diff --git a/docs/en_US/README.md b/docs/en_US/README.md
index e69de29bb2..785b5e3cfa 100644
--- a/docs/en_US/README.md
+++ b/docs/en_US/README.md
@@ -0,0 +1,96 @@
+Easy Scheduler
+============
+[](https://www.apache.org/licenses/LICENSE-2.0.html)
+[](https://github.com/analysys/EasyScheduler)
+
+> Easy Scheduler for Big Data
+
+
+[](https://starchart.cc/analysys/EasyScheduler)
+
+[](README.md)
+[](README_zh_CN.md)
+
+
+### Design features:
+
+A distributed and easy-to-expand visual DAG workflow scheduling system. Dedicated to solving the complex dependencies in data processing, making the scheduling system `out of the box` for data processing.
+Its main objectives are as follows:
+
+ - Associate the Tasks according to the dependencies of the tasks in a DAG graph, which can visualize the running state of task in real time.
+ - Support for many task types: Shell, MR, Spark, SQL (mysql, postgresql, hive, sparksql), Python, Sub_Process, Procedure, etc.
+ - Support process scheduling, dependency scheduling, manual scheduling, manual pause/stop/recovery, support for failed retry/alarm, recovery from specified nodes, Kill task, etc.
+ - Support process priority, task priority and task failover and task timeout alarm/failure
+ - Support process global parameters and node custom parameter settings
+ - Support online upload/download of resource files, management, etc. Support online file creation and editing
+ - Support task log online viewing and scrolling, online download log, etc.
+ - Implement cluster HA, decentralize Master cluster and Worker cluster through Zookeeper
+ - Support online viewing of `Master/Worker` cpu load, memory
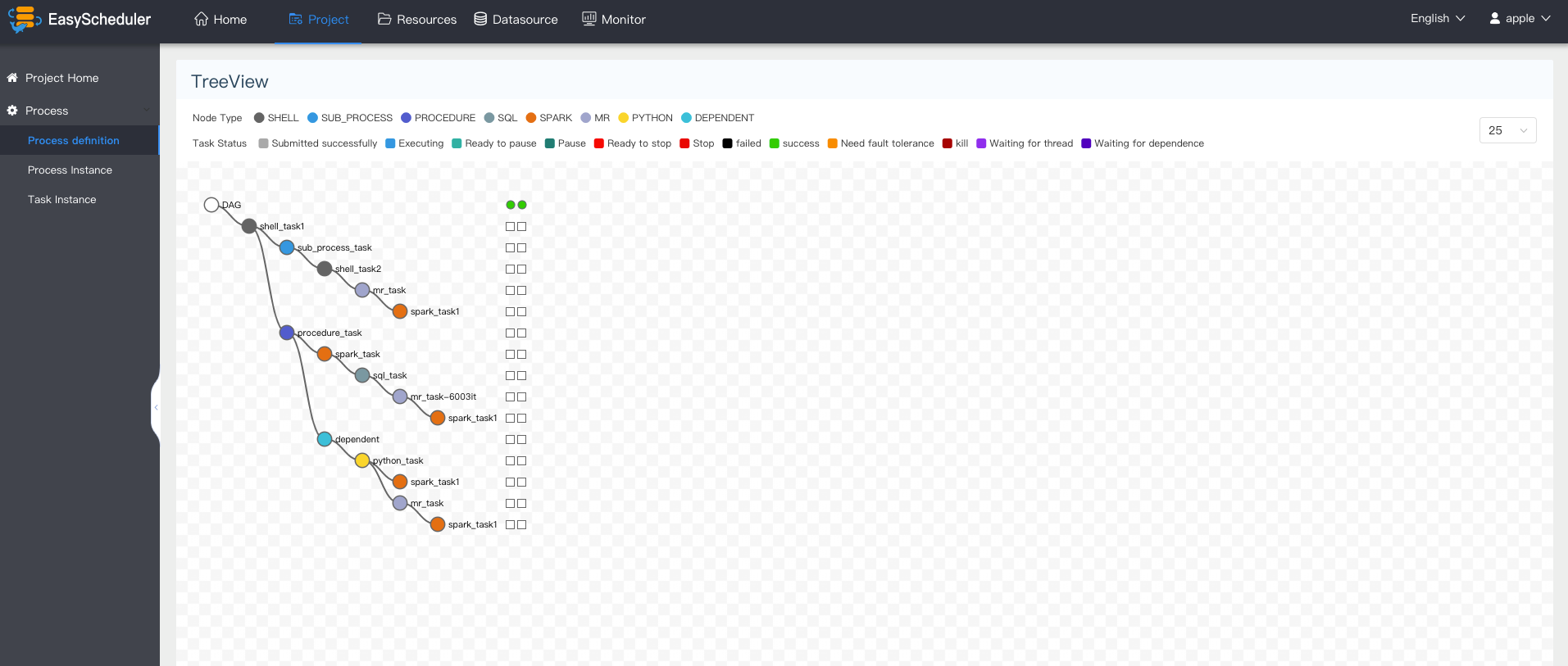
+ - Support process running history tree/gantt chart display, support task status statistics, process status statistics
+ - Support backfilling data
+ - Support multi-tenant
+ - Support internationalization
+ - There are more waiting partners to explore
+
+
+### What's in Easy Scheduler
+
+ Stability | Easy to use | Features | Scalability |
+ -- | -- | -- | --
+Decentralized multi-master and multi-worker | Visualization process defines key information such as task status, task type, retry times, task running machine, visual variables and so on at a glance. | Support pause, recover operation | support custom task types
+HA is supported by itself | All process definition operations are visualized, dragging tasks to draw DAGs, configuring data sources and resources. At the same time, for third-party systems, the api mode operation is provided. | Users on easyscheduler can achieve many-to-one or one-to-one mapping relationship through tenants and Hadoop users, which is very important for scheduling large data jobs. " Supports traditional shell tasks, while supporting large data platform task scheduling: MR, Spark, SQL (mysql, postgresql, hive, sparksql), Python, Procedure, Sub_Process | The scheduler uses distributed scheduling, and the overall scheduling capability will increase linearly with the scale of the cluster. Master and Worker support dynamic online and offline.
+Overload processing: Task queue mechanism, the number of schedulable tasks on a single machine can be flexibly configured, when too many tasks will be cached in the task queue, will not cause machine jam. | One-click deployment | Supports traditional shell tasks, and also support big data platform task scheduling: MR, Spark, SQL (mysql, postgresql, hive, sparksql), Python, Procedure, Sub_Process | |
+
+
+
+
+### System partial screenshot
+
+
+
+
+
+
+
+
+### Document
+
+- Backend deployment documentation
+
+- Front-end deployment documentation
+
+- [**User manual**](https://analysys.github.io/easyscheduler_docs_cn/系统使用手册.html?_blank "User manual")
+
+- [**Upgrade document**](https://analysys.github.io/easyscheduler_docs_cn/升级文档.html?_blank "Upgrade document")
+
+- Online Demo
+
+More documentation please refer to [EasyScheduler online documentation]
+
+### Recent R&D plan
+Work plan of Easy Scheduler: [R&D plan](https://github.com/analysys/EasyScheduler/projects/1), where `In Develop` card is the features of 1.1.0 version , TODO card is to be done (including feature ideas)
+
+### How to contribute code
+
+Welcome to participate in contributing code, please refer to the process of submitting the code:
+[[How to contribute code](https://github.com/analysys/EasyScheduler/issues/310)]
+
+### Thanks
+
+Easy Scheduler uses a lot of excellent open source projects, such as google guava, guice, grpc, netty, ali bonecp, quartz, and many open source projects of apache, etc.
+It is because of the shoulders of these open source projects that the birth of the Easy Scheduler is possible. We are very grateful for all the open source software used! We also hope that we will not only be the beneficiaries of open source, but also be open source contributors, so we decided to contribute to easy scheduling and promised long-term updates. We also hope that partners who have the same passion and conviction for open source will join in and contribute to open source!
+
+### Get Help
+The fastest way to get response from our developers is to submit issues, or add our wechat : 510570367
+
+### License
+Please refer to [LICENSE](https://github.com/analysys/EasyScheduler/blob/dev/LICENSE) file.
+
+
+
+
+
+
+
+
+
diff --git a/docs/en_US/System manual.md b/docs/en_US/System manual.md
index f4debf87a7..89a2a854db 100644
--- a/docs/en_US/System manual.md
+++ b/docs/en_US/System manual.md
@@ -20,8 +20,7 @@
- Task State Statistics: It refers to the statistics of the number of tasks to be run, failed, running, completed and succeeded in a given time frame.
- Process State Statistics: It refers to the statistics of the number of waiting, failing, running, completing and succeeding process instances in a specified time range.
- Process Definition Statistics: The process definition created by the user and the process definition granted by the administrator to the user are counted.
- - Queue statistics: Worker performs queue statistics, the number of tasks to be performed and the number of tasks to be killed
- - Command Status Statistics: Statistics of the Number of Commands Executed
+
### Creating Process definitions
- Go to the project home page, click "Process definitions" and enter the list page of process definition.
@@ -30,7 +29,7 @@
- Fill in the Node Name, Description, and Script fields.
- Selecting "task priority" will give priority to high-level tasks in the execution queue. Tasks with the same priority will be executed in the first-in-first-out order.
- Timeout alarm. Fill in "Overtime Time". When the task execution time exceeds the overtime, it can alarm and fail over time.
- - Fill in "Custom Parameters" and refer to [Custom Parameters](#用户自定义参数)
+ - Fill in "Custom Parameters" and refer to [Custom Parameters](#Custom Parameters)

@@ -57,15 +56,13 @@
- **The process definition of the off-line state can be edited, but not run**, so the on-line workflow is the first step.
> Click on the Process definition, return to the list of process definitions, click on the icon "online", online process definition.
- > Before offline process, it is necessary to offline timed management before offline process can be successfully defined.
- >
- >
+ > Before setting workflow offline, the timed tasks in timed management should be offline, so that the definition of workflow can be set offline successfully.
- Click "Run" to execute the process. Description of operation parameters:
- * Failure strategy:**When a task node fails to execute, other parallel task nodes need to execute the strategy**。”Continue "Representation: Other task nodes perform normally" and "End" Representation: Terminate all ongoing tasks and terminate the entire process.
+ * Failure strategy:**When a task node fails to execute, other parallel task nodes need to execute the strategy**。”Continue "Representation: Other task nodes perform normally", "End" Representation: Terminate all ongoing tasks and terminate the entire process.
* Notification strategy:When the process is over, send process execution information notification mail according to the process status.
- * Process priority: The priority of process running is divided into five levels:the highest , the high , the medium , the low , and the lowest . High-level processes are executed first in the execution queue, and processes with the same priority are executed first in first out order.
- * Worker group This process can only be executed in a specified machine group. Default, by default, can be executed on any worker.
+ * Process priority: The priority of process running is divided into five levels:the highest, the high, the medium, the low, and the lowest . High-level processes are executed first in the execution queue, and processes with the same priority are executed first in first out order.
+ * Worker group: This process can only be executed in a specified machine group. Default, by default, can be executed on any worker.
* Notification group: When the process ends or fault tolerance occurs, process information is sent to all members of the notification group by mail.
* Recipient: Enter the mailbox and press Enter key to save. When the process ends and fault tolerance occurs, an alert message is sent to the recipient list.
* Cc: Enter the mailbox and press Enter key to save. When the process is over and fault-tolerant occurs, alarm messages are copied to the copier list.
@@ -78,7 +75,7 @@
 -> SComplement execution mode includes serial execution and parallel execution. In serial mode, the complement will be executed sequentially from May 1 to May 10. In parallel mode, the tasks from May 1 to May 10 will be executed simultaneously.
+> Complement execution mode includes serial execution and parallel execution. In serial mode, the complement will be executed sequentially from May 1 to May 10. In parallel mode, the tasks from May 1 to May 10 will be executed simultaneously.
### Timing Process Definition
- Create Timing: "Process Definition - > Timing"
@@ -340,28 +337,28 @@ conf/common/hadoop.properties
-Create queues
+### Create queues
- Queues are used to execute spark, mapreduce and other programs, which require the use of "queue" parameters.
-- Security - > Queue Manage - > Creat Queue
+- "Security" - > "Queue Manage" - > "Creat Queue"
-> SComplement execution mode includes serial execution and parallel execution. In serial mode, the complement will be executed sequentially from May 1 to May 10. In parallel mode, the tasks from May 1 to May 10 will be executed simultaneously.
+> Complement execution mode includes serial execution and parallel execution. In serial mode, the complement will be executed sequentially from May 1 to May 10. In parallel mode, the tasks from May 1 to May 10 will be executed simultaneously.
### Timing Process Definition
- Create Timing: "Process Definition - > Timing"
@@ -340,28 +337,28 @@ conf/common/hadoop.properties
-Create queues
+### Create queues
- Queues are used to execute spark, mapreduce and other programs, which require the use of "queue" parameters.
-- Security - > Queue Manage - > Creat Queue
+- "Security" - > "Queue Manage" - > "Creat Queue"

### Create Tenants
- - The tenant corresponds to the user of Linux, which is used by the worker to submit jobs. If Linux does not have this user, the worker creates the user when executing the script.
- - Tenant Code:**the tenant code is the only user on Linux that can't be duplicated.**
+ - The tenant corresponds to the account of Linux, which is used by the worker server to submit jobs. If Linux does not have this user, the worker would create the account when executing the task.
+ - Tenant Code:**the tenant code is the only account on Linux that can't be duplicated.**

### Create Ordinary Users
- - Users are divided into **administrator users** and **ordinary users**.
- * Administrators have only **authorization and user management** privileges, and no privileges to **create project and process-defined operations**.
+ - User types are **ordinary users** and **administrator users**..
+ * Administrators have **authorization and user management** privileges, and no privileges to **create project and process-defined operations**.
* Ordinary users can **create projects and create, edit, and execute process definitions**.
* Note: **If the user switches the tenant, all resources under the tenant will be copied to the switched new tenant.**
@@ -376,8 +373,8 @@ Create queues
### Create Worker Group
- - Worker grouping provides a mechanism for tasks to run on a specified worker. Administrators set worker groups, and each task node can set worker groups for the task to run. If the task-specified groups are deleted or no groups are specified, the task will run on the worker specified by the process instance.
-- Multiple IP addresses within a worker group (**no aliases can be written**), separated by **commas in English**
+ - Worker group provides a mechanism for tasks to run on a specified worker. Administrators create worker groups, which can be specified in task nodes and operation parameters. If the specified grouping is deleted or no grouping is specified, the task will run on any worker.
+- Multiple IP addresses within a worker group (**aliases can not be written**), separated by **commas in English**
 @@ -454,8 +451,6 @@ Create queues
#### Worker monitor
- Mainly related information of worker.
-
-
@@ -454,8 +451,6 @@ Create queues
#### Worker monitor
- Mainly related information of worker.
-
-

@@ -495,7 +490,7 @@ Create queues
- Custom parameters: User-defined parameters that are part of SHELL replace the contents of scripts with ${variables}
### SUB_PROCESS
- - The sub-process node is to execute an external workflow definition as its own task node.
+ - The sub-process node is to execute an external workflow definition as an task node.
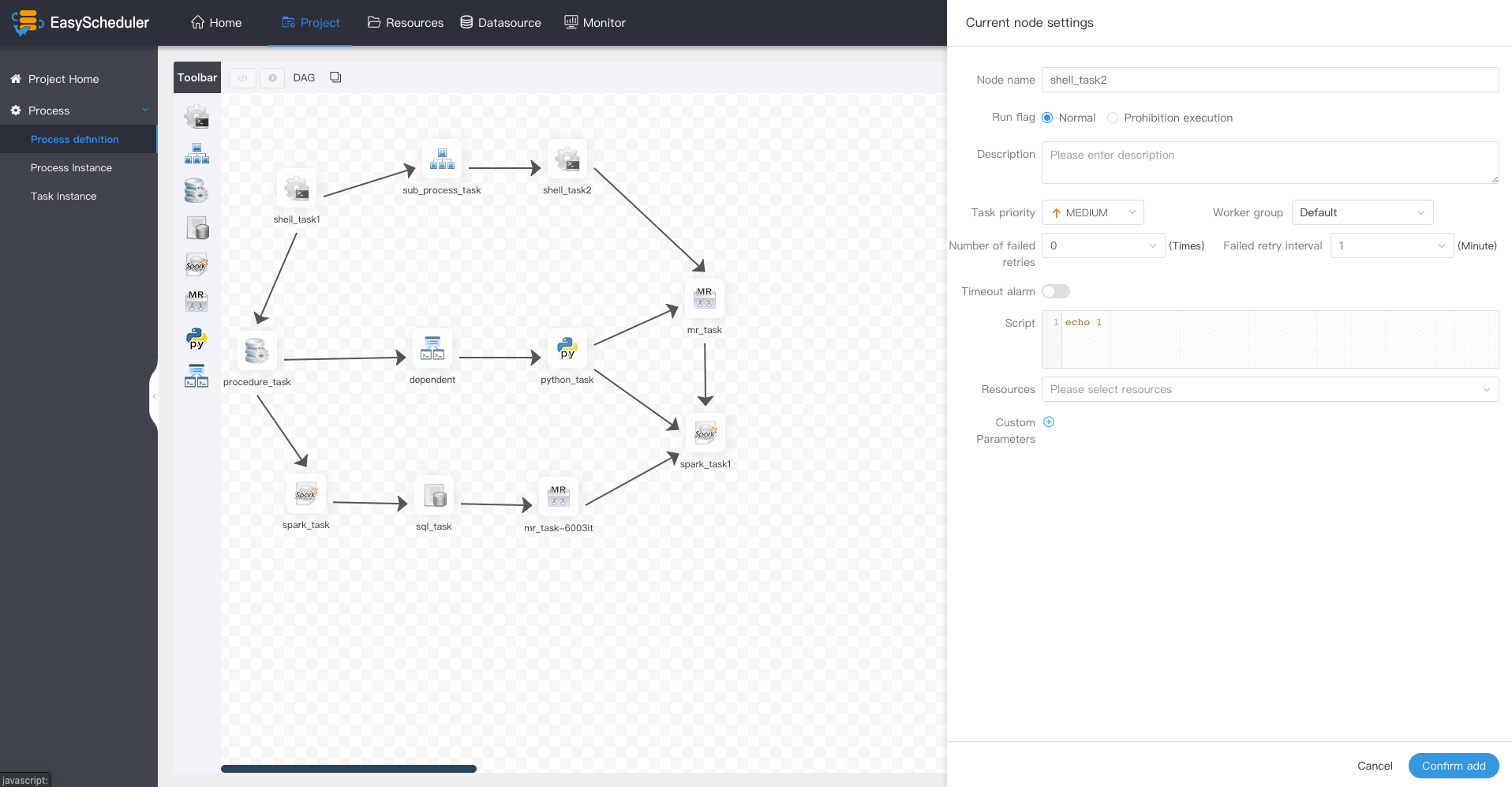
> Drag the  task node in the toolbar onto the palette and double-click the task node as follows:
diff --git a/docs/en_US/architecture-design.md b/docs/en_US/architecture-design.md
new file mode 100644
index 0000000000..f901fde3dc
--- /dev/null
+++ b/docs/en_US/architecture-design.md
@@ -0,0 +1,316 @@
+## Architecture Design
+Before explaining the architecture of the schedule system, let us first understand the common nouns of the schedule system.
+
+### 1.Noun Interpretation
+
+**DAG:** Full name Directed Acyclic Graph,referred to as DAG。Tasks in the workflow are assembled in the form of directed acyclic graphs, which are topologically traversed from nodes with zero indegrees of ingress until there are no successor nodes. For example, the following picture:
+
+
+  +
+
+ dag example
+
+
+
+**Process definition**: Visualization **DAG** by dragging task nodes and establishing associations of task nodes
+
+**Process instance**: A process instance is an instantiation of a process definition, which can be generated by manual startup or scheduling. The process definition runs once, a new process instance is generated
+
+**Task instance**: A task instance is the instantiation of a specific task node when a process instance runs, which indicates the specific task execution status
+
+**Task type**: Currently supports SHELL, SQL, SUB_PROCESS (sub-process), PROCEDURE, MR, SPARK, PYTHON, DEPENDENT (dependency), and plans to support dynamic plug-in extension, note: the sub-**SUB_PROCESS** is also A separate process definition that can be launched separately
+
+**Schedule mode** : The system supports timing schedule and manual schedule based on cron expressions. Command type support: start workflow, start execution from current node, resume fault-tolerant workflow, resume pause process, start execution from failed node, complement, timer, rerun, pause, stop, resume waiting thread. Where **recovers the fault-tolerant workflow** and **restores the waiting thread** The two command types are used by the scheduling internal control and cannot be called externally
+
+**Timed schedule**: The system uses **quartz** distributed scheduler and supports the generation of cron expression visualization
+
+**Dependency**: The system does not only support **DAG** Simple dependencies between predecessors and successor nodes, but also provides **task dependencies** nodes, support for custom task dependencies between processes**
+
+**Priority**: Supports the priority of process instances and task instances. If the process instance and task instance priority are not set, the default is first in, first out.
+
+**Mail Alert**: Support **SQL Task** Query Result Email Send, Process Instance Run Result Email Alert and Fault Tolerant Alert Notification
+
+**Failure policy**: For tasks running in parallel, if there are tasks that fail, two failure policy processing methods are provided. **Continue** means that the status of the task is run in parallel until the end of the process failure. **End** means that once a failed task is found, Kill also drops the running parallel task and the process ends.
+
+**Complement**: Complement historical data, support ** interval parallel and serial ** two complement methods
+
+
+
+### 2.System architecture
+
+#### 2.1 System Architecture Diagram
+
+  +
+
+ System Architecture Diagram
+
+
+
+
+
+#### 2.2 Architectural description
+
+* **MasterServer**
+
+ MasterServer adopts the distributed non-central design concept. MasterServer is mainly responsible for DAG task split, task submission monitoring, and monitoring the health status of other MasterServer and WorkerServer.
+ When the MasterServer service starts, it registers a temporary node with Zookeeper, and listens to the Zookeeper temporary node state change for fault tolerance processing.
+
+
+
+ ##### The service mainly contains:
+
+ - **Distributed Quartz** distributed scheduling component, mainly responsible for the start and stop operation of the scheduled task. When the quartz picks up the task, the master internally has a thread pool to be responsible for the subsequent operations of the task.
+
+ - **MasterSchedulerThread** is a scan thread that periodically scans the **command** table in the database for different business operations based on different ** command types**
+
+ - **MasterExecThread** is mainly responsible for DAG task segmentation, task submission monitoring, logic processing of various command types
+
+ - **MasterTaskExecThread** is mainly responsible for task persistence
+
+
+
+* **WorkerServer**
+
+ - WorkerServer also adopts a distributed, non-central design concept. WorkerServer is mainly responsible for task execution and providing log services. When the WorkerServer service starts, it registers the temporary node with Zookeeper and maintains the heartbeat.
+
+ ##### This service contains:
+
+ - **FetchTaskThread** is mainly responsible for continuously receiving tasks from **Task Queue** and calling **TaskScheduleThread** corresponding executors according to different task types.
+ - **LoggerServer** is an RPC service that provides functions such as log fragment viewing, refresh and download.
+
+ - **ZooKeeper**
+
+ The ZooKeeper service, the MasterServer and the WorkerServer nodes in the system all use the ZooKeeper for cluster management and fault tolerance. In addition, the system also performs event monitoring and distributed locking based on ZooKeeper.
+ We have also implemented queues based on Redis, but we hope that EasyScheduler relies on as few components as possible, so we finally removed the Redis implementation.
+
+ - **Task Queue**
+
+ The task queue operation is provided. Currently, the queue is also implemented based on Zookeeper. Since there is less information stored in the queue, there is no need to worry about too much data in the queue. In fact, we have over-measured a million-level data storage queue, which has no effect on system stability and performance.
+
+ - **Alert**
+
+ Provides alarm-related interfaces. The interfaces mainly include **Alarms**. The storage, query, and notification functions of the two types of alarm data. The notification function has two types: **mail notification** and **SNMP (not yet implemented)**.
+
+ - **API**
+
+ The API interface layer is mainly responsible for processing requests from the front-end UI layer. The service provides a RESTful api to provide request services externally.
+ Interfaces include workflow creation, definition, query, modification, release, offline, manual start, stop, pause, resume, start execution from this node, and more.
+
+ - **UI**
+
+ The front-end page of the system provides various visual operation interfaces of the system. For details, see the **[System User Manual] (System User Manual.md)** section.
+
+
+
+#### 2.3 Architectural Design Ideas
+
+##### I. Decentralized vs centralization
+
+###### Centralization Thought
+
+The centralized design concept is relatively simple. The nodes in the distributed cluster are divided into two roles according to their roles:
+
+
+  +
+
+
+- The role of Master is mainly responsible for task distribution and supervising the health status of Slave. It can dynamically balance the task to Slave, so that the Slave node will not be "busy" or "free".
+- The role of the Worker is mainly responsible for the execution of the task and maintains the heartbeat with the Master so that the Master can assign tasks to the Slave.
+
+Problems in the design of centralized :
+
+- Once the Master has a problem, the group has no leader and the entire cluster will crash. In order to solve this problem, most Master/Slave architecture modes adopt the design scheme of the master and backup masters, which can be hot standby or cold standby, automatic switching or manual switching, and more and more new systems are available. Automatically elects the ability to switch masters to improve system availability.
+- Another problem is that if the Scheduler is on the Master, although it can support different tasks in one DAG running on different machines, it will generate overload of the Master. If the Scheduler is on the Slave, all tasks in a DAG can only be submitted on one machine. If there are more parallel tasks, the pressure on the Slave may be larger.
+
+###### Decentralization
+
+
+
+
+- In the decentralized design, there is usually no Master/Slave concept, all roles are the same, the status is equal, the global Internet is a typical decentralized distributed system, networked arbitrary node equipment down machine , all will only affect a small range of features.
+- The core design of decentralized design is that there is no "manager" that is different from other nodes in the entire distributed system, so there is no single point of failure problem. However, since there is no "manager" node, each node needs to communicate with other nodes to get the necessary machine information, and the unreliable line of distributed system communication greatly increases the difficulty of implementing the above functions.
+- In fact, truly decentralized distributed systems are rare. Instead, dynamic centralized distributed systems are constantly emerging. Under this architecture, the managers in the cluster are dynamically selected, rather than preset, and when the cluster fails, the nodes of the cluster will spontaneously hold "meetings" to elect new "managers". Go to preside over the work. The most typical case is the Etcd implemented in ZooKeeper and Go.
+
+- Decentralization of EasyScheduler is the registration of Master/Worker to ZooKeeper. The Master Cluster and the Worker Cluster are not centered, and the Zookeeper distributed lock is used to elect one Master or Worker as the “manager” to perform the task.
+
+##### 二、Distributed lock practice
+
+EasyScheduler uses ZooKeeper distributed locks to implement only one Master to execute the Scheduler at the same time, or only one Worker to perform task submission.
+
+1. The core process algorithm for obtaining distributed locks is as follows
+
+
+  +
+
+
+2. Scheduler thread distributed lock implementation flow chart in EasyScheduler:
+
+
+  +
+
+
+##### Third, the thread is insufficient loop waiting problem
+
+- If there is no subprocess in a DAG, if the number of data in the Command is greater than the threshold set by the thread pool, the direct process waits or fails.
+- If a large number of sub-processes are nested in a large DAG, the following figure will result in a "dead" state:
+
+
+  +
+
+
+In the above figure, MainFlowThread waits for SubFlowThread1 to end, SubFlowThread1 waits for SubFlowThread2 to end, SubFlowThread2 waits for SubFlowThread3 to end, and SubFlowThread3 waits for a new thread in the thread pool, then the entire DAG process cannot end, and thus the thread cannot be released. This forms the state of the child parent process loop waiting. At this point, the scheduling cluster will no longer be available unless a new Master is started to add threads to break such a "stuck."
+
+It seems a bit unsatisfactory to start a new Master to break the deadlock, so we proposed the following three options to reduce this risk:
+
+1. Calculate the sum of the threads of all Masters, and then calculate the number of threads required for each DAG, that is, pre-calculate before the DAG process is executed. Because it is a multi-master thread pool, the total number of threads is unlikely to be obtained in real time.
+2. Judge the single master thread pool. If the thread pool is full, let the thread fail directly.
+3. Add a Command type with insufficient resources. If the thread pool is insufficient, the main process will be suspended. This way, the thread pool has a new thread, which can make the process with insufficient resources hang up and wake up again.
+
+Note: The Master Scheduler thread is FIFO-enabled when it gets the Command.
+
+So we chose the third way to solve the problem of insufficient threads.
+
+##### IV. Fault Tolerant Design
+
+Fault tolerance is divided into service fault tolerance and task retry. Service fault tolerance is divided into two types: Master Fault Tolerance and Worker Fault Tolerance.
+
+###### 1. Downtime fault tolerance
+
+Service fault tolerance design relies on ZooKeeper's Watcher mechanism. The implementation principle is as follows:
+
+
+  +
+
+
+The Master monitors the directories of other Masters and Workers. If the remove event is detected, the process instance is fault-tolerant or the task instance is fault-tolerant according to the specific business logic.
+
+
+
+- Master fault tolerance flow chart:
+
+
+  +
+
+
+After the ZooKeeper Master is fault-tolerant, it is rescheduled by the Scheduler thread in EasyScheduler. It traverses the DAG to find the "Running" and "Submit Successful" tasks, and monitors the status of its task instance for the "Running" task. You need to determine whether the Task Queue already exists. If it exists, monitor the status of the task instance. If it does not exist, resubmit the task instance.
+
+
+
+- Worker fault tolerance flow chart:
+
+
+  +
+
+
+Once the Master Scheduler thread finds the task instance as "need to be fault tolerant", it takes over the task and resubmits.
+
+ Note: Because the "network jitter" may cause the node to lose the heartbeat of ZooKeeper in a short time, the node's remove event occurs. In this case, we use the easiest way, that is, once the node has timeout connection with ZooKeeper, it will directly stop the Master or Worker service.
+
+###### 2. Task failure retry
+
+Here we must first distinguish between the concept of task failure retry, process failure recovery, and process failure rerun:
+
+- Task failure Retry is task level, which is automatically performed by the scheduling system. For example, if a shell task sets the number of retries to 3 times, then the shell task will try to run up to 3 times after failing to run.
+- Process failure recovery is process level, is done manually, recovery can only be performed from the failed node ** or ** from the current node **
+- Process failure rerun is also process level, is done manually, rerun is from the start node
+
+
+
+Next, let's talk about the topic, we divided the task nodes in the workflow into two types.
+
+- One is a business node, which corresponds to an actual script or processing statement, such as a Shell node, an MR node, a Spark node, a dependent node, and so on.
+- There is also a logical node, which does not do the actual script or statement processing, but the logical processing of the entire process flow, such as sub-flow sections.
+
+Each ** service node** can configure the number of failed retries. When the task node fails, it will automatically retry until it succeeds or exceeds the configured number of retries. **Logical node** does not support failed retry. But the tasks in the logical nodes support retry.
+
+If there is a task failure in the workflow that reaches the maximum number of retries, the workflow will fail to stop, and the failed workflow can be manually rerun or process resumed.
+
+
+
+##### V. Task priority design
+
+In the early scheduling design, if there is no priority design and fair scheduling design, it will encounter the situation that the task submitted first may be completed simultaneously with the task submitted subsequently, but the priority of the process or task cannot be set. We have redesigned this, and we are currently designing it as follows:
+
+- According to ** different process instance priority ** prioritizes ** same process instance priority ** prioritizes ** task priority within the same process ** takes precedence over ** same process ** commit order from high Go to low for task processing.
+
+ - The specific implementation is to resolve the priority according to the json of the task instance, and then save the ** process instance priority _ process instance id_task priority _ task id** information in the ZooKeeper task queue, when obtained from the task queue, Through string comparison, you can get the task that needs to be executed first.
+
+ - The priority of the process definition is that some processes need to be processed before other processes. This can be configured at the start of the process or at the time of scheduled start. There are 5 levels, followed by HIGHEST, HIGH, MEDIUM, LOW, and LOWEST. As shown below
+
+
+  +
+
+
+ - The priority of the task is also divided into 5 levels, followed by HIGHEST, HIGH, MEDIUM, LOW, and LOWEST. As shown below
+
+
+  +
+
+
+##### VI. Logback and gRPC implement log access
+
+- Since the Web (UI) and Worker are not necessarily on the same machine, viewing the log is not as it is for querying local files. There are two options:
+ - Put the logs on the ES search engine
+ - Obtain remote log information through gRPC communication
+- Considering the lightweightness of EasyScheduler as much as possible, gRPC was chosen to implement remote access log information.
+
+
+  +
+
+
+- We use a custom Logback FileAppender and Filter function to generate a log file for each task instance.
+- The main implementation of FileAppender is as follows:
+
+```java
+ /**
+ * task log appender
+ */
+ Public class TaskLogAppender extends FileAppender
-> 项目首页其中包含任务状态统计,流程状态统计、流程定义统计、队列统计、命令统计
+> 项目首页其中包含任务状态统计,流程状态统计、流程定义统计
- 任务状态统计:是指在指定时间范围内,统计任务实例中的待运行、失败、运行中、完成、成功的个数
- 流程状态统计:是指在指定时间范围内,统计流程实例中的待运行、失败、运行中、完成、成功的个数
- 流程定义统计:是统计该用户创建的流程定义及管理员授予该用户的流程定义
- - 队列统计: worker执行队列统计,待执行的任务和待杀掉的任务个数
- - 命令统计: 执行命令个数统计
+
### 创建工作流定义
- 进入项目首页,点击“工作流定义”,进入流程定义列表页。
@@ -46,7 +45,7 @@
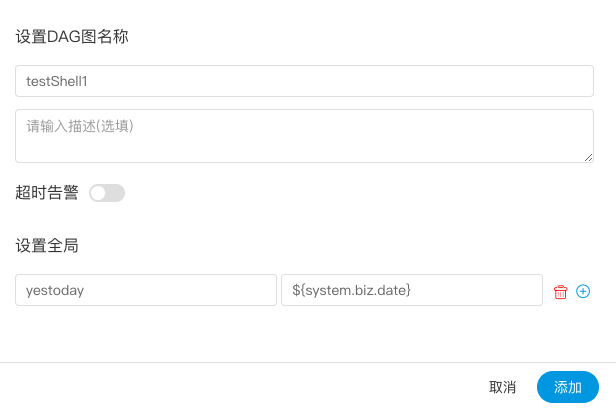
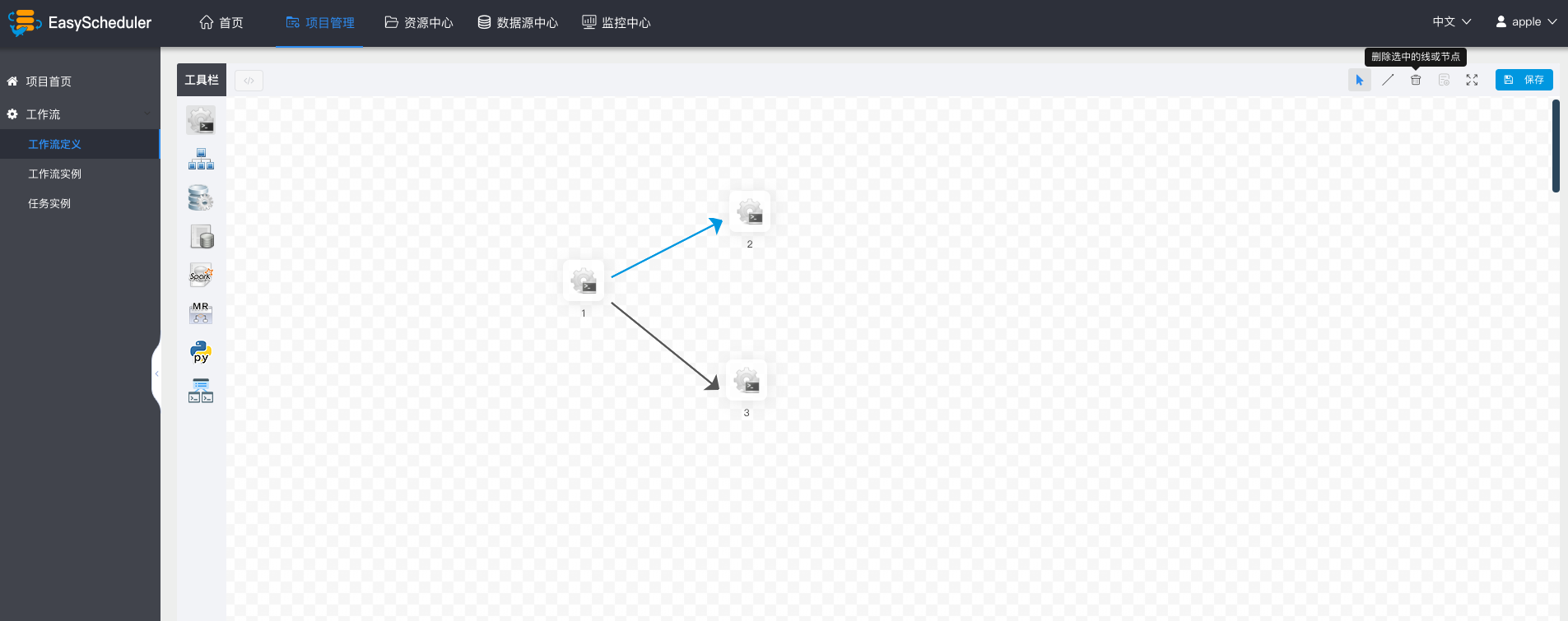 - - 点击”保存“,输入流程定义名称,流程定义描述,设置全局参数。
+ - 点击”保存“,输入流程定义名称,流程定义描述,设置全局参数,参考[自定义参数](#用户自定义参数)。
- - 点击”保存“,输入流程定义名称,流程定义描述,设置全局参数。
+ - 点击”保存“,输入流程定义名称,流程定义描述,设置全局参数,参考[自定义参数](#用户自定义参数)。
 @@ -58,7 +57,7 @@
- **未上线状态的流程定义可以编辑,但是不可以运行**,所以先上线工作流
> 点击工作流定义,返回流程定义列表,点击”上线“图标,上线工作流定义。
- > "下线"工作流之前,要先将定时管理的定时下线,才能成功下线工作流定义
+ > 下线工作流定义的时候,要先将定时管理中的定时任务下线,这样才能成功下线工作流定义
- 点击”运行“,执行工作流。运行参数说明:
* 失败策略:**当某一个任务节点执行失败时,其他并行的任务节点需要执行的策略**。”继续“表示:其他任务节点正常执行,”结束“表示:终止所有正在执行的任务,并终止整个流程。
@@ -344,7 +343,7 @@ conf/common/hadoop.properties
### 创建普通用户
- 用户分为**管理员用户**和**普通用户**
- * 管理员只有**授权和用户管理**等权限,没有**创建项目和流程定义**的操作的权限
+ * 管理员有**授权和用户管理**等权限,没有**创建项目和流程定义**的操作的权限
* 普通用户可以**创建项目和对流程定义的创建,编辑,执行**等操作。
* 注意:**如果该用户切换了租户,则该用户所在租户下所有资源将复制到切换的新租户下**
@@ -58,7 +57,7 @@
- **未上线状态的流程定义可以编辑,但是不可以运行**,所以先上线工作流
> 点击工作流定义,返回流程定义列表,点击”上线“图标,上线工作流定义。
- > "下线"工作流之前,要先将定时管理的定时下线,才能成功下线工作流定义
+ > 下线工作流定义的时候,要先将定时管理中的定时任务下线,这样才能成功下线工作流定义
- 点击”运行“,执行工作流。运行参数说明:
* 失败策略:**当某一个任务节点执行失败时,其他并行的任务节点需要执行的策略**。”继续“表示:其他任务节点正常执行,”结束“表示:终止所有正在执行的任务,并终止整个流程。
@@ -344,7 +343,7 @@ conf/common/hadoop.properties
### 创建普通用户
- 用户分为**管理员用户**和**普通用户**
- * 管理员只有**授权和用户管理**等权限,没有**创建项目和流程定义**的操作的权限
+ * 管理员有**授权和用户管理**等权限,没有**创建项目和流程定义**的操作的权限
* 普通用户可以**创建项目和对流程定义的创建,编辑,执行**等操作。
* 注意:**如果该用户切换了租户,则该用户所在租户下所有资源将复制到切换的新租户下**
@@ -360,7 +359,7 @@ conf/common/hadoop.properties
### 创建worker分组
- - worker分组,提供了一种让任务在指定的worker上运行的机制。管理员设置worker分组,每个任务节点可以设置该任务运行的worker分组,如果任务指定的分组被删除或者没有指定分组,则该任务会在流程实例指定的worker上运行。
+ - worker分组,提供了一种让任务在指定的worker上运行的机制。管理员创建worker分组,在任务节点和运行参数中设置中可以指定该任务运行的worker分组,如果指定的分组被删除或者没有指定分组,则该任务会在任一worker上运行。
- worker分组内多个ip地址(**不能写别名**),以**英文逗号**分隔
@@ -476,7 +475,7 @@ conf/common/hadoop.properties
- 自定义参数:是SHELL局部的用户自定义参数,会替换脚本中以${变量}的内容
### 子流程节点
- - 子流程节点,就是把外部的某个工作流定义当做自己的一个任务节点去执行。
+ - 子流程节点,就是把外部的某个工作流定义当做一个任务节点去执行。
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
diff --git a/escheduler-common/src/main/java/cn/escheduler/common/zk/AbstractZKClient.java b/escheduler-common/src/main/java/cn/escheduler/common/zk/AbstractZKClient.java
index 4a7e42bee8..b0a8fa03da 100644
--- a/escheduler-common/src/main/java/cn/escheduler/common/zk/AbstractZKClient.java
+++ b/escheduler-common/src/main/java/cn/escheduler/common/zk/AbstractZKClient.java
@@ -246,8 +246,9 @@ public abstract class AbstractZKClient {
return registerPath;
}
registerPath = createZNodePath(ZKNodeType.MASTER);
+ logger.info("register {} node {} success", zkNodeType.toString(), registerPath);
- // handle dead server
+ // handle dead server
handleDeadServer(registerPath, zkNodeType, Constants.DELETE_ZK_OP);
return registerPath;
diff --git a/escheduler-server/src/main/java/cn/escheduler/server/master/MasterServer.java b/escheduler-server/src/main/java/cn/escheduler/server/master/MasterServer.java
index 562b6509e5..457302359c 100644
--- a/escheduler-server/src/main/java/cn/escheduler/server/master/MasterServer.java
+++ b/escheduler-server/src/main/java/cn/escheduler/server/master/MasterServer.java
@@ -215,7 +215,7 @@ public class MasterServer implements CommandLineRunner, IStoppable {
if(Stopper.isRunning()) {
// send heartbeat to zk
if (StringUtils.isBlank(zkMasterClient.getMasterZNode())) {
- logger.error("master send heartbeat to zk failed: can't find zookeeper regist path of master server");
+ logger.error("master send heartbeat to zk failed: can't find zookeeper path of master server");
return;
}
diff --git a/escheduler-server/src/main/java/cn/escheduler/server/zk/ZKMasterClient.java b/escheduler-server/src/main/java/cn/escheduler/server/zk/ZKMasterClient.java
index 0fa80ffb2a..f4cec7303f 100644
--- a/escheduler-server/src/main/java/cn/escheduler/server/zk/ZKMasterClient.java
+++ b/escheduler-server/src/main/java/cn/escheduler/server/zk/ZKMasterClient.java
@@ -170,6 +170,7 @@ public class ZKMasterClient extends AbstractZKClient {
if(StringUtils.isEmpty(serverPath)){
System.exit(-1);
}
+ masterZNode = serverPath;
} catch (Exception e) {
logger.error("register master failure : " + e.getMessage(),e);
System.exit(-1);
diff --git a/escheduler-server/src/main/java/cn/escheduler/server/zk/ZKWorkerClient.java b/escheduler-server/src/main/java/cn/escheduler/server/zk/ZKWorkerClient.java
index 2718725eba..f97d959653 100644
--- a/escheduler-server/src/main/java/cn/escheduler/server/zk/ZKWorkerClient.java
+++ b/escheduler-server/src/main/java/cn/escheduler/server/zk/ZKWorkerClient.java
@@ -100,7 +100,6 @@ public class ZKWorkerClient extends AbstractZKClient {
if(zkWorkerClient == null){
zkWorkerClient = new ZKWorkerClient();
}
-
return zkWorkerClient;
}
@@ -112,19 +111,6 @@ public class ZKWorkerClient extends AbstractZKClient {
return serverDao;
}
-
- public String initWorkZNode() throws Exception {
-
- String heartbeatZKInfo = ResInfo.getHeartBeatInfo(new Date());
-
- workerZNode = getZNodeParentPath(ZKNodeType.WORKER) + "/" + OSUtils.getHost() + "_";
-
- workerZNode = zkClient.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(workerZNode,
- heartbeatZKInfo.getBytes());
- logger.info("register worker node {} success", workerZNode);
- return workerZNode;
- }
-
/**
* register worker
*/
@@ -134,6 +120,7 @@ public class ZKWorkerClient extends AbstractZKClient {
if(StringUtils.isEmpty(serverPath)){
System.exit(-1);
}
+ workerZNode = serverPath;
} catch (Exception e) {
logger.error("register worker failure : " + e.getMessage(),e);
System.exit(-1);
diff --git a/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/start.vue b/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/start.vue
index c2e3c33728..463bf3fc1a 100644
--- a/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/start.vue
+++ b/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/start.vue
@@ -51,7 +51,7 @@
- Worker分组
+ {{$t('Worker group')}}
diff --git a/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/timing.vue b/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/timing.vue
index 42bb7905a0..5262aac9fa 100644
--- a/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/timing.vue
+++ b/escheduler-ui/src/js/conf/home/pages/projects/pages/definition/pages/list/_source/timing.vue
@@ -21,7 +21,7 @@
-
执行时间
+
{{$t('Execute time')}}
{{$t('Timing')}}
@@ -46,7 +46,7 @@
-
未来五次执行时间
+
{{$t('Next five execution times')}}
@@ -90,7 +90,7 @@
- Worker分组
+ {{$t('Worker group')}}
diff --git a/escheduler-ui/src/js/module/i18n/locale/en_US.js b/escheduler-ui/src/js/module/i18n/locale/en_US.js
index 79d66cf147..cea14afc1a 100644
--- a/escheduler-ui/src/js/module/i18n/locale/en_US.js
+++ b/escheduler-ui/src/js/module/i18n/locale/en_US.js
@@ -471,5 +471,7 @@ export default {
'Startup parameter': 'Startup parameter',
'Startup type': 'Startup type',
'warning of timeout': 'warning of timeout',
+ 'Next five execution times': 'Next five execution times',
+ 'Execute time': 'Execute time',
'Complement range': 'Complement range'
}
diff --git a/escheduler-ui/src/js/module/i18n/locale/zh_CN.js b/escheduler-ui/src/js/module/i18n/locale/zh_CN.js
index 93d145bc8b..5e82ac63e9 100644
--- a/escheduler-ui/src/js/module/i18n/locale/zh_CN.js
+++ b/escheduler-ui/src/js/module/i18n/locale/zh_CN.js
@@ -472,5 +472,7 @@ export default {
'Startup parameter': '启动参数',
'Startup type': '启动类型',
'warning of timeout': '超时告警',
+ 'Next five execution times': '接下来五次执行时间',
+ 'Execute time': '执行时间',
'Complement range': '补数范围'
}