同一时刻只有一台Master执行Scheduler,或者只有一台Worker执行任务的提交。
-1. 获取分布式锁的核心流程算法如下
-
-
-
-
-2. DolphinScheduler中Scheduler线程分布式锁实现流程图:
-
-
-
-
-
-##### 三、线程不足循环等待问题
-
-- 如果一个DAG中没有子流程,则如果Command中的数据条数大于线程池设置的阈值,则直接流程等待或失败。
-- 如果一个大的DAG中嵌套了很多子流程,如下图则会产生“死等”状态:
-
-
-
-
-上图中MainFlowThread等待SubFlowThread1结束,SubFlowThread1等待SubFlowThread2结束, SubFlowThread2等待SubFlowThread3结束,而SubFlowThread3等待线程池有新线程,则整个DAG流程不能结束,从而其中的线程也不能释放。这样就形成的子父流程循环等待的状态。此时除非启动新的Master来增加线程来打破这样的”僵局”,否则调度集群将不能再使用。
-
-对于启动新Master来打破僵局,似乎有点差强人意,于是我们提出了以下三种方案来降低这种风险:
-
-1. 计算所有Master的线程总和,然后对每一个DAG需要计算其需要的线程数,也就是在DAG流程执行之前做预计算。因为是多Master线程池,所以总线程数不太可能实时获取。
-2. 对单Master线程池进行判断,如果线程池已经满了,则让线程直接失败。
-3. 增加一种资源不足的Command类型,如果线程池不足,则将主流程挂起。这样线程池就有了新的线程,可以让资源不足挂起的流程重新唤醒执行。
-
-注意:Master Scheduler线程在获取Command的时候是FIFO的方式执行的。
-
-于是我们选择了第三种方式来解决线程不足的问题。
-
-
-##### 四、容错设计
+#### 二、容错设计
容错分为服务宕机容错和任务重试,服务宕机容错又分为Master容错和Worker容错两种情况
-###### 1. 宕机容错
+##### 宕机容错
服务容错设计依赖于ZooKeeper的Watcher机制,实现原理如图:
@@ -152,7 +119,7 @@ DolphinScheduler使用ZooKeeper分布式锁来实现同一时刻只有一台Mast
- Master容错流程:
-
+
容错范围:从host的维度来看,Master的容错范围包括:自身host+注册中心上不存在的节点host,容错的整个过程会加锁;
@@ -161,12 +128,10 @@ DolphinScheduler使用ZooKeeper分布式锁来实现同一时刻只有一台Mast
容错后处理:ZooKeeper Master容错完成之后则重新由DolphinScheduler中Scheduler线程调度,遍历 DAG 找到”正在运行”和“提交成功”的任务,对”正在运行”的任务监控其任务实例的状态,对”提交成功”的任务需要判断Task Queue中是否已经存在,如果存在则同样监控任务实例的状态,如果不存在则重新提交任务实例。
-
-
- Worker容错流程:
-
+
容错范围:从工作流实例的维度看,每个Master只负责容错自己的工作流实例;只有在`handleDeadServer`时会加锁;
@@ -177,7 +142,7 @@ DolphinScheduler使用ZooKeeper分布式锁来实现同一时刻只有一台Mast
注意:由于” 网络抖动”可能会使得节点短时间内失去和ZooKeeper的心跳,从而发生节点的remove事件。对于这种情况,我们使用最简单的方式,那就是节点一旦和ZooKeeper发生超时连接,则直接将Master或Worker服务停掉。
-###### 2.任务失败重试
+##### 三、任务失败重试
这里首先要区分任务失败重试、流程失败恢复、流程失败重跑的概念:
@@ -185,21 +150,18 @@ DolphinScheduler使用ZooKeeper分布式锁来实现同一时刻只有一台Mast
- 流程失败恢复是流程级别的,是手动进行的,恢复是从只能**从失败的节点开始执行**或**从当前节点开始执行**
- 流程失败重跑也是流程级别的,是手动进行的,重跑是从开始节点进行
-
-
接下来说正题,我们将工作流中的任务节点分了两种类型。
-- 一种是业务节点,这种节点都对应一个实际的脚本或者处理语句,比如Shell节点,MR节点、Spark节点、依赖节点等。
-
-- 还有一种是逻辑节点,这种节点不做实际的脚本或语句处理,只是整个流程流转的逻辑处理,比如子流程节等。
+- 一种是业务节点,这种节点都对应一个实际的脚本或者处理语句,比如Shell节点、SQL节点、Spark节点等。
-每一个**业务节点**都可以配置失败重试的次数,当该任务节点失败,会自动重试,直到成功或者超过配置的重试次数。**逻辑节点**不支持失败重试。但是逻辑节点里的任务支持重试。
+- 还有一种是逻辑节点,这种节点不做实际的脚本或语句处理,只是整个流程流转的逻辑处理,比如依赖节点、子流程节点等。
-如果工作流中有任务失败达到最大重试次数,工作流就会失败停止,失败的工作流可以手动进行重跑操作或者流程恢复操作
+**业务节点**都可以配置失败重试的次数,当该任务节点失败,会自动重试,直到成功或者超过配置的重试次数。**逻辑节点**不支持失败重试。
+如果工作流中有任务失败达到最大重试次数,工作流就会失败停止,失败的工作流可以手动进行重跑操作或者流程恢复操作。
-##### 五、任务优先级设计
+#### 四、任务优先级设计
在早期调度设计中,如果没有优先级设计,采用公平调度设计的话,会遇到先行提交的任务可能会和后继提交的任务同时完成的情况,而不能做到设置流程或者任务的优先级,因此我们对此进行了重新设计,目前我们设计如下:
- 按照**不同流程实例优先级**优先于**同一个流程实例优先级**优先于**同一流程内任务优先级**优先于**同一流程内任务**提交顺序依次从高到低进行任务处理。
@@ -216,7 +178,7 @@ DolphinScheduler使用ZooKeeper分布式锁来实现同一时刻只有一台Mast
-##### 六、Logback和netty实现日志访问
+#### 五、Logback和netty实现日志访问
- 由于Web(UI)和Worker不一定在同一台机器上,所以查看日志不能像查询本地文件那样。有两种方案:
- 将日志放到ES搜索引擎上
@@ -229,59 +191,32 @@ DolphinScheduler使用ZooKeeper分布式锁来实现同一时刻只有一台Mast
-- 我们使用自定义Logback的FileAppender和Filter功能,实现每个任务实例生成一个日志文件。
-- FileAppender主要实现如下:
-
- ```java
- /**
- * task log appender
- */
- public class TaskLogAppender extends FileAppender {
-
- ...
-
- @Override
- protected void append(ILoggingEvent event) {
-
- if (currentlyActiveFile == null){
- currentlyActiveFile = getFile();
- }
- String activeFile = currentlyActiveFile;
- // thread name: taskThreadName-processDefineId_processInstanceId_taskInstanceId
- String threadName = event.getThreadName();
- String[] threadNameArr = threadName.split("-");
- // logId = processDefineId_processInstanceId_taskInstanceId
- String logId = threadNameArr[1];
- ...
- super.subAppend(event);
- }
-}
- ```
-
-
-以/流程定义id/流程实例id/任务实例id.log的形式生成日志
-
-- 过滤匹配以TaskLogInfo开始的线程名称:
-
-- TaskLogFilter实现如下:
-
- ```java
- /**
- * task log filter
- */
-public class TaskLogFilter extends Filter {
-
- @Override
- public FilterReply decide(ILoggingEvent event) {
- if (event.getThreadName().startsWith("TaskLogInfo-")){
- return FilterReply.ACCEPT;
- }
- return FilterReply.DENY;
- }
-}
- ```
-
-### 总结
+- 详情可参考Master和Worker的logback配置,如下示例:
+
+```xml
+
+
+
+
+ taskAppId
+ ${log.base}
+
+
+
+ ${log.base}/${taskAppId}.log
+
+
+ [%level] %date{yyyy-MM-dd HH:mm:ss.SSS Z} [%thread] %logger{96}:[%line] - %messsage%n
+
+ UTF-8
+
+ true
+
+
+
+```
+
+## 总结
本文从调度出发,初步介绍了大数据分布式工作流调度系统--DolphinScheduler的架构原理及实现思路。未完待续
diff --git a/docs/docs/zh/architecture/metadata.md b/docs/docs/zh/architecture/metadata.md
index e298b4813e..010ef7189f 100644
--- a/docs/docs/zh/architecture/metadata.md
+++ b/docs/docs/zh/architecture/metadata.md
@@ -1,185 +1,37 @@
-# Dolphin Scheduler 1.3元数据文档
+# DolphinScheduler 元数据文档
-
-### 表概览
-| 表名 | 表信息 |
-| :---: | :---: |
-| t_ds_access_token | 访问ds后端的token |
-| t_ds_alert | 告警信息 |
-| t_ds_alertgroup | 告警组 |
-| t_ds_command | 执行命令 |
-| t_ds_datasource | 数据源 |
-| t_ds_error_command | 错误命令 |
-| t_ds_process_definition | 流程定义 |
-| t_ds_process_instance | 流程实例 |
-| t_ds_project | 项目 |
-| t_ds_queue | 队列 |
-| t_ds_relation_datasource_user | 用户关联数据源 |
-| t_ds_relation_process_instance | 子流程 |
-| t_ds_relation_project_user | 用户关联项目 |
-| t_ds_relation_resources_user | 用户关联资源 |
-| t_ds_relation_udfs_user | 用户关联UDF函数 |
-| t_ds_relation_user_alertgroup | 用户关联告警组 |
-| t_ds_resources | 资源文件 |
-| t_ds_schedules | 流程定时调度 |
-| t_ds_session | 用户登录的session |
-| t_ds_task_instance | 任务实例 |
-| t_ds_tenant | 租户 |
-| t_ds_udfs | UDF资源 |
-| t_ds_user | 用户 |
-| t_ds_version | ds版本信息 |
+## 表Schema
+详见`dolphinscheduler/dolphinscheduler-dao/src/main/resources/sql`目录下的sql文件
-
-### 用户 队列 数据源
-
+## E-R图
-- 一个租户下可以有多个用户
-- t_ds_user中的queue字段存储的是队列表中的queue_name信息,t_ds_tenant下存的是queue_id,在流程定义执行过程中,用户队列优先级最高,用户队列为空则采用租户队列
-- t_ds_datasource表中的user_id字段表示创建该数据源的用户,t_ds_relation_datasource_user中的user_id表示,对数据源有权限的用户
-
-### 项目 资源 告警
-
+### 用户 队列 数据源
+
-- 一个用户可以有多个项目,用户项目授权通过t_ds_relation_project_user表完成project_id和user_id的关系绑定
-- t_ds_projcet表中的user_id表示创建该项目的用户,t_ds_relation_project_user表中的user_id表示对项目有权限的用户
-- t_ds_resources表中的user_id表示创建该资源的用户,t_ds_relation_resources_user中的user_id表示对资源有权限的用户
-- t_ds_udfs表中的user_id表示创建该UDF的用户,t_ds_relation_udfs_user表中的user_id表示对UDF有权限的用户
-
-### 命令 流程 任务
-

+- 一个租户下可以有多个用户;
+- `t_ds_user`中的queue字段存储的是队列表中的`queue_name`信息,`t_ds_tenant`下存的是`queue_id`,在流程定义执行过程中,用户队列优先级最高,用户队列为空则采用租户队列;
+- `t_ds_datasource`表中的`user_id`字段表示创建该数据源的用户,`t_ds_relation_datasource_user`中的`user_id`表示对数据源有权限的用户;
-- 一个项目有多个流程定义,一个流程定义可以生成多个流程实例,一个流程实例可以生成多个任务实例
-- t_ds_schedulers表存放流程定义的定时调度信息
-- t_ds_relation_process_instance表存放的数据用于处理流程定义中含有子流程的情况,parent_process_instance_id表示含有子流程的主流程实例id,process_instance_id表示子流程实例的id,parent_task_instance_id表示子流程节点的任务实例id,流程实例表和任务实例表分别对应t_ds_process_instance表和t_ds_task_instance表
-
-### 核心表Schema
-
-#### t_ds_process_definition
-| 字段 | 类型 | 注释 |
-| --- | --- | --- |
-| id | int | 主键 |
-| name | varchar | 流程定义名称 |
-| version | int | 流程定义版本 |
-| release_state | tinyint | 流程定义的发布状态:0 未上线 1已上线 |
-| project_id | int | 项目id |
-| user_id | int | 流程定义所属用户id |
-| process_definition_json | longtext | 流程定义json串 |
-| description | text | 流程定义描述 |
-| global_params | text | 全局参数 |
-| flag | tinyint | 流程是否可用:0 不可用,1 可用 |
-| locations | text | 节点坐标信息 |
-| connects | text | 节点连线信息 |
-| receivers | text | 收件人 |
-| receivers_cc | text | 抄送人 |
-| create_time | datetime | 创建时间 |
-| timeout | int | 超时时间 |
-| tenant_id | int | 租户id |
-| update_time | datetime | 更新时间 |
-| modify_by | varchar | 修改用户 |
-| resource_ids | varchar | 资源id集 |
+### 项目 资源 告警
+
-
-#### t_ds_process_instance
-| 字段 | 类型 | 注释 |
-| --- | --- | --- |
-| id | int | 主键 |
-| name | varchar | 流程实例名称 |
-| process_definition_id | int | 流程定义id |
-| state | tinyint | 流程实例状态:0 提交成功,1 正在运行,2 准备暂停,3 暂停,4 准备停止,5 停止,6 失败,7 成功,8 需要容错,9 kill,10 等待线程,11 等待依赖完成 |
-| recovery | tinyint | 流程实例容错标识:0 正常,1 需要被容错重启 |
-| start_time | datetime | 流程实例开始时间 |
-| end_time | datetime | 流程实例结束时间 |
-| run_times | int | 流程实例运行次数 |
-| host | varchar | 流程实例所在的机器 |
-| command_type | tinyint | 命令类型:0 启动工作流,1 从当前节点开始执行,2 恢复被容错的工作流,3 恢复暂停流程,4 从失败节点开始执行,5 补数,6 调度,7 重跑,8 暂停,9 停止,10 恢复等待线程 |
-| command_param | text | 命令的参数(json格式) |
-| task_depend_type | tinyint | 节点依赖类型:0 当前节点,1 向前执行,2 向后执行 |
-| max_try_times | tinyint | 最大重试次数 |
-| failure_strategy | tinyint | 失败策略 0 失败后结束,1 失败后继续 |
-| warning_type | tinyint | 告警类型:0 不发,1 流程成功发,2 流程失败发,3 成功失败都发 |
-| warning_group_id | int | 告警组id |
-| schedule_time | datetime | 预期运行时间 |
-| command_start_time | datetime | 开始命令时间 |
-| global_params | text | 全局参数(固化流程定义的参数) |
-| process_instance_json | longtext | 流程实例json(copy的流程定义的json) |
-| flag | tinyint | 是否可用,1 可用,0不可用 |
-| update_time | timestamp | 更新时间 |
-| is_sub_process | int | 是否是子工作流 1 是,0 不是 |
-| executor_id | int | 命令执行用户 |
-| locations | text | 节点坐标信息 |
-| connects | text | 节点连线信息 |
-| history_cmd | text | 历史命令,记录所有对流程实例的操作 |
-| dependence_schedule_times | text | 依赖节点的预估时间 |
-| process_instance_priority | int | 流程实例优先级:0 Highest,1 High,2 Medium,3 Low,4 Lowest |
-| worker_group | varchar | 任务指定运行的worker分组 |
-| timeout | int | 超时时间 |
-| tenant_id | int | 租户id |
+- 一个用户可以有多个项目,用户项目授权通过`t_ds_relation_project_user`表完成project_id和user_id的关系绑定;
+- `t_ds_projcet`表中的`user_id`表示创建该项目的用户,`t_ds_relation_project_user`表中的`user_id`表示对项目有权限的用户;
+- `t_ds_resources`表中的`user_id`表示创建该资源的用户,`t_ds_relation_resources_user`中的`user_id`表示对资源有权限的用户;
+- `t_ds_udfs`表中的`user_id`表示创建该UDF的用户,`t_ds_relation_udfs_user`表中的`user_id`表示对UDF有权限的用户;
-
-#### t_ds_task_instance
-| 字段 | 类型 | 注释 |
-| --- | --- | --- |
-| id | int | 主键 |
-| name | varchar | 任务名称 |
-| task_type | varchar | 任务类型 |
-| process_definition_id | int | 流程定义id |
-| process_instance_id | int | 流程实例id |
-| task_json | longtext | 任务节点json |
-| state | tinyint | 任务实例状态:0 提交成功,1 正在运行,2 准备暂停,3 暂停,4 准备停止,5 停止,6 失败,7 成功,8 需要容错,9 kill,10 等待线程,11 等待依赖完成 |
-| submit_time | datetime | 任务提交时间 |
-| start_time | datetime | 任务开始时间 |
-| end_time | datetime | 任务结束时间 |
-| host | varchar | 执行任务的机器 |
-| execute_path | varchar | 任务执行路径 |
-| log_path | varchar | 任务日志路径 |
-| alert_flag | tinyint | 是否告警 |
-| retry_times | int | 重试次数 |
-| pid | int | 进程pid |
-| app_link | varchar | yarn app id |
-| flag | tinyint | 是否可用:0 不可用,1 可用 |
-| retry_interval | int | 重试间隔 |
-| max_retry_times | int | 最大重试次数 |
-| task_instance_priority | int | 任务实例优先级:0 Highest,1 High,2 Medium,3 Low,4 Lowest |
-| worker_group | varchar | 任务指定运行的worker分组 |
+### 项目 - 租户 - 工作流定义 - 定时
+
-
-#### t_ds_schedules
-| 字段 | 类型 | 注释 |
-| --- | --- | --- |
-| id | int | 主键 |
-| process_definition_id | int | 流程定义id |
-| start_time | datetime | 调度开始时间 |
-| end_time | datetime | 调度结束时间 |
-| crontab | varchar | crontab 表达式 |
-| failure_strategy | tinyint | 失败策略: 0 结束,1 继续 |
-| user_id | int | 用户id |
-| release_state | tinyint | 状态:0 未上线,1 上线 |
-| warning_type | tinyint | 告警类型:0 不发,1 流程成功发,2 流程失败发,3 成功失败都发 |
-| warning_group_id | int | 告警组id |
-| process_instance_priority | int | 流程实例优先级:0 Highest,1 High,2 Medium,3 Low,4 Lowest |
-| worker_group | varchar | 任务指定运行的worker分组 |
-| create_time | datetime | 创建时间 |
-| update_time | datetime | 更新时间 |
+- 一个项目可以有多个工作流定义,每个工作流定义只属于一个项目;
+- 一个租户可以被多个工作流定义使用,每个工作流定义必须且只能选择一个租户;
+- 一个工作流定义可以有一个或多个定时的配置;
-
-#### t_ds_command
-| 字段 | 类型 | 注释 |
-| --- | --- | --- |
-| id | int | 主键 |
-| command_type | tinyint | 命令类型:0 启动工作流,1 从当前节点开始执行,2 恢复被容错的工作流,3 恢复暂停流程,4 从失败节点开始执行,5 补数,6 调度,7 重跑,8 暂停,9 停止,10 恢复等待线程 |
-| process_definition_id | int | 流程定义id |
-| command_param | text | 命令的参数(json格式) |
-| task_depend_type | tinyint | 节点依赖类型:0 当前节点,1 向前执行,2 向后执行 |
-| failure_strategy | tinyint | 失败策略:0结束,1继续 |
-| warning_type | tinyint | 告警类型:0 不发,1 流程成功发,2 流程失败发,3 成功失败都发 |
-| warning_group_id | int | 告警组 |
-| schedule_time | datetime | 预期运行时间 |
-| start_time | datetime | 开始时间 |
-| executor_id | int | 执行用户id |
-| dependence | varchar | 依赖字段 |
-| update_time | datetime | 更新时间 |
-| process_instance_priority | int | 流程实例优先级:0 Highest,1 High,2 Medium,3 Low,4 Lowest |
-| worker_group | varchar | 任务指定运行的worker分组 |
+### 工作流定义和执行
+
+- 一个工作流定义对应多个任务定义,通过`t_ds_process_task_relation`进行关联,关联的key是`code + version`,当任务的前置节点为空时,对应的`pre_task_node`和`pre_task_version`为0;
+- 一个工作流定义可以有多个工作流实例`t_ds_process_instance`,一个工作流实例对应一个或多个任务实例`t_ds_task_instance`;
+- `t_ds_relation_process_instance`表存放的数据用于处理流程定义中含有子流程的情况,`parent_process_instance_id`表示含有子流程的主流程实例id,`process_instance_id`表示子流程实例的id,`parent_task_instance_id`表示子流程节点的任务实例id,流程实例表和任务实例表分别对应`t_ds_process_instance`表和`t_ds_task_instance`表;
diff --git a/docs/img/distributed_lock_procss.png b/docs/img/distributed_lock_procss.png
deleted file mode 100644
index 6745d82cd6..0000000000
Binary files a/docs/img/distributed_lock_procss.png and /dev/null differ
diff --git a/docs/img/metadata-erd/command.png b/docs/img/metadata-erd/command.png
deleted file mode 100644
index 5c286c3434..0000000000
Binary files a/docs/img/metadata-erd/command.png and /dev/null differ
diff --git a/docs/img/metadata-erd/process-task.png b/docs/img/metadata-erd/process-task.png
deleted file mode 100644
index bc69080e35..0000000000
Binary files a/docs/img/metadata-erd/process-task.png and /dev/null differ
diff --git a/docs/img/metadata-erd/process_definition.png b/docs/img/metadata-erd/process_definition.png
new file mode 100644
index 0000000000..294fbc6b4e
Binary files /dev/null and b/docs/img/metadata-erd/process_definition.png differ
diff --git a/docs/img/metadata-erd/project_tenant_process_definition_schedule.png b/docs/img/metadata-erd/project_tenant_process_definition_schedule.png
new file mode 100644
index 0000000000..367966194d
Binary files /dev/null and b/docs/img/metadata-erd/project_tenant_process_definition_schedule.png differ